 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Multi Label Classification
Extreme multi-label classification is the task of assigning multiple labels to a single instance from an extremely large label space.
Papers and Code
Efficient Text Encoders for Labor Market Analysis
May 30, 2025Labor market analysis relies on extracting insights from job advertisements, which provide valuable yet unstructured information on job titles and corresponding skill requirements. While state-of-the-art methods for skill extraction achieve strong performance, they depend on large language models (LLMs), which are computationally expensive and slow. In this paper, we propose \textbf{ConTeXT-match}, a novel contrastive learning approach with token-level attention that is well-suited for the extreme multi-label classification task of skill classification. \textbf{ConTeXT-match} significantly improves skill extraction efficiency and performance, achieving state-of-the-art results with a lightweight bi-encoder model. To support robust evaluation, we introduce \textbf{Skill-XL}, a new benchmark with exhaustive, sentence-level skill annotations that explicitly address the redundancy in the large label space. Finally, we present \textbf{JobBERT V2}, an improved job title normalization model that leverages extracted skills to produce high-quality job title representations. Experiments demonstrate that our models are efficient, accurate, and scalable, making them ideal for large-scale, real-time labor market analysis.
Hierarchical Multi-Label Generation with Probabilistic Level-Constraint
Apr 30, 2025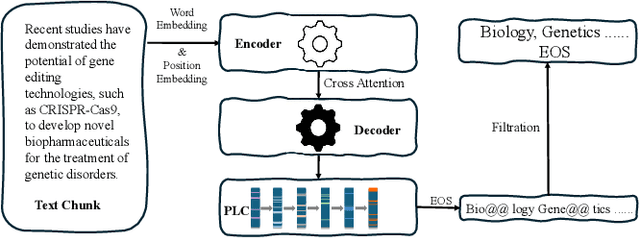
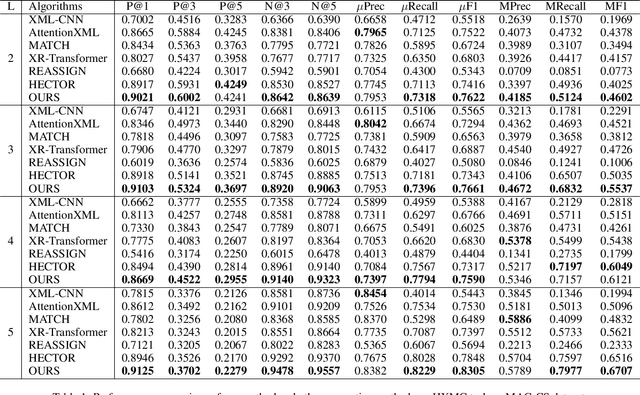
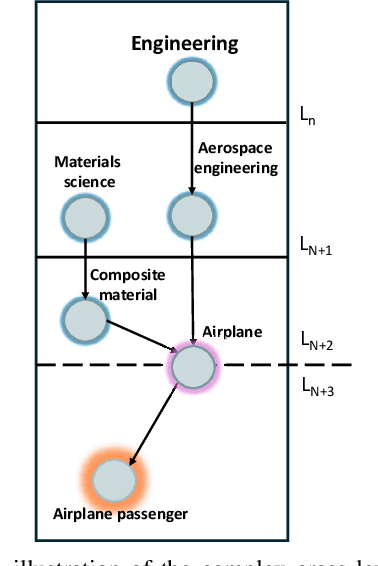
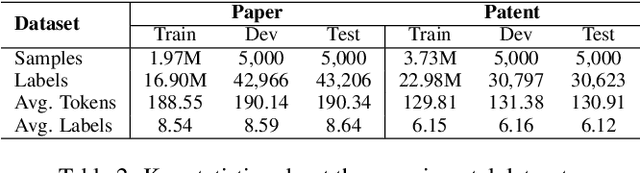
Hierarchical Extreme Multi-Label Classification poses greater difficulties compared to traditional multi-label classification because of the intricate hierarchical connections of labels within a domain-specific taxonomy and the substantial number of labels. Some of the prior research endeavors centered on classifying text through several ancillary stages such as the cluster algorithm and multiphase classification. Others made attempts to leverage the assistance of generative methods yet were unable to properly control the output of the generative model. We redefine the task from hierarchical multi-Label classification to Hierarchical Multi-Label Generation (HMG) and employ a generative framework with Probabilistic Level Constraints (PLC) to generate hierarchical labels within a specific taxonomy that have complex hierarchical relationships. The approach we proposed in this paper enables the framework to generate all relevant labels across levels for each document without relying on preliminary operations like clustering. Meanwhile, it can control the model output precisely in terms of count, length, and level aspects. Experiments demonstrate that our approach not only achieves a new SOTA performance in the HMG task, but also has a much better performance in constrained the output of model than previous research work.
