 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidar Mos
Papers and Code
Temporal Overlapping Prediction: A Self-supervised Pre-training Method for LiDAR Moving Object Segmentation
Mar 10, 2025



Moving object segmentation (MOS) on LiDAR point clouds is crucial for autonomous systems like self-driving vehicles. Previous supervised approaches rely heavily on costly manual annotations, while LiDAR sequences naturally capture temporal motion cues that can be leveraged for self-supervised learning. In this paper, we propose \textbf{T}emporal \textbf{O}verlapping \textbf{P}rediction (\textbf{TOP}), a self-supervised pre-training method that alleviate the labeling burden for MOS. \textbf{TOP} explores the temporal overlapping points that commonly observed by current and adjacent scans, and learns spatiotemporal representations by predicting the occupancy states of temporal overlapping points. Moreover, we utilize current occupancy reconstruction as an auxiliary pre-training objective, which enhances the current structural awareness of the model. We conduct extensive experiments and observe that the conventional metric Intersection-over-Union (IoU) shows strong bias to objects with more scanned points, which might neglect small or distant objects. To compensate for this bias, we introduce an additional metric called $\text{mIoU}_{\text{obj}}$ to evaluate object-level performance. Experiments on nuScenes and SemanticKITTI show that \textbf{TOP} outperforms both supervised training-from-scratch baseline and other self-supervised pre-training baselines by up to 28.77\% relative improvement, demonstrating strong transferability across LiDAR setups and generalization to other tasks. Code and pre-trained models will be publicly available upon publication.
HeLiMOS: A Dataset for Moving Object Segmentation in 3D Point Clouds From Heterogeneous LiDAR Sensors
Aug 12, 2024
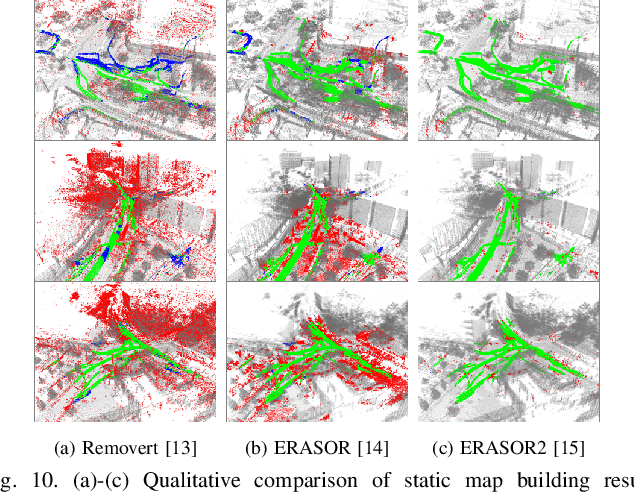
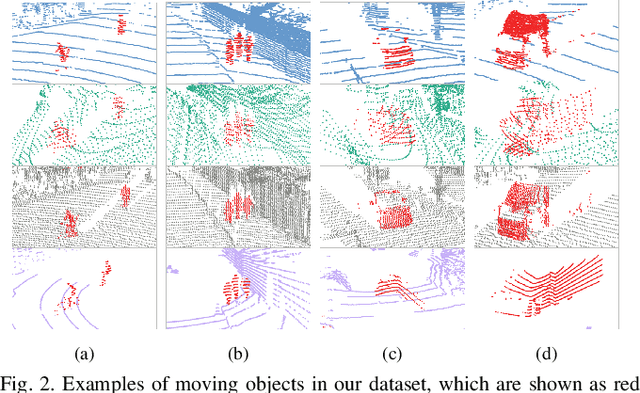

Moving object segmentation (MOS) using a 3D light detection and ranging (LiDAR) sensor is crucial for scene understanding and identification of moving objects. Despite the availability of various types of 3D LiDAR sensors in the market, MOS research still predominantly focuses on 3D point clouds from mechanically spinning omnidirectional LiDAR sensors. Thus, we are, for example, lacking a dataset with MOS labels for point clouds from solid-state LiDAR sensors which have irregular scanning patterns. In this paper, we present a labeled dataset, called \textit{HeLiMOS}, that enables to test MOS approaches on four heterogeneous LiDAR sensors, including two solid-state LiDAR sensors. Furthermore, we introduce a novel automatic labeling method to substantially reduce the labeling effort required from human annotators. To this end, our framework exploits an instance-aware static map building approach and tracking-based false label filtering. Finally, we provide experimental results regarding the performance of commonly used state-of-the-art MOS approaches on HeLiMOS that suggest a new direction for a sensor-agnostic MOS, which generally works regardless of the type of LiDAR sensors used to capture 3D point clouds. Our dataset is available at https://sites.google.com/view/helimos.
