 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroVE: Brain-inspired Linear-Angular Velocity Estimation with Spiking Neural Networks
Aug 28, 2024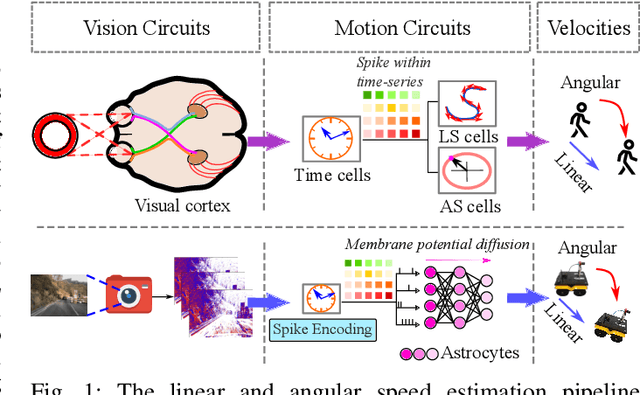
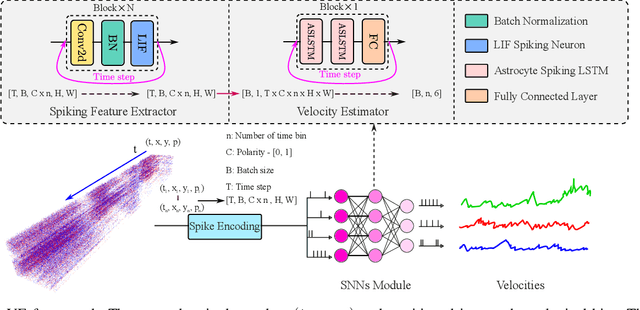
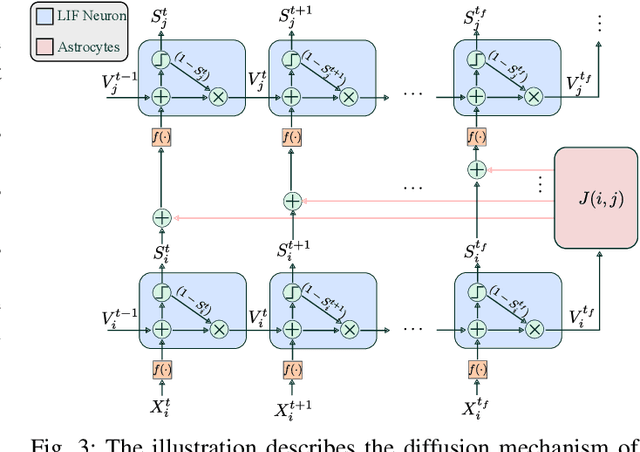
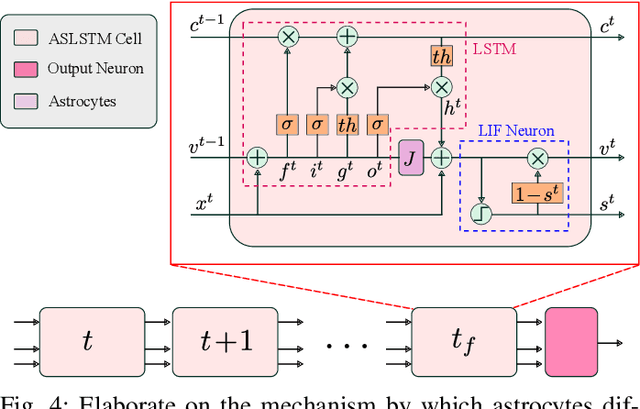
Vision-based ego-velocity estimation is a fundamental problem in robot state estimation. However, the constraints of frame-based cameras, including motion blur and insufficient frame rates in dynamic settings, readily lead to the failure of conventional velocity estimation techniques. Mammals exhibit a remarkable ability to accurately estimate their ego-velocity during aggressive movement. Hence, integrating this capability into robots shows great promise for addressing these challenges. In this paper, we propose a brain-inspired framework for linear-angular velocity estimation, dubbed NeuroVE. The NeuroVE framework employs an event camera to capture the motion information and implements spiking neural networks (SNNs) to simulate the brain's spatial cells' function for velocity estimation. We formulate the velocity estimation as a time-series forecasting problem. To this end, we design an Astrocyte Leaky Integrate-and-Fire (ALIF) neuron model to encode continuous values. Additionally, we have developed an Astrocyte Spiking Long Short-term Memory (ASLSTM) structure, which significantly improves the time-series forecasting capabilities, enabling an accurate estimate of ego-velocity. Results from both simulation and real-world experiments indicate that NeuroVE has achieved an approximate 60% increase in accuracy compared to other SNN-based approaches.