Online hierarchical partitioning of the output space in extreme multi-label data stream
Jul 28, 2025



Mining data streams with multi-label outputs poses significant challenges due to evolving distributions, high-dimensional label spaces, sparse label occurrences, and complex label dependencies. Moreover, concept drift affects not only input distributions but also label correlations and imbalance ratios over time, complicating model adaptation. To address these challenges, structured learners are categorized into local and global methods. Local methods break down the task into simpler components, while global methods adapt the algorithm to the full output space, potentially yielding better predictions by exploiting label correlations. This work introduces iHOMER (Incremental Hierarchy Of Multi-label Classifiers), an online multi-label learning framework that incrementally partitions the label space into disjoint, correlated clusters without relying on predefined hierarchies. iHOMER leverages online divisive-agglomerative clustering based on \textit{Jaccard} similarity and a global tree-based learner driven by a multivariate \textit{Bernoulli} process to guide instance partitioning. To address non-stationarity, it integrates drift detection mechanisms at both global and local levels, enabling dynamic restructuring of label partitions and subtrees. Experiments across 23 real-world datasets show iHOMER outperforms 5 state-of-the-art global baselines, such as MLHAT, MLHT of Pruned Sets and iSOUPT, by 23\%, and 12 local baselines, such as binary relevance transformations of kNN, EFDT, ARF, and ADWIN bagging/boosting ensembles, by 32\%, establishing its robustness for online multi-label classification.
Transformers Meet Hyperspectral Imaging: A Comprehensive Study of Models, Challenges and Open Problems
Jun 10, 2025Transformers have become the architecture of choice for learning long-range dependencies, yet their adoption in hyperspectral imaging (HSI) is still emerging. We reviewed more than 300 papers published up to 2025 and present the first end-to-end survey dedicated to Transformer-based HSI classification. The study categorizes every stage of a typical pipeline-pre-processing, patch or pixel tokenization, positional encoding, spatial-spectral feature extraction, multi-head self-attention variants, skip connections, and loss design-and contrasts alternative design choices with the unique spatial-spectral properties of HSI. We map the field's progress against persistent obstacles: scarce labeled data, extreme spectral dimensionality, computational overhead, and limited model explainability. Finally, we outline a research agenda prioritizing valuable public data sets, lightweight on-edge models, illumination and sensor shifts robustness, and intrinsically interpretable attention mechanisms. Our goal is to guide researchers in selecting, combining, or extending Transformer components that are truly fit for purpose for next-generation HSI applications.
PiPViT: Patch-based Visual Interpretable Prototypes for Retinal Image Analysis
Jun 12, 2025



Background and Objective: Prototype-based methods improve interpretability by learning fine-grained part-prototypes; however, their visualization in the input pixel space is not always consistent with human-understandable biomarkers. In addition, well-known prototype-based approaches typically learn extremely granular prototypes that are less interpretable in medical imaging, where both the presence and extent of biomarkers and lesions are critical. Methods: To address these challenges, we propose PiPViT (Patch-based Visual Interpretable Prototypes), an inherently interpretable prototypical model for image recognition. Leveraging a vision transformer (ViT), PiPViT captures long-range dependencies among patches to learn robust, human-interpretable prototypes that approximate lesion extent only using image-level labels. Additionally, PiPViT benefits from contrastive learning and multi-resolution input processing, which enables effective localization of biomarkers across scales. Results: We evaluated PiPViT on retinal OCT image classification across four datasets, where it achieved competitive quantitative performance compared to state-of-the-art methods while delivering more meaningful explanations. Moreover, quantitative evaluation on a hold-out test set confirms that the learned prototypes are semantically and clinically relevant. We believe PiPViT can transparently explain its decisions and assist clinicians in understanding diagnostic outcomes. Github page: https://github.com/marziehoghbaie/PiPViT
MT-CYP-Net: Multi-Task Network for Pixel-Level Crop Yield Prediction Under Very Few Samples
May 17, 2025



Accurate and fine-grained crop yield prediction plays a crucial role in advancing global agriculture. However, the accuracy of pixel-level yield estimation based on satellite remote sensing data has been constrained by the scarcity of ground truth data. To address this challenge, we propose a novel approach called the Multi-Task Crop Yield Prediction Network (MT-CYP-Net). This framework introduces an effective multi-task feature-sharing strategy, where features extracted from a shared backbone network are simultaneously utilized by both crop yield prediction decoders and crop classification decoders with the ability to fuse information between them. This design allows MT-CYP-Net to be trained with extremely sparse crop yield point labels and crop type labels, while still generating detailed pixel-level crop yield maps. Concretely, we collected 1,859 yield point labels along with corresponding crop type labels and satellite images from eight farms in Heilongjiang Province, China, in 2023, covering soybean, maize, and rice crops, and constructed a sparse crop yield label dataset. MT-CYP-Net is compared with three classical machine learning and deep learning benchmark methods in this dataset. Experimental results not only indicate the superiority of MT-CYP-Net compared to previous methods on multiple types of crops but also demonstrate the potential of deep networks on precise pixel-level crop yield prediction, especially with limited data labels.
