 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCholec80
Papers and Code
Holistic Surgical Phase Recognition with Hierarchical Input Dependent State Space Models
Jun 26, 2025Surgical workflow analysis is essential in robot-assisted surgeries, yet the long duration of such procedures poses significant challenges for comprehensive video analysis. Recent approaches have predominantly relied on transformer models; however, their quadratic attention mechanism restricts efficient processing of lengthy surgical videos. In this paper, we propose a novel hierarchical input-dependent state space model that leverages the linear scaling property of state space models to enable decision making on full-length videos while capturing both local and global dynamics. Our framework incorporates a temporally consistent visual feature extractor, which appends a state space model head to a visual feature extractor to propagate temporal information. The proposed model consists of two key modules: a local-aggregation state space model block that effectively captures intricate local dynamics, and a global-relation state space model block that models temporal dependencies across the entire video. The model is trained using a hybrid discrete-continuous supervision strategy, where both signals of discrete phase labels and continuous phase progresses are propagated through the network. Experiments have shown that our method outperforms the current state-of-the-art methods by a large margin (+2.8% on Cholec80, +4.3% on MICCAI2016, and +12.9% on Heichole datasets). Code will be publicly available after paper acceptance.
Meta-SurDiff: Classification Diffusion Model Optimized by Meta Learning is Reliable for Online Surgical Phase Recognition
Jun 17, 2025



Online surgical phase recognition has drawn great attention most recently due to its potential downstream applications closely related to human life and health. Despite deep models have made significant advances in capturing the discriminative long-term dependency of surgical videos to achieve improved recognition, they rarely account for exploring and modeling the uncertainty in surgical videos, which should be crucial for reliable online surgical phase recognition. We categorize the sources of uncertainty into two types, frame ambiguity in videos and unbalanced distribution among surgical phases, which are inevitable in surgical videos. To address this pivot issue, we introduce a meta-learning-optimized classification diffusion model (Meta-SurDiff), to take full advantage of the deep generative model and meta-learning in achieving precise frame-level distribution estimation for reliable online surgical phase recognition. For coarse recognition caused by ambiguous video frames, we employ a classification diffusion model to assess the confidence of recognition results at a finer-grained frame-level instance. For coarse recognition caused by unbalanced phase distribution, we use a meta-learning based objective to learn the diffusion model, thus enhancing the robustness of classification boundaries for different surgical phases.We establish effectiveness of Meta-SurDiff in online surgical phase recognition through extensive experiments on five widely used datasets using more than four practical metrics. The datasets include Cholec80, AutoLaparo, M2Cai16, OphNet, and NurViD, where OphNet comes from ophthalmic surgeries, NurViD is the daily care dataset, while the others come from laparoscopic surgeries. We will release the code upon acceptance.
Surgeons vs. Computer Vision: A comparative analysis on surgical phase recognition capabilities
Apr 26, 2025Purpose: Automated Surgical Phase Recognition (SPR) uses Artificial Intelligence (AI) to segment the surgical workflow into its key events, functioning as a building block for efficient video review, surgical education as well as skill assessment. Previous research has focused on short and linear surgical procedures and has not explored if temporal context influences experts' ability to better classify surgical phases. This research addresses these gaps, focusing on Robot-Assisted Partial Nephrectomy (RAPN) as a highly non-linear procedure. Methods: Urologists of varying expertise were grouped and tasked to indicate the surgical phase for RAPN on both single frames and video snippets using a custom-made web platform. Participants reported their confidence levels and the visual landmarks used in their decision-making. AI architectures without and with temporal context as trained and benchmarked on the Cholec80 dataset were subsequently trained on this RAPN dataset. Results: Video snippets and presence of specific visual landmarks improved phase classification accuracy across all groups. Surgeons displayed high confidence in their classifications and outperformed novices, who struggled discriminating phases. The performance of the AI models is comparable to the surgeons in the survey, with improvements when temporal context was incorporated in both cases. Conclusion: SPR is an inherently complex task for expert surgeons and computer vision, where both perform equally well when given the same context. Performance increases when temporal information is provided. Surgical tools and organs form the key landmarks for human interpretation and are expected to shape the future of automated SPR.
