 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovienet
Papers and Code
Scene-VLM: Multimodal Video Scene Segmentation via Vision-Language Models
Dec 25, 2025



Segmenting long-form videos into semantically coherent scenes is a fundamental task in large-scale video understanding. Existing encoder-based methods are limited by visual-centric biases, classify each shot in isolation without leveraging sequential dependencies, and lack both narrative understanding and explainability. In this paper, we present Scene-VLM, the first fine-tuned vision-language model (VLM) framework for video scene segmentation. Scene-VLM jointly processes visual and textual cues including frames, transcriptions, and optional metadata to enable multimodal reasoning across consecutive shots. The model generates predictions sequentially with causal dependencies among shots and introduces a context-focus window mechanism to ensure sufficient temporal context for each shot-level decision. In addition, we propose a scheme to extract confidence scores from the token-level logits of the VLM, enabling controllable precision-recall trade-offs that were previously limited to encoder-based methods. Furthermore, we demonstrate that our model can be aligned to generate coherent natural-language rationales for its boundary decisions through minimal targeted supervision. Our approach achieves state-of-the-art performance on standard scene segmentation benchmarks. On MovieNet, for example, Scene-VLM yields significant improvements of +6 AP and +13.7 F1 over the previous leading method.
Learning Video Context as Interleaved Multimodal Sequences
Jul 31, 2024



Narrative videos, such as movies, pose significant challenges in video understanding due to their rich contexts (characters, dialogues, storylines) and diverse demands (identify who, relationship, and reason). In this paper, we introduce MovieSeq, a multimodal language model developed to address the wide range of challenges in understanding video contexts. Our core idea is to represent videos as interleaved multimodal sequences (including images, plots, videos, and subtitles), either by linking external knowledge databases or using offline models (such as whisper for subtitles). Through instruction-tuning, this approach empowers the language model to interact with videos using interleaved multimodal instructions. For example, instead of solely relying on video as input, we jointly provide character photos alongside their names and dialogues, allowing the model to associate these elements and generate more comprehensive responses. To demonstrate its effectiveness, we validate MovieSeq's performance on six datasets (LVU, MAD, Movienet, CMD, TVC, MovieQA) across five settings (video classification, audio description, video-text retrieval, video captioning, and video question-answering). The code will be public at https://github.com/showlab/MovieSeq.
MEGA: Multimodal Alignment Aggregation and Distillation For Cinematic Video Segmentation
Aug 22, 2023



Previous research has studied the task of segmenting cinematic videos into scenes and into narrative acts. However, these studies have overlooked the essential task of multimodal alignment and fusion for effectively and efficiently processing long-form videos (>60min). In this paper, we introduce Multimodal alignmEnt aGgregation and distillAtion (MEGA) for cinematic long-video segmentation. MEGA tackles the challenge by leveraging multiple media modalities. The method coarsely aligns inputs of variable lengths and different modalities with alignment positional encoding. To maintain temporal synchronization while reducing computation, we further introduce an enhanced bottleneck fusion layer which uses temporal alignment. Additionally, MEGA employs a novel contrastive loss to synchronize and transfer labels across modalities, enabling act segmentation from labeled synopsis sentences on video shots. Our experimental results show that MEGA outperforms state-of-the-art methods on MovieNet dataset for scene segmentation (with an Average Precision improvement of +1.19%) and on TRIPOD dataset for act segmentation (with a Total Agreement improvement of +5.51%)
MoviePuzzle: Visual Narrative Reasoning through Multimodal Order Learning
Jun 14, 2023

