 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamVTON: Customizing 3D Virtual Try-on with Personalized Diffusion Models
Jul 23, 2024



Image-based 3D Virtual Try-ON (VTON) aims to sculpt the 3D human according to person and clothes images, which is data-efficient (i.e., getting rid of expensive 3D data) but challenging. Recent text-to-3D methods achieve remarkable improvement in high-fidelity 3D human generation, demonstrating its potential for 3D virtual try-on. Inspired by the impressive success of personalized diffusion models (e.g., Dreambooth and LoRA) for 2D VTON, it is straightforward to achieve 3D VTON by integrating the personalization technique into the diffusion-based text-to-3D framework. However, employing the personalized module in a pre-trained diffusion model (e.g., StableDiffusion (SD)) would degrade the model's capability for multi-view or multi-domain synthesis, which is detrimental to the geometry and texture optimization guided by Score Distillation Sampling (SDS) loss. In this work, we propose a novel customizing 3D human try-on model, named \textbf{DreamVTON}, to separately optimize the geometry and texture of the 3D human. Specifically, a personalized SD with multi-concept LoRA is proposed to provide the generative prior about the specific person and clothes, while a Densepose-guided ControlNet is exploited to guarantee consistent prior about body pose across various camera views. Besides, to avoid the inconsistent multi-view priors from the personalized SD dominating the optimization, DreamVTON introduces a template-based optimization mechanism, which employs mask templates for geometry shape learning and normal/RGB templates for geometry/texture details learning. Furthermore, for the geometry optimization phase, DreamVTON integrates a normal-style LoRA into personalized SD to enhance normal map generative prior, facilitating smooth geometry modeling.
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
Jul 21, 2024



Virtual try-on methods based on diffusion models achieve realistic try-on effects but often replicate the backbone network as a ReferenceNet or use additional image encoders to process condition inputs, leading to high training and inference costs. In this work, we rethink the necessity of ReferenceNet and image encoders and innovate the interaction between garment and person by proposing CatVTON, a simple and efficient virtual try-on diffusion model. CatVTON facilitates the seamless transfer of in-shop or worn garments of any category to target persons by simply concatenating them in spatial dimensions as inputs. The efficiency of our model is demonstrated in three aspects: (1) Lightweight network: Only the original diffusion modules are used, without additional network modules. The text encoder and cross-attentions for text injection in the backbone are removed, reducing the parameters by 167.02M. (2) Parameter-efficient training: We identified the try-on relevant modules through experiments and achieved high-quality try-on effects by training only 49.57M parameters, approximately 5.51 percent of the backbone network's parameters. (3) Simplified inference: CatVTON eliminates all unnecessary conditions and preprocessing steps, including pose estimation, human parsing, and text input, requiring only a garment reference, target person image, and mask for the virtual try-on process. Extensive experiments demonstrate that CatVTON achieves superior qualitative and quantitative results with fewer prerequisites and trainable parameters than baseline methods. Furthermore, CatVTON shows good generalization in in-the-wild scenarios despite using open-source datasets with only 73K samples.
Contrastive Learning with Counterfactual Explanations for Radiology Report Generation
Jul 19, 2024



Due to the common content of anatomy, radiology images with their corresponding reports exhibit high similarity. Such inherent data bias can predispose automatic report generation models to learn entangled and spurious representations resulting in misdiagnostic reports. To tackle these, we propose a novel \textbf{Co}unter\textbf{F}actual \textbf{E}xplanations-based framework (CoFE) for radiology report generation. Counterfactual explanations serve as a potent tool for understanding how decisions made by algorithms can be changed by asking ``what if'' scenarios. By leveraging this concept, CoFE can learn non-spurious visual representations by contrasting the representations between factual and counterfactual images. Specifically, we derive counterfactual images by swapping a patch between positive and negative samples until a predicted diagnosis shift occurs. Here, positive and negative samples are the most semantically similar but have different diagnosis labels. Additionally, CoFE employs a learnable prompt to efficiently fine-tune the pre-trained large language model, encapsulating both factual and counterfactual content to provide a more generalizable prompt representation. Extensive experiments on two benchmarks demonstrate that leveraging the counterfactual explanations enables CoFE to generate semantically coherent and factually complete reports and outperform in terms of language generation and clinical efficacy metrics.
Benchmarking LLMs for Optimization Modeling and Enhancing Reasoning via Reverse Socratic Synthesis
Jul 13, 2024