ScarceGAN: Discriminative Classification Framework for Rare Class Identification for Longitudinal Data with Weak Prior
May 02, 2025This paper introduces ScarceGAN which focuses on identification of extremely rare or scarce samples from multi-dimensional longitudinal telemetry data with small and weak label prior. We specifically address: (i) severe scarcity in positive class, stemming from both underlying organic skew in the data, as well as extremely limited labels; (ii) multi-class nature of the negative samples, with uneven density distributions and partially overlapping feature distributions; and (iii) massively unlabelled data leading to tiny and weak prior on both positive and negative classes, and possibility of unseen or unknown behavior in the unlabelled set, especially in the negative class. Although related to PU learning problems, we contend that knowledge (or lack of it) on the negative class can be leveraged to learn the compliment of it (i.e., the positive class) better in a semi-supervised manner. To this effect, ScarceGAN re-formulates semi-supervised GAN by accommodating weakly labelled multi-class negative samples and the available positive samples. It relaxes the supervised discriminator's constraint on exact differentiation between negative samples by introducing a 'leeway' term for samples with noisy prior. We propose modifications to the cost objectives of discriminator, in supervised and unsupervised path as well as that of the generator. For identifying risky players in skill gaming, this formulation in whole gives us a recall of over 85% (~60% jump over vanilla semi-supervised GAN) on our scarce class with very minimal verbosity in the unknown space. Further ScarceGAN outperforms the recall benchmarks established by recent GAN based specialized models for the positive imbalanced class identification and establishes a new benchmark in identifying one of rare attack classes (0.09%) in the intrusion dataset from the KDDCUP99 challenge.
Frequency-Adaptive Discrete Cosine-ViT-ResNet Architecture for Sparse-Data Vision
May 28, 2025A major challenge in rare animal image classification is the scarcity of data, as many species usually have only a small number of labeled samples. To address this challenge, we designed a hybrid deep-learning framework comprising a novel adaptive DCT preprocessing module, ViT-B16 and ResNet50 backbones, and a Bayesian linear classification head. To our knowledge, we are the first to introduce an adaptive frequency-domain selection mechanism that learns optimal low-, mid-, and high-frequency boundaries suited to the subsequent backbones. Our network first captures image frequency-domain cues via this adaptive DCT partitioning. The adaptively filtered frequency features are then fed into ViT-B16 to model global contextual relationships, while ResNet50 concurrently extracts local, multi-scale spatial representations from the original image. A cross-level fusion strategy seamlessly integrates these frequency- and spatial-domain embeddings, and the fused features are passed through a Bayesian linear classifier to output the final category predictions. On our self-built 50-class wildlife dataset, this approach outperforms conventional CNN and fixed-band DCT pipelines, achieving state-of-the-art accuracy under extreme sample scarcity.
Automatic Construction of Multiple Classification Dimensions for Managing Approaches in Scientific Papers
May 29, 2025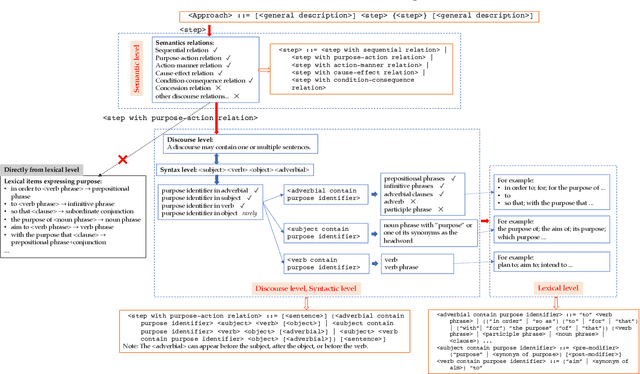
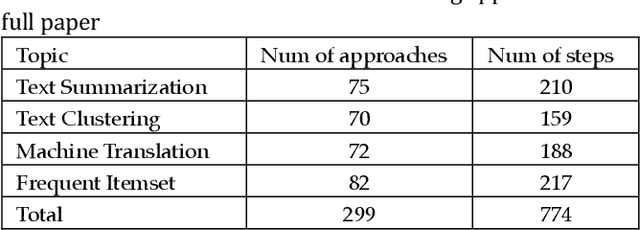


Approaches form the foundation for conducting scientific research. Querying approaches from a vast body of scientific papers is extremely time-consuming, and without a well-organized management framework, researchers may face significant challenges in querying and utilizing relevant approaches. Constructing multiple dimensions on approaches and managing them from these dimensions can provide an efficient solution. Firstly, this paper identifies approach patterns using a top-down way, refining the patterns through four distinct linguistic levels: semantic level, discourse level, syntactic level, and lexical level. Approaches in scientific papers are extracted based on approach patterns. Additionally, five dimensions for categorizing approaches are identified using these patterns. This paper proposes using tree structure to represent step and measuring the similarity between different steps with a tree-structure-based similarity measure that focuses on syntactic-level similarities. A collection similarity measure is proposed to compute the similarity between approaches. A bottom-up clustering algorithm is proposed to construct class trees for approach components within each dimension by merging each approach component or class with its most similar approach component or class in each iteration. The class labels generated during the clustering process indicate the common semantics of the step components within the approach components in each class and are used to manage the approaches within the class. The class trees of the five dimensions collectively form a multi-dimensional approach space. The application of approach queries on the multi-dimensional approach space demonstrates that querying within this space ensures strong relevance between user queries and results and rapidly reduces search space through a class-based query mechanism.