CV-MOS: A Cross-View Model for Motion Segmentation
Aug 25, 2024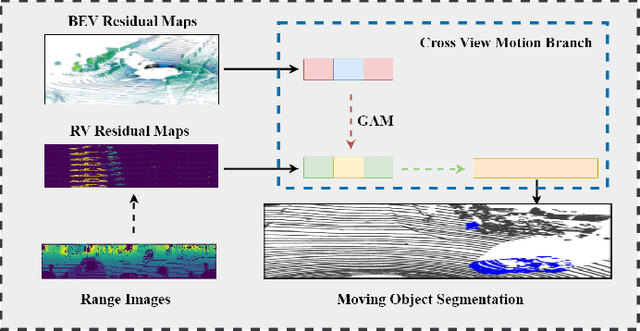
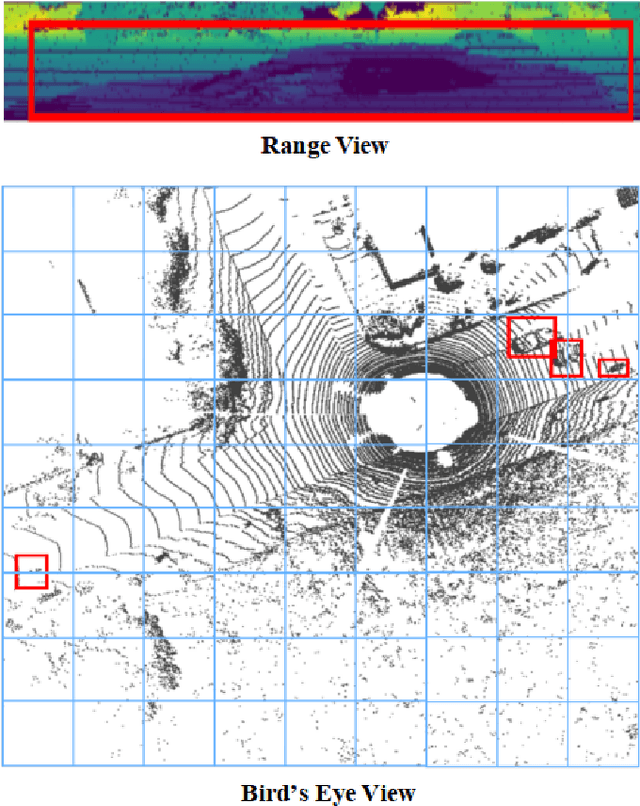
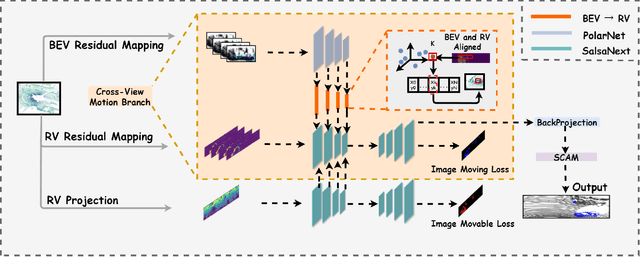
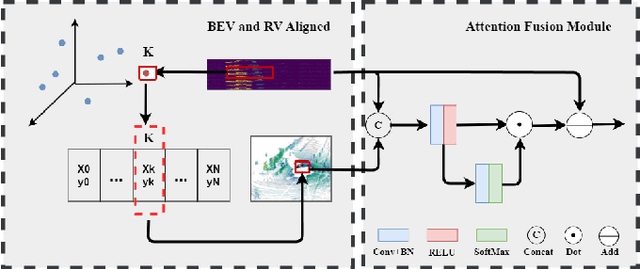
In autonomous driving, accurately distinguishing between static and moving objects is crucial for the autonomous driving system. When performing the motion object segmentation (MOS) task, effectively leveraging motion information from objects becomes a primary challenge in improving the recognition of moving objects. Previous methods either utilized range view (RV) or bird's eye view (BEV) residual maps to capture motion information. Unlike traditional approaches, we propose combining RV and BEV residual maps to exploit a greater potential of motion information jointly. Thus, we introduce CV-MOS, a cross-view model for moving object segmentation. Novelty, we decouple spatial-temporal information by capturing the motion from BEV and RV residual maps and generating semantic features from range images, which are used as moving object guidance for the motion branch. Our direct and unique solution maximizes the use of range images and RV and BEV residual maps, significantly enhancing the performance of LiDAR-based MOS task. Our method achieved leading IoU(\%) scores of 77.5\% and 79.2\% on the validation and test sets of the SemanticKitti dataset. In particular, CV-MOS demonstrates SOTA performance to date on various datasets. The CV-MOS implementation is available at https://github.com/SCNU-RISLAB/CV-MOS
MOS: Model Synergy for Test-Time Adaptation on LiDAR-Based 3D Object Detection
