 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoviePuzzle: Visual Narrative Reasoning through Multimodal Order Learning
Paper and Code


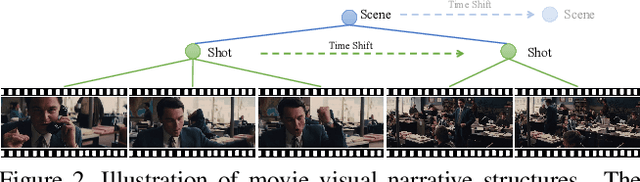
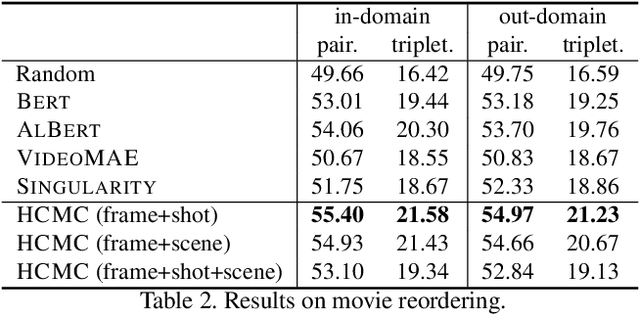
We introduce MoviePuzzle, a novel challenge that targets visual narrative reasoning and holistic movie understanding. Despite the notable progress that has been witnessed in the realm of video understanding, most prior works fail to present tasks and models to address holistic video understanding and the innate visual narrative structures existing in long-form videos. To tackle this quandary, we put forth MoviePuzzle task that amplifies the temporal feature learning and structure learning of video models by reshuffling the shot, frame, and clip layers of movie segments in the presence of video-dialogue information. We start by establishing a carefully refined dataset based on MovieNet by dissecting movies into hierarchical layers and randomly permuting the orders. Besides benchmarking the MoviePuzzle with prior arts on movie understanding, we devise a Hierarchical Contrastive Movie Clustering (HCMC) model that considers the underlying structure and visual semantic orders for movie reordering. Specifically, through a pairwise and contrastive learning approach, we train models to predict the correct order of each layer. This equips them with the knack for deciphering the visual narrative structure of movies and handling the disorder lurking in video data. Experiments show that our approach outperforms existing state-of-the-art methods on the \MoviePuzzle benchmark, underscoring its efficacy.