Surg-3M: A Dataset and Foundation Model for Perception in Surgical Settings
Mar 25, 2025Advancements in computer-assisted surgical procedures heavily rely on accurate visual data interpretation from camera systems used during surgeries. Traditional open-access datasets focusing on surgical procedures are often limited by their small size, typically consisting of fewer than 100 videos with less than 100K images. To address these constraints, a new dataset called Surg-3M has been compiled using a novel aggregation pipeline that collects high-resolution videos from online sources. Featuring an extensive collection of over 4K surgical videos and more than 3 million high-quality images from multiple procedure types, Surg-3M offers a comprehensive resource surpassing existing alternatives in size and scope, including two novel tasks. To demonstrate the effectiveness of this dataset, we present SurgFM, a self-supervised foundation model pretrained on Surg-3M that achieves impressive results in downstream tasks such as surgical phase recognition, action recognition, and tool presence detection. Combining key components from ConvNeXt, DINO, and an innovative augmented distillation method, SurgFM exhibits exceptional performance compared to specialist architectures across various benchmarks. Our experimental results show that SurgFM outperforms state-of-the-art models in multiple downstream tasks, including significant gains in surgical phase recognition (+8.9pp, +4.7pp, and +3.9pp of Jaccard in AutoLaparo, M2CAI16, and Cholec80), action recognition (+3.1pp of mAP in CholecT50) and tool presence detection (+4.6pp of mAP in Cholec80). Moreover, even when using only half of the data, SurgFM outperforms state-of-the-art models in AutoLaparo and achieves state-of-the-art performance in Cholec80. Both Surg-3M and SurgFM have significant potential to accelerate progress towards developing autonomous robotic surgery systems.
CoStoDet-DDPM: Collaborative Training of Stochastic and Deterministic Models Improves Surgical Workflow Anticipation and Recognition
Mar 13, 2025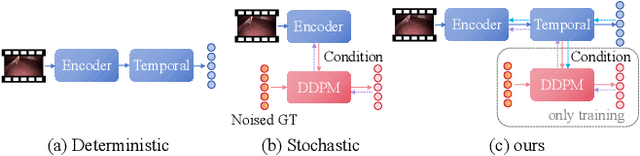
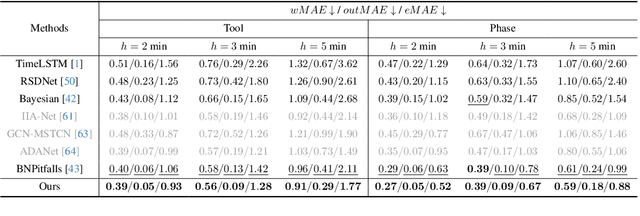
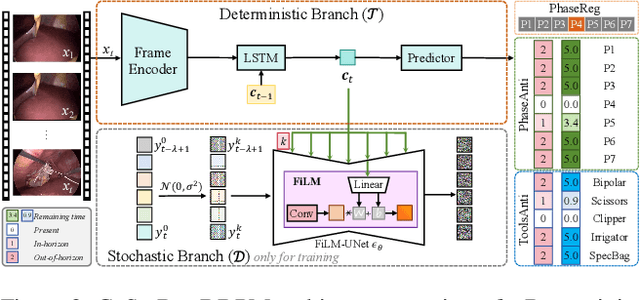
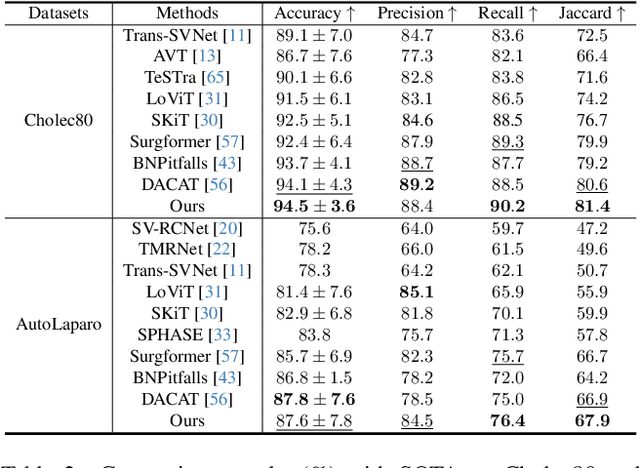
Anticipating and recognizing surgical workflows are critical for intelligent surgical assistance systems. However, existing methods rely on deterministic decision-making, struggling to generalize across the large anatomical and procedural variations inherent in real-world surgeries.In this paper, we introduce an innovative framework that incorporates stochastic modeling through a denoising diffusion probabilistic model (DDPM) into conventional deterministic learning for surgical workflow analysis. At the heart of our approach is a collaborative co-training paradigm: the DDPM branch captures procedural uncertainties to enrich feature representations, while the task branch focuses on predicting surgical phases and instrument usage.Theoretically, we demonstrate that this mutual refinement mechanism benefits both branches: the DDPM reduces prediction errors in uncertain scenarios, and the task branch directs the DDPM toward clinically meaningful representations. Notably, the DDPM branch is discarded during inference, enabling real-time predictions without sacrificing accuracy.Experiments on the Cholec80 dataset show that for the anticipation task, our method achieves a 16% reduction in eMAE compared to state-of-the-art approaches, and for phase recognition, it improves the Jaccard score by 1.0%. Additionally, on the AutoLaparo dataset, our method achieves a 1.5% improvement in the Jaccard score for phase recognition, while also exhibiting robust generalization to patient-specific variations. Our code and weight are available at https://github.com/kk42yy/CoStoDet-DDPM.