Jun 21, 2024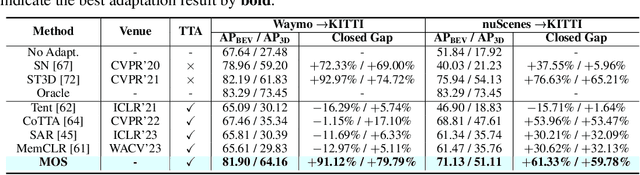


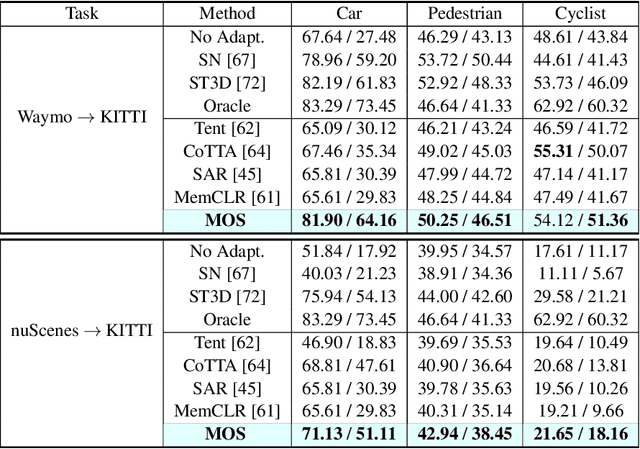
LiDAR-based 3D object detection is pivotal across many applications, yet the performance of such detection systems often degrades after deployment, especially when faced with unseen test point clouds originating from diverse locations or subjected to corruption. In this work, we introduce a new online adaptation framework for detectors named Model Synergy (MOS). Specifically, MOS dynamically assembles best-fit supermodels for each test batch from a bank of historical checkpoints, leveraging long-term knowledge to guide model updates without forgetting. The model assembly is directed by the proposed synergy weights (SW), employed for weighted averaging of the selected checkpoints to minimize redundancy in the composite supermodel. These weights are calculated by evaluating the similarity of predicted bounding boxes on test data and the feature independence among model pairs in the bank. To maintain an informative yet compact model bank, we pop out checkpoints with the lowest average SW scores and insert newly updated model weights. Our method was rigorously tested against prior test-time domain adaptation strategies on three datasets and under eight types of corruptions, demonstrating its superior adaptability to changing scenes and conditions. Remarkably, our approach achieved a 67.3% increase in performance in a complex "cross-corruption" scenario, which involves cross-dataset inconsistencies and real-world scene corruptions, providing a more realistic testbed of adaptation capabilities. The code is available at https://github.com/zhuoxiao-chen/MOS.
