 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration
Papers and Code
NV-LIO: LiDAR-Inertial Odometry using Normal Vectors Towards Robust SLAM in Multifloor Environments
May 21, 2024Over the last few decades, numerous LiDAR-inertial odometry (LIO) algorithms have been developed, demonstrating satisfactory performance across diverse environments. Most of these algorithms have predominantly been validated in open outdoor environments, however they often encounter challenges in confined indoor settings. In such indoor environments, reliable point cloud registration becomes problematic due to the rapid changes in LiDAR scans and repetitive structural features like walls and stairs, particularly in multifloor buildings. In this paper, we present NV-LIO, a normal vector based LIO framework, designed for simultaneous localization and mapping (SLAM) in indoor environments with multifloor structures. Our approach extracts the normal vectors from the LiDAR scans and utilizes them for correspondence search to enhance the point cloud registration performance. To ensure robust registration, the distribution of the normal vector directions is analyzed, and situations of degeneracy are examined to adjust the matching uncertainty. Additionally, a viewpoint based loop closure module is implemented to avoid wrong correspondences that are blocked by the walls. The propsed method is validated through public datasets and our own dataset. To contribute to the community, the code will be made public on https://github.com/dhchung/nv_lio.
Correspondence Free Multivector Cloud Registration using Conformal Geometric Algebra
Jun 17, 2024We present, for the first time, a novel theoretical approach to address the problem of correspondence free multivector cloud registration in conformal geometric algebra. Such formalism achieves several favorable properties. Primarily, it forms an orthogonal automorphism that extends beyond the typical vector space to the entire conformal geometric algebra while respecting the multivector grading. Concretely, the registration can be viewed as an orthogonal transformation (\it i.e., scale, translation, rotation) belonging to $SO(4,1)$ - group of special orthogonal transformations in conformal geometric algebra. We will show that such formalism is able to: $(i)$ perform the registration without directly accessing the input multivectors. Instead, we use primitives or geometric objects provided by the conformal model - the multivectors, $(ii)$ the geometric objects are obtained by solving a multilinear eigenvalue problem to find sets of eigenmultivectors. In this way, we can explicitly avoid solving the correspondences in the registration process. Most importantly, this offers rotation and translation equivariant properties between the input multivectors and the eigenmultivectors. Experimental evaluation is conducted in datasets commonly used in point cloud registration, to testify the usefulness of the approach with emphasis to ambiguities arising from high levels of noise. The code is available at https://github.com/Numerical-Geometric-Algebra/RegistrationGA . This work was submitted to the International Journal of Computer Vision and is currently under review.
LiVisSfM: Accurate and Robust Structure-from-Motion with LiDAR and Visual Cues
Oct 29, 2024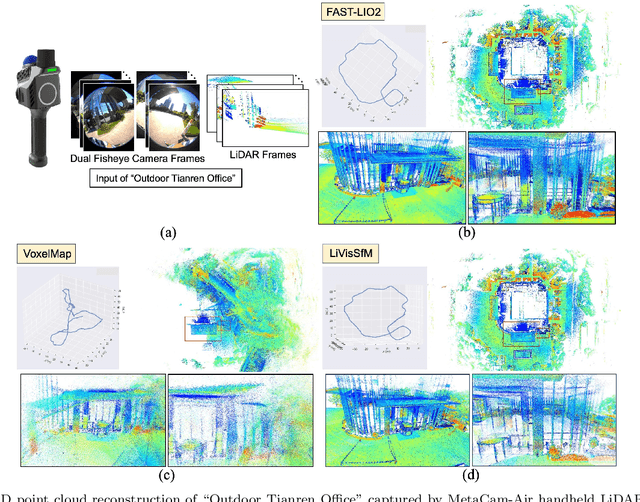