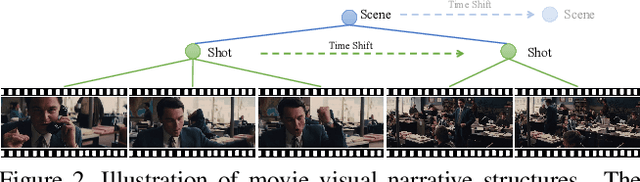
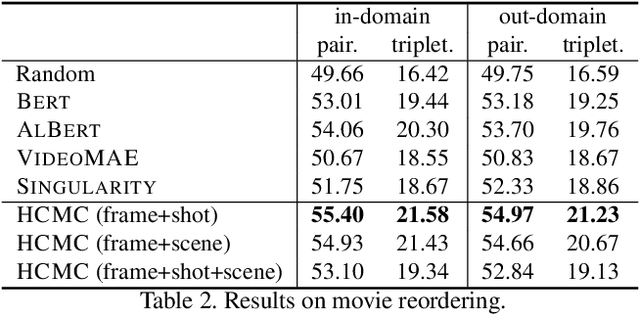
We introduce MoviePuzzle, a novel challenge that targets visual narrative reasoning and holistic movie understanding. Despite the notable progress that has been witnessed in the realm of video understanding, most prior works fail to present tasks and models to address holistic video understanding and the innate visual narrative structures existing in long-form videos. To tackle this quandary, we put forth MoviePuzzle task that amplifies the temporal feature learning and structure learning of video models by reshuffling the shot, frame, and clip layers of movie segments in the presence of video-dialogue information. We start by establishing a carefully refined dataset based on MovieNet by dissecting movies into hierarchical layers and randomly permuting the orders. Besides benchmarking the MoviePuzzle with prior arts on movie understanding, we devise a Hierarchical Contrastive Movie Clustering (HCMC) model that considers the underlying structure and visual semantic orders for movie reordering. Specifically, through a pairwise and contrastive learning approach, we train models to predict the correct order of each layer. This equips them with the knack for deciphering the visual narrative structure of movies and handling the disorder lurking in video data. Experiments show that our approach outperforms existing state-of-the-art methods on the \MoviePuzzle benchmark, underscoring its efficacy.
Translating Text Synopses to Video Storyboards
Dec 31, 2022

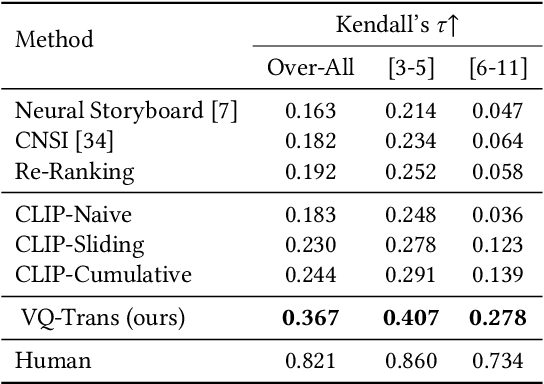

A storyboard is a roadmap for video creation which consists of shot-by-shot images to visualize key plots in a text synopsis. Creating video storyboards however remains challenging which not only requires association between high-level texts and images, but also demands for long-term reasoning to make transitions smooth across shots. In this paper, we propose a new task called Text synopsis to Video Storyboard (TeViS) which aims to retrieve an ordered sequence of images to visualize the text synopsis. We construct a MovieNet-TeViS benchmark based on the public MovieNet dataset. It contains 10K text synopses each paired with keyframes that are manually selected from corresponding movies by considering both relevance and cinematic coherence. We also present an encoder-decoder baseline for the task. The model uses a pretrained vision-and-language model to improve high-level text-image matching. To improve coherence in long-term shots, we further propose to pre-train the decoder on large-scale movie frames without text. Experimental results demonstrate that our proposed model significantly outperforms other models to create text-relevant and coherent storyboards. Nevertheless, there is still a large gap compared to human performance suggesting room for promising future work.
Efficient Movie Scene Detection using State-Space Transformers
Dec 29, 2022



The ability to distinguish between different movie scenes is critical for understanding the storyline of a movie. However, accurately detecting movie scenes is often challenging as it requires the ability to reason over very long movie segments. This is in contrast to most existing video recognition models, which are typically designed for short-range video analysis. This work proposes a State-Space Transformer model that can efficiently capture dependencies in long movie videos for accurate movie scene detection. Our model, dubbed TranS4mer, is built using a novel S4A building block, which combines the strengths of structured state-space sequence (S4) and self-attention (A) layers. Given a sequence of frames divided into movie shots (uninterrupted periods where the camera position does not change), the S4A block first applies self-attention to capture short-range intra-shot dependencies. Afterward, the state-space operation in the S4A block is used to aggregate long-range inter-shot cues. The final TranS4mer model, which can be trained end-to-end, is obtained by stacking the S4A blocks one after the other multiple times. Our proposed TranS4mer outperforms all prior methods in three movie scene detection datasets, including MovieNet, BBC, and OVSD, while also being $2\times$ faster and requiring $3\times$ less GPU memory than standard Transformer models. We will release our code and models.
Effectively leveraging Multi-modal Features for Movie Genre Classification
Mar 24, 2022