MambaMOS: LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model
Apr 19, 2024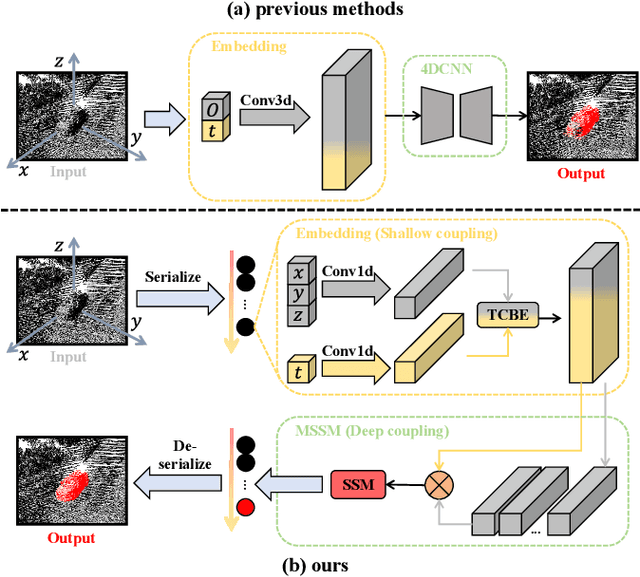
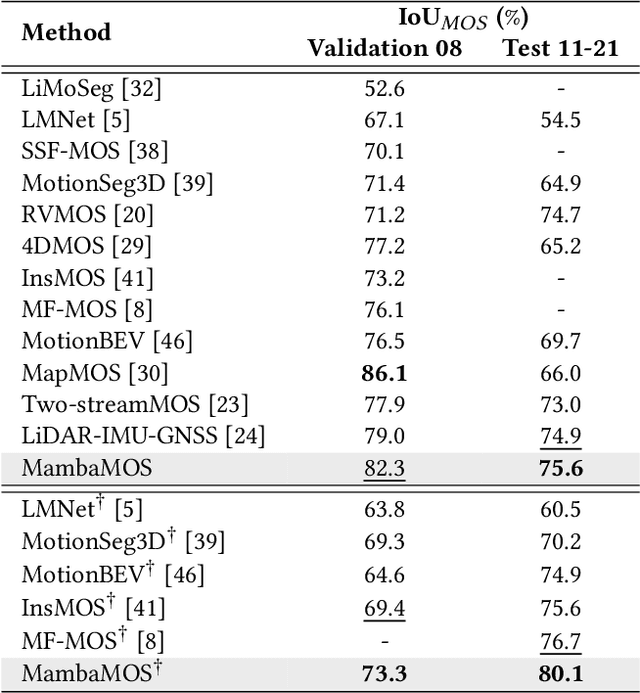
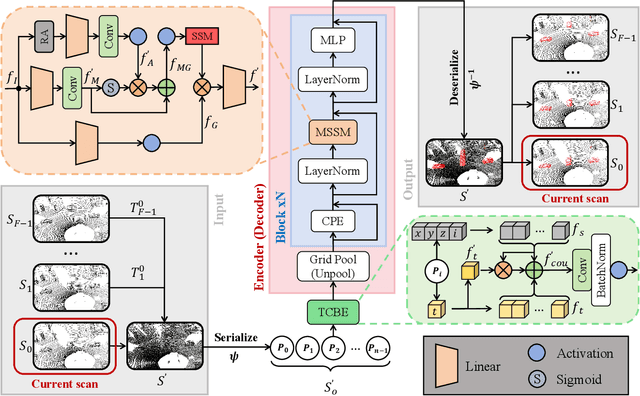
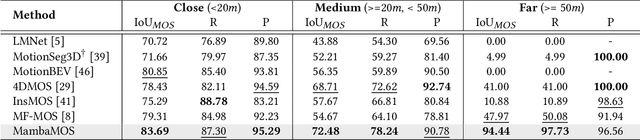
LiDAR-based Moving Object Segmentation (MOS) aims to locate and segment moving objects in point clouds of the current scan using motion information from previous scans. Despite the promising results achieved by previous MOS methods, several key issues, such as the weak coupling of temporal and spatial information, still need further study. In this paper, we propose a novel LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model, termed MambaMOS. Firstly, we develop a novel embedding module, the Time Clue Bootstrapping Embedding (TCBE), to enhance the coupling of temporal and spatial information in point clouds and alleviate the issue of overlooked temporal clues. Secondly, we introduce the Motion-aware State Space Model (MSSM) to endow the model with the capacity to understand the temporal correlations of the same object across different time steps. Specifically, MSSM emphasizes the motion states of the same object at different time steps through two distinct temporal modeling and correlation steps. We utilize an improved state space model to represent these motion differences, significantly modeling the motion states. Finally, extensive experiments on the SemanticKITTI-MOS and KITTI-Road benchmarks demonstrate that the proposed MambaMOS achieves state-of-the-art performance. The source code of this work will be made publicly available at https://github.com/Terminal-K/MambaMOS.