Large language models (LLMs) have exhibited their problem-solving ability in mathematical reasoning. Solving realistic optimization (OPT) problems in industrial application scenarios requires advanced and applied math ability. However, current OPT benchmarks that merely solve linear programming are far from complex realistic situations. In this work, we propose E-OPT, a benchmark for end-to-end optimization problem-solving with human-readable inputs and outputs. E-OPT contains rich optimization problems, including linear/nonlinear programming with/without table data, which can comprehensively evaluate LLMs' solving ability. In our benchmark, LLMs are required to correctly understand the problem in E-OPT and call code solver to get precise numerical answers. Furthermore, to alleviate the data scarcity for optimization problems, and to bridge the gap between open-source LLMs on a small scale (e.g., Llama-2-7b and Llama-3-8b) and closed-source LLMs (e.g., GPT-4), we further propose a novel data synthesis method namely ReSocratic. Unlike general data synthesis methods that proceed from questions to answers, ReSocratic first incrementally synthesizes optimization scenarios with mathematical formulations step by step and then back-translates the generated scenarios into questions. In such a way, we construct the ReSocratic-29k dataset from a small seed sample pool with the powerful open-source large model DeepSeek-V2. To demonstrate the effectiveness of ReSocratic, we conduct supervised fine-tuning with ReSocratic-29k on multiple open-source models. The results show that Llama3-8b is significantly improved from 13.6% to 51.7% on E-OPT, while DeepSeek-V2 reaches 61.0%, approaching 65.5% of GPT-4.
HiRes-LLaVA: Restoring Fragmentation Input in High-Resolution Large Vision-Language Models
Jul 11, 2024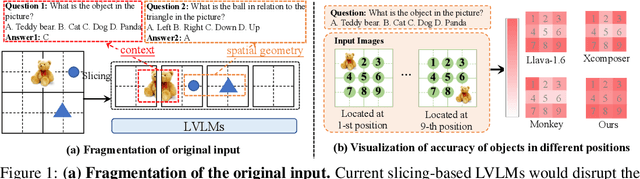
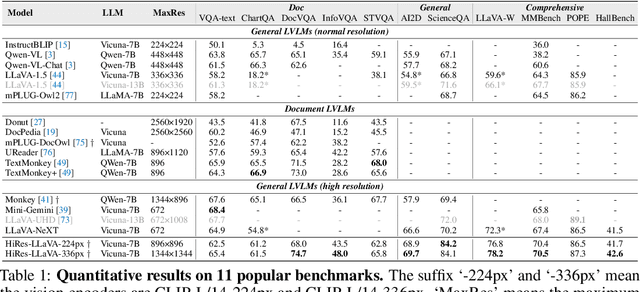
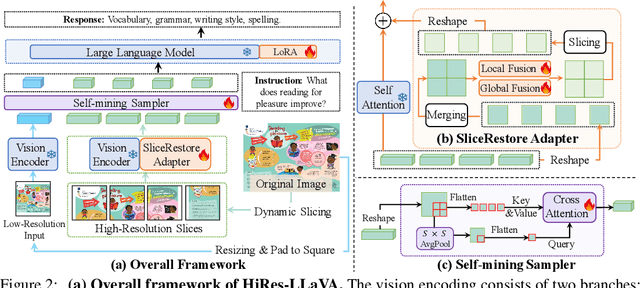

High-resolution inputs enable Large Vision-Language Models (LVLMs) to discern finer visual details, enhancing their comprehension capabilities. To reduce the training and computation costs caused by high-resolution input, one promising direction is to use sliding windows to slice the input into uniform patches, each matching the input size of the well-trained vision encoder. Although efficient, this slicing strategy leads to the fragmentation of original input, i.e., the continuity of contextual information and spatial geometry is lost across patches, adversely affecting performance in cross-patch context perception and position-specific tasks. To overcome these shortcomings, we introduce HiRes-LLaVA, a novel framework designed to efficiently process any size of high-resolution input without altering the original contextual and geometric information. HiRes-LLaVA comprises two innovative components: (i) a SliceRestore adapter that reconstructs sliced patches into their original form, efficiently extracting both global and local features via down-up-sampling and convolution layers, and (ii) a Self-Mining Sampler to compresses the vision tokens based on themselves, preserving the original context and positional information while reducing training overhead. To assess the ability of handling context fragmentation, we construct a new benchmark, EntityGrid-QA, consisting of edge-related and position-related tasks. Our comprehensive experiments demonstrate the superiority of HiRes-LLaVA on both existing public benchmarks and on EntityGrid-QA, particularly on document-oriented tasks, establishing new standards for handling high-resolution inputs.
OV-DINO: Unified Open-Vocabulary Detection with Language-Aware Selective Fusion
Jul 10, 2024



