 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurved Text Detection
Curved text detection is the process of identifying and localizing text that is curved or non-linear in images.
Papers and Code
Curved Worlds, Clear Boundaries: Generalizing Speech Deepfake Detection using Hyperbolic and Spherical Geometry Spaces
Nov 13, 2025In this work, we address the challenge of generalizable audio deepfake detection (ADD) across diverse speech synthesis paradigms-including conventional text-to-speech (TTS) systems and modern diffusion or flow-matching (FM) based generators. Prior work has mostly targeted individual synthesis families and often fails to generalize across paradigms due to overfitting to generation-specific artifacts. We hypothesize that synthetic speech, irrespective of its generative origin, leaves behind shared structural distortions in the embedding space that can be aligned through geometry-aware modeling. To this end, we propose RHYME, a unified detection framework that fuses utterance-level embeddings from diverse pretrained speech encoders using non-Euclidean projections. RHYME maps representations into hyperbolic and spherical manifolds-where hyperbolic geometry excels at modeling hierarchical generator families, and spherical projections capture angular, energy-invariant cues such as periodic vocoder artifacts. The fused representation is obtained via Riemannian barycentric averaging, enabling synthesis-invariant alignment. RHYME outperforms individual PTMs and homogeneous fusion baselines, achieving top performance and setting new state-of-the-art in cross-paradigm ADD.
Semantic Document Derendering: SVG Reconstruction via Vision-Language Modeling
Nov 17, 2025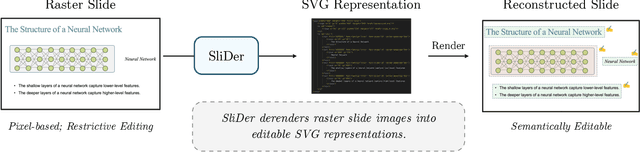
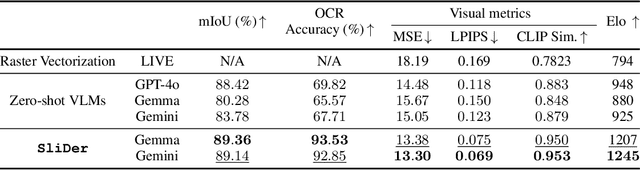
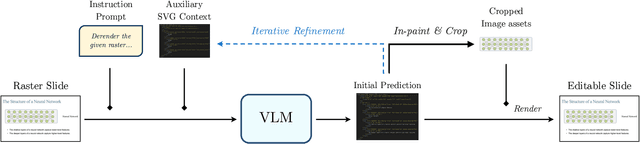
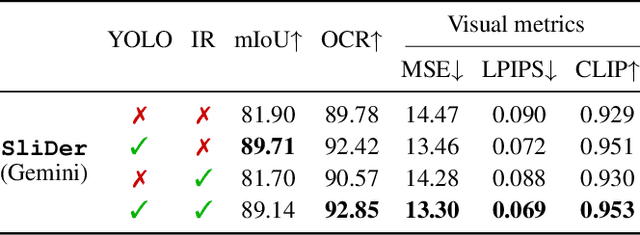
Multimedia documents such as slide presentations and posters are designed to be interactive and easy to modify. Yet, they are often distributed in a static raster format, which limits editing and customization. Restoring their editability requires converting these raster images back into structured vector formats. However, existing geometric raster-vectorization methods, which rely on low-level primitives like curves and polygons, fall short at this task. Specifically, when applied to complex documents like slides, they fail to preserve the high-level structure, resulting in a flat collection of shapes where the semantic distinction between image and text elements is lost. To overcome this limitation, we address the problem of semantic document derendering by introducing SliDer, a novel framework that uses Vision-Language Models (VLMs) to derender slide images as compact and editable Scalable Vector Graphic (SVG) representations. SliDer detects and extracts attributes from individual image and text elements in a raster input and organizes them into a coherent SVG format. Crucially, the model iteratively refines its predictions during inference in a process analogous to human design, generating SVG code that more faithfully reconstructs the original raster upon rendering. Furthermore, we introduce Slide2SVG, a novel dataset comprising raster-SVG pairs of slide documents curated from real-world scientific presentations, to facilitate future research in this domain. Our results demonstrate that SliDer achieves a reconstruction LPIPS of 0.069 and is favored by human evaluators in 82.9% of cases compared to the strongest zero-shot VLM baseline.