MF-MOS: A Motion-Focused Model for Moving Object Segmentation
Jan 30, 2024



Moving object segmentation (MOS) provides a reliable solution for detecting traffic participants and thus is of great interest in the autonomous driving field. Dynamic capture is always critical in the MOS problem. Previous methods capture motion features from the range images directly. Differently, we argue that the residual maps provide greater potential for motion information, while range images contain rich semantic guidance. Based on this intuition, we propose MF-MOS, a novel motion-focused model with a dual-branch structure for LiDAR moving object segmentation. Novelly, we decouple the spatial-temporal information by capturing the motion from residual maps and generating semantic features from range images, which are used as movable object guidance for the motion branch. Our straightforward yet distinctive solution can make the most use of both range images and residual maps, thus greatly improving the performance of the LiDAR-based MOS task. Remarkably, our MF-MOS achieved a leading IoU of 76.7% on the MOS leaderboard of the SemanticKITTI dataset upon submission, demonstrating the current state-of-the-art performance. The implementation of our MF-MOS has been released at https://github.com/SCNU-RISLAB/MF-MOS.
RadarMOSEVE: A Spatial-Temporal Transformer Network for Radar-Only Moving Object Segmentation and Ego-Velocity Estimation
Feb 22, 2024Moving object segmentation (MOS) and Ego velocity estimation (EVE) are vital capabilities for mobile systems to achieve full autonomy. Several approaches have attempted to achieve MOSEVE using a LiDAR sensor. However, LiDAR sensors are typically expensive and susceptible to adverse weather conditions. Instead, millimeter-wave radar (MWR) has gained popularity in robotics and autonomous driving for real applications due to its cost-effectiveness and resilience to bad weather. Nonetheless, publicly available MOSEVE datasets and approaches using radar data are limited. Some existing methods adopt point convolutional networks from LiDAR-based approaches, ignoring the specific artifacts and the valuable radial velocity information of radar measurements, leading to suboptimal performance. In this paper, we propose a novel transformer network that effectively addresses the sparsity and noise issues and leverages the radial velocity measurements of radar points using our devised radar self- and cross-attention mechanisms. Based on that, our method achieves accurate EVE of the robot and performs MOS using only radar data simultaneously. To thoroughly evaluate the MOSEVE performance of our method, we annotated the radar points in the public View-of-Delft (VoD) dataset and additionally constructed a new radar dataset in various environments. The experimental results demonstrate the superiority of our approach over existing state-of-the-art methods. The code is available at https://github.com/ORCA-Uboat/RadarMOSEVE.
MotionBEV: Attention-Aware Online LiDAR Moving Object Segmentation with Bird's Eye View based Appearance and Motion Features
May 12, 2023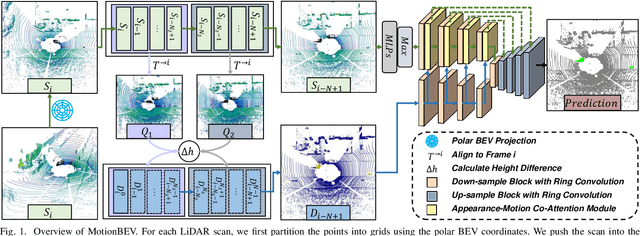

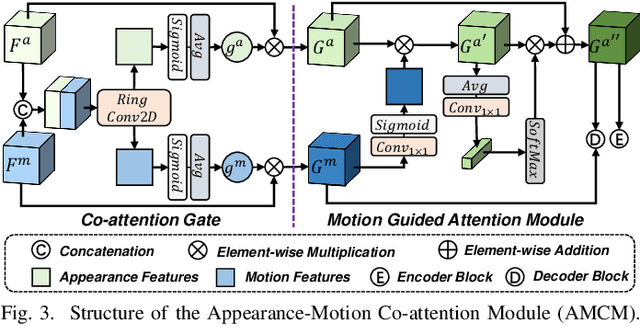
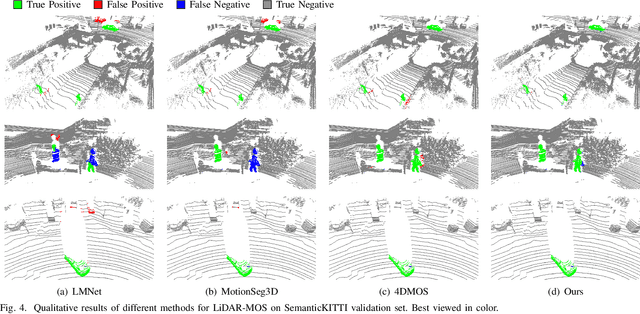
