 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: A Dataset for Compositional Language and Elementary Acoustic Reasoning
Paper and Code

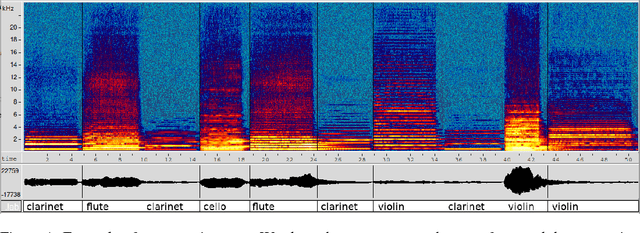


We introduce the task of acoustic question answering (AQA) in the area of acoustic reasoning. In this task an agent learns to answer questions on the basis of acoustic context. In order to promote research in this area, we propose a data generation paradigm adapted from CLEVR (Johnson et al. 2017). We generate acoustic scenes by leveraging a bank elementary sounds. We also provide a number of functional programs that can be used to compose questions and answers that exploit the relationships between the attributes of the elementary sounds in each scene. We provide AQA datasets of various sizes as well as the data generation code. As a preliminary experiment to validate our data, we report the accuracy of current state of the art visual question answering models when they are applied to the AQA task without modifications. Although there is a plethora of question answering tasks based on text, image or video data, to our knowledge, we are the first to propose answering questions directly on audio streams. We hope this contribution will facilitate the development of research in the area.