A Large-scale Dataset for Robust Complex Anime Scene Text Detection
Oct 09, 2025Current text detection datasets primarily target natural or document scenes, where text typically appear in regular font and shapes, monotonous colors, and orderly layouts. The text usually arranged along straight or curved lines. However, these characteristics differ significantly from anime scenes, where text is often diverse in style, irregularly arranged, and easily confused with complex visual elements such as symbols and decorative patterns. Text in anime scene also includes a large number of handwritten and stylized fonts. Motivated by this gap, we introduce AnimeText, a large-scale dataset containing 735K images and 4.2M annotated text blocks. It features hierarchical annotations and hard negative samples tailored for anime scenarios. %Cross-dataset evaluations using state-of-the-art methods demonstrate that models trained on AnimeText achieve superior performance in anime text detection tasks compared to existing datasets. To evaluate the robustness of AnimeText in complex anime scenes, we conducted cross-dataset benchmarking using state-of-the-art text detection methods. Experimental results demonstrate that models trained on AnimeText outperform those trained on existing datasets in anime scene text detection tasks. AnimeText on HuggingFace: https://huggingface.co/datasets/deepghs/AnimeText
ViTs: Teaching Machines to See Time Series Anomalies Like Human Experts
Oct 06, 2025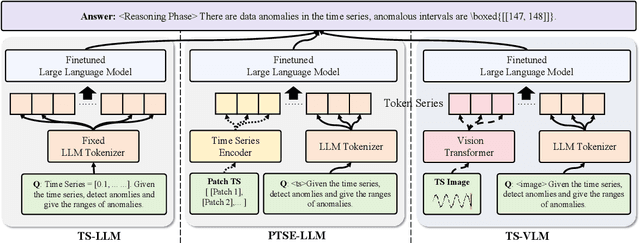

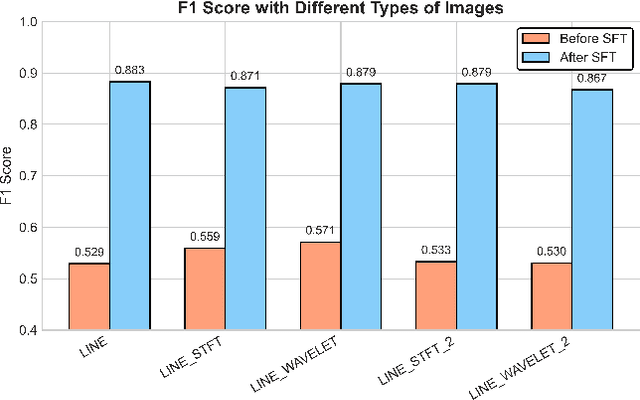
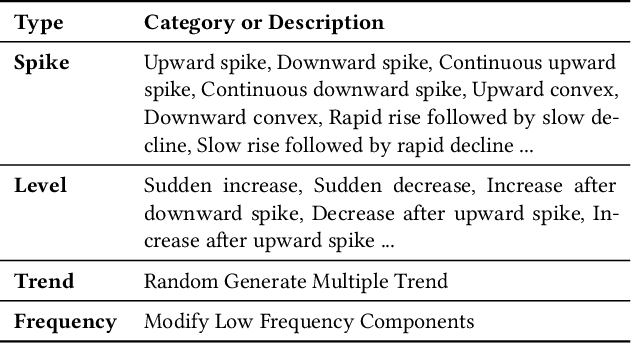
Web service administrators must ensure the stability of multiple systems by promptly detecting anomalies in Key Performance Indicators (KPIs). Achieving the goal of "train once, infer across scenarios" remains a fundamental challenge for time series anomaly detection models. Beyond improving zero-shot generalization, such models must also flexibly handle sequences of varying lengths during inference, ranging from one hour to one week, without retraining. Conventional approaches rely on sliding-window encoding and self-supervised learning, which restrict inference to fixed-length inputs. Large Language Models (LLMs) have demonstrated remarkable zero-shot capabilities across general domains. However, when applied to time series data, they face inherent limitations due to context length. To address this issue, we propose ViTs, a Vision-Language Model (VLM)-based framework that converts time series curves into visual representations. By rescaling time series images, temporal dependencies are preserved while maintaining a consistent input size, thereby enabling efficient processing of arbitrarily long sequences without context constraints. Training VLMs for this purpose introduces unique challenges, primarily due to the scarcity of aligned time series image-text data. To overcome this, we employ an evolutionary algorithm to automatically generate thousands of high-quality image-text pairs and design a three-stage training pipeline consisting of: (1) time series knowledge injection, (2) anomaly detection enhancement, and (3) anomaly reasoning refinement. Extensive experiments demonstrate that ViTs substantially enhance the ability of VLMs to understand and detect anomalies in time series data. All datasets and code will be publicly released at: https://anonymous.4open.science/r/ViTs-C484/.