Exploring space efficiency in a tree-based linear model for extreme multi-label classification
Oct 12, 2024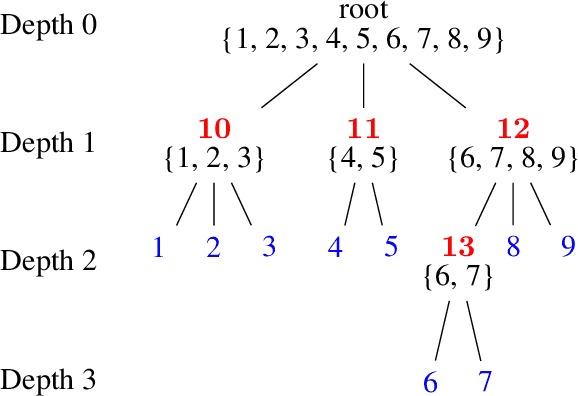
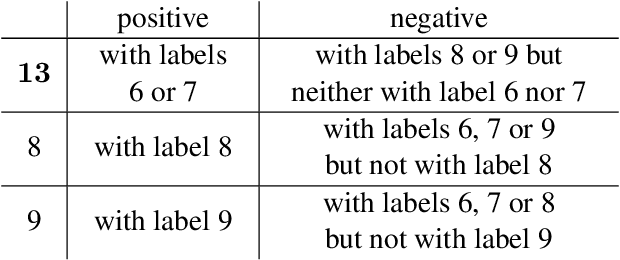
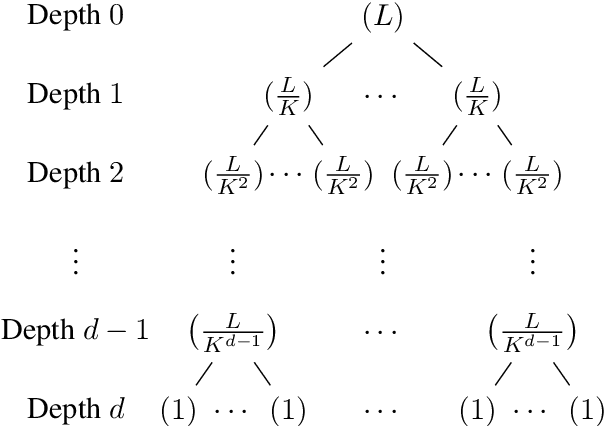
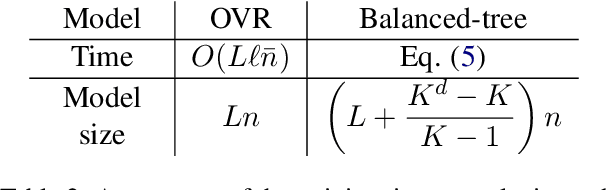
Extreme multi-label classification (XMC) aims to identify relevant subsets from numerous labels. Among the various approaches for XMC, tree-based linear models are effective due to their superior efficiency and simplicity. However, the space complexity of tree-based methods is not well-studied. Many past works assume that storing the model is not affordable and apply techniques such as pruning to save space, which may lead to performance loss. In this work, we conduct both theoretical and empirical analyses on the space to store a tree model under the assumption of sparse data, a condition frequently met in text data. We found that, some features may be unused when training binary classifiers in a tree method, resulting in zero values in the weight vectors. Hence, storing only non-zero elements can greatly save space. Our experimental results indicate that tree models can achieve up to a 95% reduction in storage space compared to the standard one-vs-rest method for multi-label text classification. Our research provides a simple procedure to estimate the size of a tree model before training any classifier in the tree nodes. Then, if the model size is already acceptable, this approach can help avoid modifying the model through weight pruning or other techniques.