Movie genre classification has been widely studied in recent years due to its various applications in video editing, summarization, and recommendation. Prior work has typically addressed this task by predicting genres based solely on the visual content. As a result, predictions from these methods often perform poorly for genres such as documentary or musical, since non-visual modalities like audio or language play an important role in correctly classifying these genres. In addition, the analysis of long videos at frame level is always associated with high computational cost and makes the prediction less efficient. To address these two issues, we propose a Multi-Modal approach leveraging shot information, MMShot, to classify video genres in an efficient and effective way. We evaluate our method on MovieNet and Condensed Movies for genre classification, achieving 17% ~ 21% improvement on mean Average Precision (mAP) over the state-of-the-art. Extensive experiments are conducted to demonstrate the ability of MMShot for long video analysis and uncover the correlations between genres and multiple movie elements. We also demonstrate our approach's ability to generalize by evaluating the scene boundary detection task, achieving 1.1% improvement on Average Precision (AP) over the state-of-the-art.
Boundary-aware Self-supervised Learning for Video Scene Segmentation
Jan 14, 2022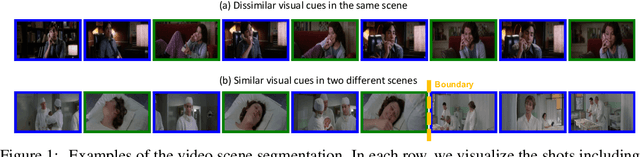
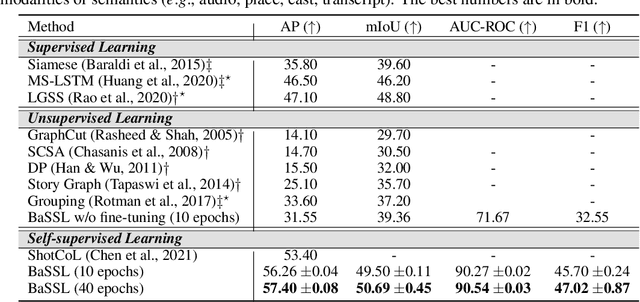
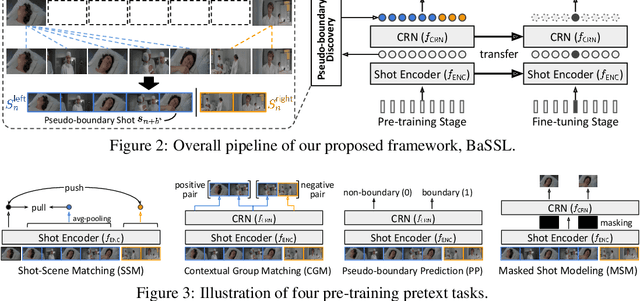
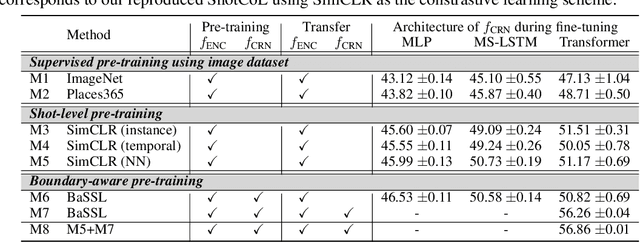
Self-supervised learning has drawn attention through its effectiveness in learning in-domain representations with no ground-truth annotations; in particular, it is shown that properly designed pretext tasks (e.g., contrastive prediction task) bring significant performance gains for downstream tasks (e.g., classification task). Inspired from this, we tackle video scene segmentation, which is a task of temporally localizing scene boundaries in a video, with a self-supervised learning framework where we mainly focus on designing effective pretext tasks. In our framework, we discover a pseudo-boundary from a sequence of shots by splitting it into two continuous, non-overlapping sub-sequences and leverage the pseudo-boundary to facilitate the pre-training. Based on this, we introduce three novel boundary-aware pretext tasks: 1) Shot-Scene Matching (SSM), 2) Contextual Group Matching (CGM) and 3) Pseudo-boundary Prediction (PP); SSM and CGM guide the model to maximize intra-scene similarity and inter-scene discrimination while PP encourages the model to identify transitional moments. Through comprehensive analysis, we empirically show that pre-training and transferring contextual representation are both critical to improving the video scene segmentation performance. Lastly, we achieve the new state-of-the-art on the MovieNet-SSeg benchmark. The code is available at https://github.com/kakaobrain/bassl.
Global-Local Context Network for Person Search
Dec 05, 2021