SAViL-Det: Semantic-Aware Vision-Language Model for Multi-Script Text Detection
Jul 27, 2025Detecting text in natural scenes remains challenging, particularly for diverse scripts and arbitrarily shaped instances where visual cues alone are often insufficient. Existing methods do not fully leverage semantic context. This paper introduces SAViL-Det, a novel semantic-aware vision-language model that enhances multi-script text detection by effectively integrating textual prompts with visual features. SAViL-Det utilizes a pre-trained CLIP model combined with an Asymptotic Feature Pyramid Network (AFPN) for multi-scale visual feature fusion. The core of the proposed framework is a novel language-vision decoder that adaptively propagates fine-grained semantic information from text prompts to visual features via cross-modal attention. Furthermore, a text-to-pixel contrastive learning mechanism explicitly aligns textual and corresponding visual pixel features. Extensive experiments on challenging benchmarks demonstrate the effectiveness of the proposed approach, achieving state-of-the-art performance with F-scores of 84.8% on the benchmark multi-lingual MLT-2019 dataset and 90.2% on the curved-text CTW1500 dataset.
LLM-Synth4KWS: Scalable Automatic Generation and Synthesis of Confusable Data for Custom Keyword Spotting
May 29, 2025



Custom keyword spotting (KWS) allows detecting user-defined spoken keywords from streaming audio. This is achieved by comparing the embeddings from voice enrollments and input audio. State-of-the-art custom KWS models are typically trained contrastively using utterances whose keywords are randomly sampled from training dataset. These KWS models often struggle with confusing keywords, such as "blue" versus "glue". This paper introduces an effective way to augment the training with confusable utterances where keywords are generated and grouped from large language models (LLMs), and speech signals are synthesized with diverse speaking styles from text-to-speech (TTS) engines. To better measure user experience on confusable KWS, we define a new northstar metric using the average area under DET curve from confusable groups (c-AUC). Featuring high scalability and zero labor cost, the proposed method improves AUC by 3.7% and c-AUC by 11.3% on the Speech Commands testing set.
Generalized Visual Relation Detection with Diffusion Models
Apr 16, 2025Visual relation detection (VRD) aims to identify relationships (or interactions) between object pairs in an image. Although recent VRD models have achieved impressive performance, they are all restricted to pre-defined relation categories, while failing to consider the semantic ambiguity characteristic of visual relations. Unlike objects, the appearance of visual relations is always subtle and can be described by multiple predicate words from different perspectives, e.g., ``ride'' can be depicted as ``race'' and ``sit on'', from the sports and spatial position views, respectively. To this end, we propose to model visual relations as continuous embeddings, and design diffusion models to achieve generalized VRD in a conditional generative manner, termed Diff-VRD. We model the diffusion process in a latent space and generate all possible relations in the image as an embedding sequence. During the generation, the visual and text embeddings of subject-object pairs serve as conditional signals and are injected via cross-attention. After the generation, we design a subsequent matching stage to assign the relation words to subject-object pairs by considering their semantic similarities. Benefiting from the diffusion-based generative process, our Diff-VRD is able to generate visual relations beyond the pre-defined category labels of datasets. To properly evaluate this generalized VRD task, we introduce two evaluation metrics, i.e., text-to-image retrieval and SPICE PR Curve inspired by image captioning. Extensive experiments in both human-object interaction (HOI) detection and scene graph generation (SGG) benchmarks attest to the superiority and effectiveness of Diff-VRD.