Open-vocabulary detection is a challenging task due to the requirement of detecting objects based on class names, including those not encountered during training. Existing methods have shown strong zero-shot detection capabilities through pre-training on diverse large-scale datasets. However, these approaches still face two primary challenges: (i) how to universally integrate diverse data sources for end-to-end training, and (ii) how to effectively leverage the language-aware capability for region-level cross-modality understanding. To address these challenges, we propose a novel unified open-vocabulary detection method called OV-DINO, which pre-trains on diverse large-scale datasets with language-aware selective fusion in a unified framework. Specifically, we introduce a Unified Data Integration (UniDI) pipeline to enable end-to-end training and eliminate noise from pseudo-label generation by unifying different data sources into detection-centric data. In addition, we propose a Language-Aware Selective Fusion (LASF) module to enable the language-aware ability of the model through a language-aware query selection and fusion process. We evaluate the performance of the proposed OV-DINO on popular open-vocabulary detection benchmark datasets, achieving state-of-the-art results with an AP of 50.6\% on the COCO dataset and 40.0\% on the LVIS dataset in a zero-shot manner, demonstrating its strong generalization ability. Furthermore, the fine-tuned OV-DINO on COCO achieves 58.4\% AP, outperforming many existing methods with the same backbone. The code for OV-DINO will be available at \href{https://github.com/wanghao9610/OV-DINO}{https://github.com/wanghao9610/OV-DINO}.
HumanRefiner: Benchmarking Abnormal Human Generation and Refining with Coarse-to-fine Pose-Reversible Guidance
Jul 09, 2024



Text-to-image diffusion models have significantly advanced in conditional image generation. However, these models usually struggle with accurately rendering images featuring humans, resulting in distorted limbs and other anomalies. This issue primarily stems from the insufficient recognition and evaluation of limb qualities in diffusion models. To address this issue, we introduce AbHuman, the first large-scale synthesized human benchmark focusing on anatomical anomalies. This benchmark consists of 56K synthesized human images, each annotated with detailed, bounding-box level labels identifying 147K human anomalies in 18 different categories. Based on this, the recognition of human anomalies can be established, which in turn enhances image generation through traditional techniques such as negative prompting and guidance. To further boost the improvement, we propose HumanRefiner, a novel plug-and-play approach for the coarse-to-fine refinement of human anomalies in text-to-image generation. Specifically, HumanRefiner utilizes a self-diagnostic procedure to detect and correct issues related to both coarse-grained abnormal human poses and fine-grained anomaly levels, facilitating pose-reversible diffusion generation. Experimental results on the AbHuman benchmark demonstrate that HumanRefiner significantly reduces generative discrepancies, achieving a 2.9x improvement in limb quality compared to the state-of-the-art open-source generator SDXL and a 1.4x improvement over DALL-E 3 in human evaluations. Our data and code are available at https://github.com/Enderfga/HumanRefiner.
Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
Jul 08, 2024



LLM-based agents have demonstrated impressive zero-shot performance in the vision-language navigation (VLN) task. However, these zero-shot methods focus only on solving high-level task planning by selecting nodes in predefined navigation graphs for movements, overlooking low-level control in realistic navigation scenarios. To bridge this gap, we propose AO-Planner, a novel affordances-oriented planning framework for continuous VLN task. Our AO-Planner integrates various foundation models to achieve affordances-oriented motion planning and action decision-making, both performed in a zero-shot manner. Specifically, we employ a visual affordances prompting (VAP) approach, where visible ground is segmented utilizing SAM to provide navigational affordances, based on which the LLM selects potential next waypoints and generates low-level path planning towards selected waypoints. We further introduce a high-level agent, PathAgent, to identify the most probable pixel-based path and convert it into 3D coordinates to fulfill low-level motion. Experimental results on the challenging R2R-CE benchmark demonstrate that AO-Planner achieves state-of-the-art zero-shot performance (5.5% improvement in SPL). Our method establishes an effective connection between LLM and 3D world to circumvent the difficulty of directly predicting world coordinates, presenting novel prospects for employing foundation models in low-level motion control.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
FVEL: Interactive Formal Verification Environment with Large Language Models via Theorem Proving
Jun 20, 2024



Formal verification (FV) has witnessed growing significance with current emerging program synthesis by the evolving large language models (LLMs). However, current formal verification mainly resorts to symbolic verifiers or hand-craft rules, resulting in limitations for extensive and flexible verification. On the other hand, formal languages for automated theorem proving, such as Isabelle, as another line of rigorous verification, are maintained with comprehensive rules and theorems. In this paper, we propose FVEL, an interactive Formal Verification Environment with LLMs. Specifically, FVEL transforms a given code to be verified into Isabelle, and then conducts verification via neural automated theorem proving with an LLM. The joined paradigm leverages the rigorous yet abundant formulated and organized rules in Isabelle and is also convenient for introducing and adjusting cutting-edge LLMs. To achieve this goal, we extract a large-scale FVELER3. The FVELER dataset includes code dependencies and verification processes that are formulated in Isabelle, containing 758 theories, 29,125 lemmas, and 200,646 proof steps in total with in-depth dependencies. We benchmark FVELER in the FVEL environment by first fine-tuning LLMs with FVELER and then evaluating them on Code2Inv and SV-COMP. The results show that FVEL with FVELER fine-tuned Llama3- 8B solves 17.39% (69 -> 81) more problems, and Mistral-7B 12% (75 -> 84) more problems in SV-COMP. And the proportion of proof errors is reduced. Project page: https://fveler.github.io/.