ArthroPhase: A Novel Dataset and Method for Phase Recognition in Arthroscopic Video
Feb 11, 2025



This study aims to advance surgical phase recognition in arthroscopic procedures, specifically Anterior Cruciate Ligament (ACL) reconstruction, by introducing the first arthroscopy dataset and developing a novel transformer-based model. We aim to establish a benchmark for arthroscopic surgical phase recognition by leveraging spatio-temporal features to address the specific challenges of arthroscopic videos including limited field of view, occlusions, and visual distortions. We developed the ACL27 dataset, comprising 27 videos of ACL surgeries, each labeled with surgical phases. Our model employs a transformer-based architecture, utilizing temporal-aware frame-wise feature extraction through a ResNet-50 and transformer layers. This approach integrates spatio-temporal features and introduces a Surgical Progress Index (SPI) to quantify surgery progression. The model's performance was evaluated using accuracy, precision, recall, and Jaccard Index on the ACL27 and Cholec80 datasets. The proposed model achieved an overall accuracy of 72.91% on the ACL27 dataset. On the Cholec80 dataset, the model achieved a comparable performance with the state-of-the-art methods with an accuracy of 92.4%. The SPI demonstrated an output error of 10.6% and 9.86% on ACL27 and Cholec80 datasets respectively, indicating reliable surgery progression estimation. This study introduces a significant advancement in surgical phase recognition for arthroscopy, providing a comprehensive dataset and a robust transformer-based model. The results validate the model's effectiveness and generalizability, highlighting its potential to improve surgical training, real-time assistance, and operational efficiency in orthopedic surgery. The publicly available dataset and code will facilitate future research and development in this critical field.
Dual Invariance Self-training for Reliable Semi-supervised Surgical Phase Recognition
Jan 29, 2025



Accurate surgical phase recognition is crucial for advancing computer-assisted interventions, yet the scarcity of labeled data hinders training reliable deep learning models. Semi-supervised learning (SSL), particularly with pseudo-labeling, shows promise over fully supervised methods but often lacks reliable pseudo-label assessment mechanisms. To address this gap, we propose a novel SSL framework, Dual Invariance Self-Training (DIST), that incorporates both Temporal and Transformation Invariance to enhance surgical phase recognition. Our two-step self-training process dynamically selects reliable pseudo-labels, ensuring robust pseudo-supervision. Our approach mitigates the risk of noisy pseudo-labels, steering decision boundaries toward true data distribution and improving generalization to unseen data. Evaluations on Cataract and Cholec80 datasets show our method outperforms state-of-the-art SSL approaches, consistently surpassing both supervised and SSL baselines across various network architectures.