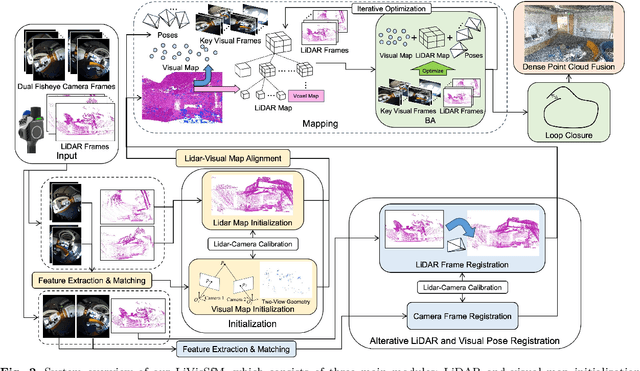

This paper presents an accurate and robust Structure-from-Motion (SfM) pipeline named LiVisSfM, which is an SfM-based reconstruction system that fully combines LiDAR and visual cues. Unlike most existing LiDAR-inertial odometry (LIO) and LiDAR-inertial-visual odometry (LIVO) methods relying heavily on LiDAR registration coupled with Inertial Measurement Unit (IMU), we propose a LiDAR-visual SfM method which innovatively carries out LiDAR frame registration to LiDAR voxel map in a Point-to-Gaussian residual metrics, combined with a LiDAR-visual BA and explicit loop closure in a bundle optimization way to achieve accurate and robust LiDAR pose estimation without dependence on IMU incorporation. Besides, we propose an incremental voxel updating strategy for efficient voxel map updating during the process of LiDAR frame registration and LiDAR-visual BA optimization. Experiments demonstrate the superior effectiveness of our LiVisSfM framework over state-of-the-art LIO and LIVO works on more accurate and robust LiDAR pose recovery and dense point cloud reconstruction of both public KITTI benchmark and a variety of self-captured dataset.
LUDO: Low-Latency Understanding of Highly Deformable Objects using Point Cloud Occupancy Functions
Nov 13, 2024Accurately determining the shape and location of internal structures within deformable objects is crucial for medical tasks that require precise targeting, such as robotic biopsies. We introduce LUDO, a method for accurate low-latency understanding of deformable objects. LUDO reconstructs objects in their deformed state, including their internal structures, from a single-view point cloud observation in under 30 ms using occupancy networks. We demonstrate LUDO's abilities for autonomous targeting of internal regions of interest (ROIs) in highly deformable objects. Additionally, LUDO provides uncertainty estimates and explainability for its predictions, both of which are important in safety-critical applications such as surgical interventions. We evaluate LUDO in real-world robotic experiments, achieving a success rate of 98.9% for puncturing various ROIs inside highly deformable objects. LUDO demonstrates the potential to interact with deformable objects without the need for deformable registration methods.
Learning Instance-Aware Correspondences for Robust Multi-Instance Point Cloud Registration in Cluttered Scenes
Apr 06, 2024Multi-instance point cloud registration estimates the poses of multiple instances of a model point cloud in a scene point cloud. Extracting accurate point correspondence is to the center of the problem. Existing approaches usually treat the scene point cloud as a whole, overlooking the separation of instances. Therefore, point features could be easily polluted by other points from the background or different instances, leading to inaccurate correspondences oblivious to separate instances, especially in cluttered scenes. In this work, we propose MIRETR, Multi-Instance REgistration TRansformer, a coarse-to-fine approach to the extraction of instance-aware correspondences. At the coarse level, it jointly learns instance-aware superpoint features and predicts per-instance masks. With instance masks, the influence from outside of the instance being concerned is minimized, such that highly reliable superpoint correspondences can be extracted. The superpoint correspondences are then extended to instance candidates at the fine level according to the instance masks. At last, an efficient candidate selection and refinement algorithm is devised to obtain the final registrations. Extensive experiments on three public benchmarks demonstrate the efficacy of our approach. In particular, MIRETR outperforms the state of the arts by 16.6 points on F1 score on the challenging ROBI benchmark. Code and models are available at https://github.com/zhiyuanYU134/MIRETR.
Rendering-Enhanced Automatic Image-to-Point Cloud Registration for Roadside Scenes
Apr 08, 2024Prior point cloud provides 3D environmental context, which enhances the capabilities of monocular camera in downstream vision tasks, such as 3D object detection, via data fusion. However, the absence of accurate and automated registration methods for estimating camera extrinsic parameters in roadside scene point clouds notably constrains the potential applications of roadside cameras. This paper proposes a novel approach for the automatic registration between prior point clouds and images from roadside scenes. The main idea involves rendering photorealistic grayscale views taken at specific perspectives from the prior point cloud with the help of their features like RGB or intensity values. These generated views can reduce the modality differences between images and prior point clouds, thereby improve the robustness and accuracy of the registration results. Particularly, we specify an efficient algorithm, named neighbor rendering, for the rendering process. Then we introduce a method for automatically estimating the initial guess using only rough guesses of camera's position. At last, we propose a procedure for iteratively refining the extrinsic parameters by minimizing the reprojection error for line features extracted from both generated and camera images using Segment Anything Model (SAM). We assess our method using a self-collected dataset, comprising eight cameras strategically positioned throughout the university campus. Experiments demonstrate our method's capability to automatically align prior point cloud with roadside camera image, achieving a rotation accuracy of 0.202 degrees and a translation precision of 0.079m. Furthermore, we validate our approach's effectiveness in visual applications by substantially improving monocular 3D object detection performance.
Efficient and Robust Point Cloud Registration via Heuristics-guided Parameter Search
Apr 09, 2024