Identifying moving objects is an essential capability for autonomous systems, as it provides critical information for pose estimation, navigation, collision avoidance and static map construction. In this paper, we present MotionBEV, a fast and accurate framework for LiDAR moving object segmentation, which segments moving objects with appearance and motion features in bird's eye view (BEV) domain. Our approach converts 3D LiDAR scans into 2D polar BEV representation to achieve real-time performance. Specifically, we learn appearance features with a simplified PointNet, and compute motion features through the height differences of consecutive frames of point clouds projected onto vertical columns in the polar BEV coordinate system. We employ a dual-branch network bridged by the Appearance-Motion Co-attention Module (AMCM) to adaptively fuse the spatio-temporal information from appearance and motion features. Our approach achieves state-of-the-art performance on the SemanticKITTI-MOS benchmark, with an average inference time of 23ms on an RTX 3090 GPU. Furthermore, to demonstrate the practical effectiveness of our method, we provide a LiDAR-MOS dataset recorded by a solid-state LiDAR, which features non-repetitive scanning patterns and small field of view.
InsMOS: Instance-Aware Moving Object Segmentation in LiDAR Data
Mar 07, 2023



Identifying moving objects is a crucial capability for autonomous navigation, consistent map generation, and future trajectory prediction of objects. In this paper, we propose a novel network that addresses the challenge of segmenting moving objects in 3D LiDAR scans. Our approach not only predicts point-wise moving labels but also detects instance information of main traffic participants. Such a design helps determine which instances are actually moving and which ones are temporarily static in the current scene. Our method exploits a sequence of point clouds as input and quantifies them into 4D voxels. We use 4D sparse convolutions to extract motion features from the 4D voxels and inject them into the current scan. Then, we extract spatio-temporal features from the current scan for instance detection and feature fusion. Finally, we design an upsample fusion module to output point-wise labels by fusing the spatio-temporal features and predicted instance information. We evaluated our approach on the LiDAR-MOS benchmark based on SemanticKITTI and achieved better moving object segmentation performance compared to state-of-the-art methods, demonstrating the effectiveness of our approach in integrating instance information for moving object segmentation. Furthermore, our method shows superior performance on the Apollo dataset with a pre-trained model on SemanticKITTI, indicating that our method generalizes well in different scenes.The code and pre-trained models of our method will be released at https://github.com/nubot-nudt/InsMOS.
Unsupervised 4D LiDAR Moving Object Segmentation in Stationary Settings with Multivariate Occupancy Time Series
Dec 30, 2022



In this work, we address the problem of unsupervised moving object segmentation (MOS) in 4D LiDAR data recorded from a stationary sensor, where no ground truth annotations are involved. Deep learning-based state-of-the-art methods for LiDAR MOS strongly depend on annotated ground truth data, which is expensive to obtain and scarce in existence. To close this gap in the stationary setting, we propose a novel 4D LiDAR representation based on multivariate time series that relaxes the problem of unsupervised MOS to a time series clustering problem. More specifically, we propose modeling the change in occupancy of a voxel by a multivariate occupancy time series (MOTS), which captures spatio-temporal occupancy changes on the voxel level and its surrounding neighborhood. To perform unsupervised MOS, we train a neural network in a self-supervised manner to encode MOTS into voxel-level feature representations, which can be partitioned by a clustering algorithm into moving or stationary. Experiments on stationary scenes from the Raw KITTI dataset show that our fully unsupervised approach achieves performance that is comparable to that of supervised state-of-the-art approaches.