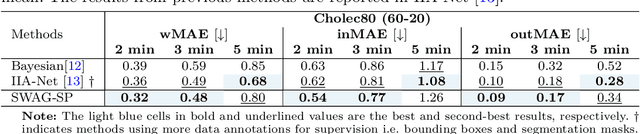
SWAG: Long-term Surgical Workflow Prediction with Generative-based Anticipation
Dec 25, 2024
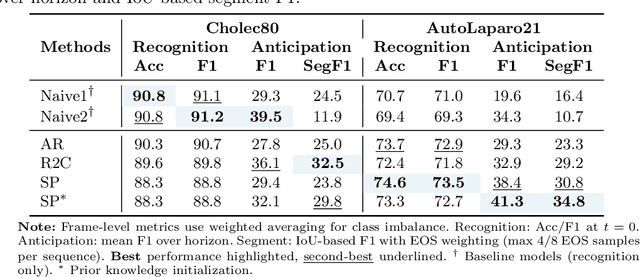
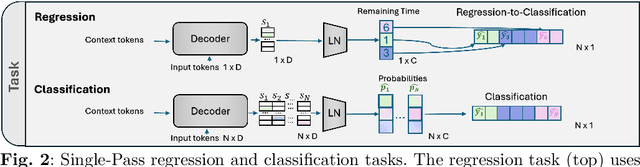
While existing recognition approaches excel at identifying current surgical phases, they provide limited foresight into future procedural steps, restricting their intraoperative utility. Similarly, current anticipation methods are constrained to predicting short-term events or singular future occurrences, neglecting the dynamic and sequential nature of surgical workflows. To address these limitations, we propose SWAG (Surgical Workflow Anticipative Generation), a unified framework for phase recognition and long-term anticipation of surgical workflows. SWAG employs two generative decoding methods -- single-pass (SP) and auto-regressive (AR) -- to predict sequences of future surgical phases. A novel prior knowledge embedding mechanism enhances the accuracy of anticipatory predictions. The framework addresses future phase classification and remaining time regression tasks. Additionally, a regression-to-classification (R2C) method is introduced to map continuous predictions to discrete temporal segments. SWAG's performance was evaluated on the Cholec80 and AutoLaparo21 datasets. The single-pass classification model with prior knowledge embeddings (SWAG-SP\*) achieved 53.5\% accuracy in 15-minute anticipation on AutoLaparo21, while the R2C model reached 60.8\% accuracy on Cholec80. SWAG's single-pass regression approach outperformed existing methods for remaining time prediction, achieving weighted mean absolute errors of 0.32 and 0.48 minutes for 2- and 3-minute horizons, respectively. SWAG demonstrates versatility across classification and regression tasks, offering robust tools for real-time surgical workflow anticipation. By unifying recognition and anticipatory capabilities, SWAG provides actionable predictions to enhance intraoperative decision-making.
Neural Finite-State Machines for Surgical Phase Recognition
Nov 27, 2024


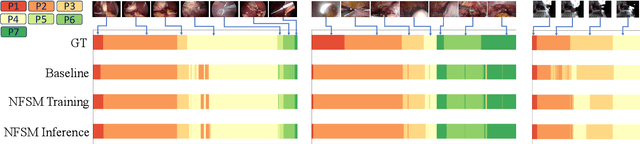
Surgical phase recognition is essential for analyzing procedure-specific surgical videos. While recent transformer-based architectures have advanced sequence processing capabilities, they struggle with maintaining consistency across lengthy surgical procedures. Drawing inspiration from classical hidden Markov models' finite-state interpretations, we introduce the neural finite-state machine (NFSM) module, which bridges procedural understanding with deep learning approaches. NFSM combines procedure-level understanding with neural networks through global state embeddings, attention-based dynamic transition tables, and transition-aware training and inference mechanisms for offline and online applications. When integrated into our future-aware architecture, NFSM improves video-level accuracy, phase-level precision, recall, and Jaccard indices on Cholec80 datasets by 2.3, 3.2, 3.0, and 4.8 percentage points respectively. As an add-on module to existing state-of-the-art models like Surgformer, NFSM further enhances performance, demonstrating its complementary value. Extended experiments on non-surgical datasets validate NFSM's generalizability beyond surgical domains. Comprehensive experiments demonstrate that incorporating NSFM into deep learning frameworks enables more robust and consistent phase recognition across long procedural videos.