SegNet4D: Effective and Efficient 4D LiDAR Semantic Segmentation in Autonomous Driving Environments
Jun 24, 2024



4D LiDAR semantic segmentation, also referred to as multi-scan semantic segmentation, plays a crucial role in enhancing the environmental understanding capabilities of autonomous vehicles. It entails identifying the semantic category of each point in the LiDAR scan and distinguishing whether it is dynamic, a critical aspect in downstream tasks such as path planning and autonomous navigation. Existing methods for 4D semantic segmentation often rely on computationally intensive 4D convolutions for multi-scan input, resulting in poor real-time performance. In this article, we introduce SegNet4D, a novel real-time multi-scan semantic segmentation method leveraging a projection-based approach for fast motion feature encoding, showcasing outstanding performance. SegNet4D treats 4D semantic segmentation as two distinct tasks: single-scan semantic segmentation and moving object segmentation, each addressed by dedicated head. These results are then fused in the proposed motion-semantic fusion module to achieve comprehensive multi-scan semantic segmentation. Besides, we propose extracting instance information from the current scan and incorporating it into the network for instance-aware segmentation. Our approach exhibits state-of-the-art performance across multiple datasets and stands out as a real-time multi-scan semantic segmentation method. The implementation of SegNet4D will be made available at \url{https://github.com/nubot-nudt/SegNet4D}.
Spatio-Temporal Calibration for Omni-Directional Vehicle-Mounted Event Cameras
Jul 19, 2023We present a solution to the problem of spatio-temporal calibration for event cameras mounted on an onmi-directional vehicle. Different from traditional methods that typically determine the camera's pose with respect to the vehicle's body frame using alignment of trajectories, our approach leverages the kinematic correlation of two sets of linear velocity estimates from event data and wheel odometers, respectively. The overall calibration task consists of estimating the underlying temporal offset between the two heterogeneous sensors, and furthermore, recovering the extrinsic rotation that defines the linear relationship between the two sets of velocity estimates. The first sub-problem is formulated as an optimization one, which looks for the optimal temporal offset that maximizes a correlation measurement invariant to arbitrary linear transformation. Once the temporal offset is compensated, the extrinsic rotation can be worked out with an iterative closed-form solver that incrementally registers associated linear velocity estimates. The proposed algorithm is proved effective on both synthetic data and real data, outperforming traditional methods based on alignment of trajectories.
InsMOS: Instance-Aware Moving Object Segmentation in LiDAR Data
Mar 07, 2023



Identifying moving objects is a crucial capability for autonomous navigation, consistent map generation, and future trajectory prediction of objects. In this paper, we propose a novel network that addresses the challenge of segmenting moving objects in 3D LiDAR scans. Our approach not only predicts point-wise moving labels but also detects instance information of main traffic participants. Such a design helps determine which instances are actually moving and which ones are temporarily static in the current scene. Our method exploits a sequence of point clouds as input and quantifies them into 4D voxels. We use 4D sparse convolutions to extract motion features from the 4D voxels and inject them into the current scan. Then, we extract spatio-temporal features from the current scan for instance detection and feature fusion. Finally, we design an upsample fusion module to output point-wise labels by fusing the spatio-temporal features and predicted instance information. We evaluated our approach on the LiDAR-MOS benchmark based on SemanticKITTI and achieved better moving object segmentation performance compared to state-of-the-art methods, demonstrating the effectiveness of our approach in integrating instance information for moving object segmentation. Furthermore, our method shows superior performance on the Apollo dataset with a pre-trained model on SemanticKITTI, indicating that our method generalizes well in different scenes.The code and pre-trained models of our method will be released at https://github.com/nubot-nudt/InsMOS.