Estimating the rigid transformation with 6 degrees of freedom based on a putative 3D correspondence set is a crucial procedure in point cloud registration. Existing correspondence identification methods usually lead to large outlier ratios ($>$ 95 $\%$ is common), underscoring the significance of robust registration methods. Many researchers turn to parameter search-based strategies (e.g., Branch-and-Bround) for robust registration. Although related methods show high robustness, their efficiency is limited to the high-dimensional search space. This paper proposes a heuristics-guided parameter search strategy to accelerate the search while maintaining high robustness. We first sample some correspondences (i.e., heuristics) and then just need to sequentially search the feasible regions that make each sample an inlier. Our strategy largely reduces the search space and can guarantee accuracy with only a few inlier samples, therefore enjoying an excellent trade-off between efficiency and robustness. Since directly parameterizing the 6-dimensional nonlinear feasible region for efficient search is intractable, we construct a three-stage decomposition pipeline to reparameterize the feasible region, resulting in three lower-dimensional sub-problems that are easily solvable via our strategy. Besides reducing the searching dimension, our decomposition enables the leverage of 1-dimensional interval stabbing at all three stages for searching acceleration. Moreover, we propose a valid sampling strategy to guarantee our sampling effectiveness, and a compatibility verification setup to further accelerate our search. Extensive experiments on both simulated and real-world datasets demonstrate that our approach exhibits comparable robustness with state-of-the-art methods while achieving a significant efficiency boost.
Rotation Initialization and Stepwise Refinement for Universal LiDAR Calibration
May 09, 2024



Autonomous systems often employ multiple LiDARs to leverage the integrated advantages, enhancing perception and robustness. The most critical prerequisite under this setting is the estimating the extrinsic between each LiDAR, i.e., calibration. Despite the exciting progress in multi-LiDAR calibration efforts, a universal, sensor-agnostic calibration method remains elusive. According to the coarse-to-fine framework, we first design a spherical descriptor TERRA for 3-DoF rotation initialization with no prior knowledge. To further optimize, we present JEEP for the joint estimation of extrinsic and pose, integrating geometric and motion information to overcome factors affecting the point cloud registration. Finally, the LiDAR poses optimized by the hierarchical optimization module are input to time synchronization module to produce the ultimate calibration results, including the time offset. To verify the effectiveness, we conduct extensive experiments on eight datasets, where 16 diverse types of LiDARs in total and dozens of calibration tasks are tested. In the challenging tasks, the calibration errors can still be controlled within 5cm and 1{\deg} with a high success rate.
Speak the Same Language: Global LiDAR Registration on BIM Using Pose Hough Transform
May 07, 2024



The construction and robotic sensing data originate from disparate sources and are associated with distinct frames of reference. The primary objective of this study is to align LiDAR point clouds with building information modeling (BIM) using a global point cloud registration approach, aimed at establishing a shared understanding between the two modalities, i.e., ``speak the same language''. To achieve this, we design a cross-modality registration method, spanning from front end the back end. At the front end, we extract descriptors by identifying walls and capturing the intersected corners. Subsequently, for the back-end pose estimation, we employ the Hough transform for pose estimation and estimate multiple pose candidates. The final pose is verified by wall-pixel correlation. To evaluate the effectiveness of our method, we conducted real-world multi-session experiments in a large-scale university building, involving two different types of LiDAR sensors. We also report our findings and plan to make our collected dataset open-sourced.
LiDAR Inertial Odometry And Mapping Using Learned Registration-Relevant Features
Oct 03, 2024SLAM is an important capability for many autonomous systems, and modern LiDAR-based methods offer promising performance. However, for long duration missions, existing works that either operate directly the full pointclouds or on extracted features face key tradeoffs in accuracy and computational efficiency (e.g., memory consumption). To address these issues, this paper presents DFLIOM with several key innovations. Unlike previous methods that rely on handcrafted heuristics and hand-tuned parameters for feature extraction, we propose a learning-based approach that select points relevant to LiDAR SLAM pointcloud registration. Furthermore, we extend our prior work DLIOM with the learned feature extractor and observe our method enables similar or even better localization performance using only about 20\% of the points in the dense point clouds. We demonstrate that DFLIOM performs well on multiple public benchmarks, achieving a 2.4\% decrease in localization error and 57.5\% decrease in memory usage compared to state-of-the-art methods (DLIOM). Although extracting features with the proposed network requires extra time, it is offset by the faster processing time downstream, thus maintaining real-time performance using 20Hz LiDAR on our hardware setup. The effectiveness of our learning-based feature extraction module is further demonstrated through comparison with several handcrafted feature extractors.