Towards Robust Algorithms for Surgical Phase Recognition via Digital Twin-based Scene Representation
Oct 26, 2024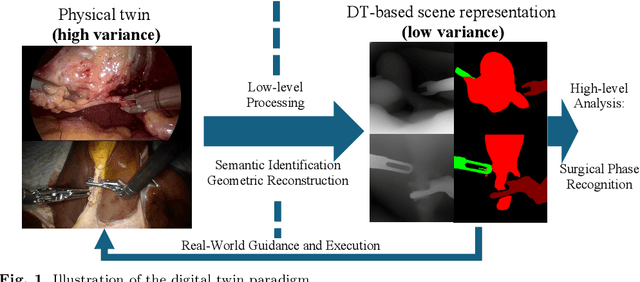

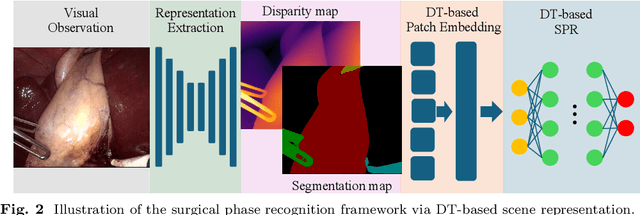
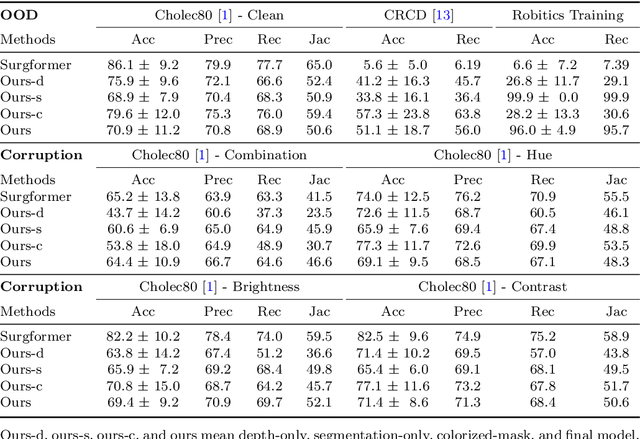
Purpose: Surgical phase recognition (SPR) is an integral component of surgical data science, enabling high-level surgical analysis. End-to-end trained neural networks that predict surgical phase directly from videos have shown excellent performance on benchmarks. However, these models struggle with robustness due to non-causal associations in the training set, resulting in poor generalizability. Our goal is to improve model robustness to variations in the surgical videos by leveraging the digital twin (DT) paradigm -- an intermediary layer to separate high-level analysis (SPR) from low-level processing (geometric understanding). This approach takes advantage of the recent vision foundation models that ensure reliable low-level scene understanding to craft DT-based scene representations that support various high-level tasks. Methods: We present a DT-based framework for SPR from videos. The framework employs vision foundation models to extract representations. We embed the representation in place of raw video inputs in the state-of-the-art Surgformer model. The framework is trained on the Cholec80 dataset and evaluated on out-of-distribution (OOD) and corrupted test samples. Results: Contrary to the vulnerability of the baseline model, our framework demonstrates strong robustness on both OOD and corrupted samples, with a video-level accuracy of 51.1 on the challenging CRCD dataset, 96.0 on an internal robotics training dataset, and 64.4 on a highly corrupted Cholec80 test set. Conclusion: Our findings lend support to the thesis that DT-based scene representations are effective in enhancing model robustness. Future work will seek to improve the feature informativeness, automate feature extraction, and incorporate interpretability for a more comprehensive framework.