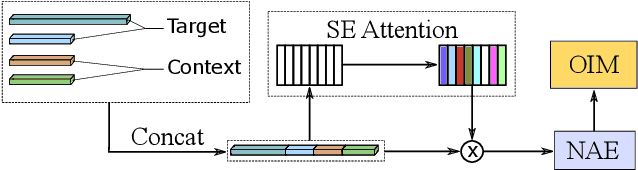
Person search aims to jointly localize and identify a query person from natural, uncropped images, which has been actively studied in the computer vision community over the past few years. In this paper, we delve into the rich context information globally and locally surrounding the target person, which we refer to scene and group context, respectively. Unlike previous works that treat the two types of context individually, we exploit them in a unified global-local context network (GLCNet) with the intuitive aim of feature enhancement. Specifically, re-ID embeddings and context features are enhanced simultaneously in a multi-stage fashion, ultimately leading to enhanced, discriminative features for person search. We conduct the experiments on two person search benchmarks (i.e., CUHK-SYSU and PRW) as well as extend our approach to a more challenging setting (i.e., character search on MovieNet). Extensive experimental results demonstrate the consistent improvement of the proposed GLCNet over the state-of-the-art methods on the three datasets. Our source codes, pre-trained models, and the new setting for character search are available at: https://github.com/ZhengPeng7/GLCNet.
Shot Contrastive Self-Supervised Learning for Scene Boundary Detection
Apr 28, 2021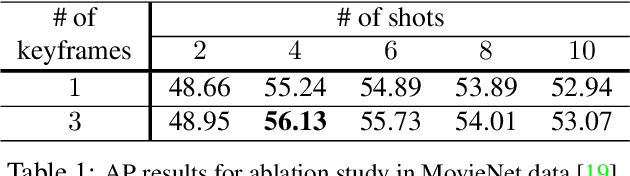
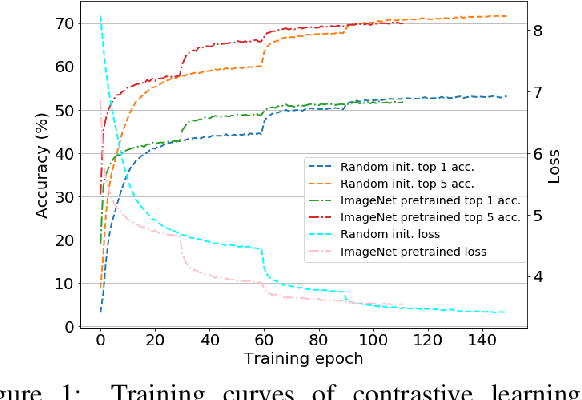

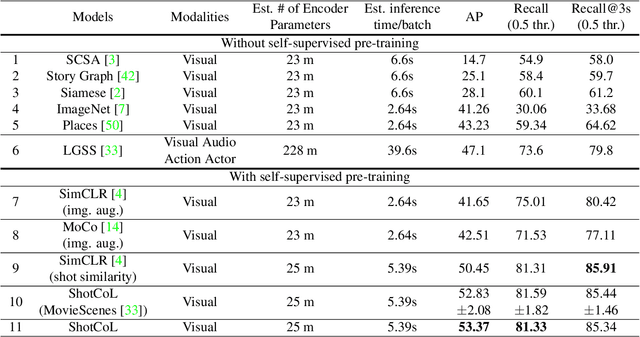
Scenes play a crucial role in breaking the storyline of movies and TV episodes into semantically cohesive parts. However, given their complex temporal structure, finding scene boundaries can be a challenging task requiring large amounts of labeled training data. To address this challenge, we present a self-supervised shot contrastive learning approach (ShotCoL) to learn a shot representation that maximizes the similarity between nearby shots compared to randomly selected shots. We show how to apply our learned shot representation for the task of scene boundary detection to offer state-of-the-art performance on the MovieNet dataset while requiring only ~25% of the training labels, using 9x fewer model parameters and offering 7x faster runtime. To assess the effectiveness of ShotCoL on novel applications of scene boundary detection, we take on the problem of finding timestamps in movies and TV episodes where video-ads can be inserted while offering a minimally disruptive viewing experience. To this end, we collected a new dataset called AdCuepoints with 3,975 movies and TV episodes, 2.2 million shots and 19,119 minimally disruptive ad cue-point labels. We present a thorough empirical analysis on this dataset demonstrating the effectiveness of ShotCoL for ad cue-points detection.