Edge Approximation Text Detector
Apr 05, 2025



Pursuing efficient text shape representations helps scene text detection models focus on compact foreground regions and optimize the contour reconstruction steps to simplify the whole detection pipeline. Current approaches either represent irregular shapes via box-to-polygon strategy or decomposing a contour into pieces for fitting gradually, the deficiency of coarse contours or complex pipelines always exists in these models. Considering the above issues, we introduce EdgeText to fit text contours compactly while alleviating excessive contour rebuilding processes. Concretely, it is observed that the two long edges of texts can be regarded as smooth curves. It allows us to build contours via continuous and smooth edges that cover text regions tightly instead of fitting piecewise, which helps avoid the two limitations in current models. Inspired by this observation, EdgeText formulates the text representation as the edge approximation problem via parameterized curve fitting functions. In the inference stage, our model starts with locating text centers, and then creating curve functions for approximating text edges relying on the points. Meanwhile, truncation points are determined based on the location features. In the end, extracting curve segments from curve functions by using the pixel coordinate information brought by truncation points to reconstruct text contours. Furthermore, considering the deep dependency of EdgeText on text edges, a bilateral enhanced perception (BEP) module is designed. It encourages our model to pay attention to the recognition of edge features. Additionally, to accelerate the learning of the curve function parameters, we introduce a proportional integral loss (PI-loss) to force the proposed model to focus on the curve distribution and avoid being disturbed by text scales.
Advancing Chronic Tuberculosis Diagnostics Using Vision-Language Models: A Multi modal Framework for Precision Analysis
Mar 17, 2025



Background This study proposes a Vision-Language Model (VLM) leveraging the SIGLIP encoder and Gemma-3b transformer decoder to enhance automated chronic tuberculosis (TB) screening. By integrating chest X-ray images with clinical data, the model addresses the challenges of manual interpretation, improving diagnostic consistency and accessibility, particularly in resource-constrained settings. Methods The VLM architecture combines a Vision Transformer (ViT) for visual encoding and a transformer-based text encoder to process clinical context, such as patient histories and treatment records. Cross-modal attention mechanisms align radiographic features with textual information, while the Gemma-3b decoder generates comprehensive diagnostic reports. The model was pre-trained on 5 million paired medical images and texts and fine-tuned using 100,000 chronic TB-specific chest X-rays. Results The model demonstrated high precision (94 percent) and recall (94 percent) for detecting key chronic TB pathologies, including fibrosis, calcified granulomas, and bronchiectasis. Area Under the Curve (AUC) scores exceeded 0.93, and Intersection over Union (IoU) values were above 0.91, validating its effectiveness in detecting and localizing TB-related abnormalities. Conclusion The VLM offers a robust and scalable solution for automated chronic TB diagnosis, integrating radiographic and clinical data to deliver actionable and context-aware insights. Future work will address subtle pathologies and dataset biases to enhance the model's generalizability, ensuring equitable performance across diverse populations and healthcare settings.
OFF-CLIP: Improving Normal Detection Confidence in Radiology CLIP with Simple Off-Diagonal Term Auto-Adjustment
Mar 03, 2025



Contrastive Language-Image Pre-Training (CLIP) has enabled zero-shot classification in radiology, reducing reliance on manual annotations. However, conventional contrastive learning struggles with normal case detection due to its strict intra-sample alignment, which disrupts normal sample clustering and leads to high false positives (FPs) and false negatives (FNs). To address these issues, we propose OFF-CLIP, a contrastive learning refinement that improves normal detection by introducing an off-diagonal term loss to enhance normal sample clustering and applying sentence-level text filtering to mitigate FNs by removing misaligned normal statements from abnormal reports. OFF-CLIP can be applied to radiology CLIP models without requiring any architectural modifications. Experimental results show that OFF-CLIP significantly improves normal classification, achieving a 0.61 Area under the curve (AUC) increase on VinDr-CXR over CARZero, the state-of-the-art zero-shot classification baseline, while maintaining or improving abnormal classification performance. Additionally, OFF-CLIP enhances zero-shot grounding by improving pointing game accuracy, confirming better anomaly localization. These results demonstrate OFF-CLIP's effectiveness as a robust and efficient enhancement for medical vision-language models.