 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobIA: Robust Instance-aware Continual Test-time Adaptation for Deep Stereo
Nov 13, 2025Stereo Depth Estimation in real-world environments poses significant challenges due to dynamic domain shifts, sparse or unreliable supervision, and the high cost of acquiring dense ground-truth labels. While recent Test-Time Adaptation (TTA) methods offer promising solutions, most rely on static target domain assumptions and input-invariant adaptation strategies, limiting their effectiveness under continual shifts. In this paper, we propose RobIA, a novel Robust, Instance-Aware framework for Continual Test-Time Adaptation (CTTA) in stereo depth estimation. RobIA integrates two key components: (1) Attend-and-Excite Mixture-of-Experts (AttEx-MoE), a parameter-efficient module that dynamically routes input to frozen experts via lightweight self-attention mechanism tailored to epipolar geometry, and (2) Robust AdaptBN Teacher, a PEFT-based teacher model that provides dense pseudo-supervision by complementing sparse handcrafted labels. This strategy enables input-specific flexibility, broad supervision coverage, improving generalization under domain shift. Extensive experiments demonstrate that RobIA achieves superior adaptation performance across dynamic target domains while maintaining computational efficiency.
Detecting Redundant Health Survey Questions Using Language-agnostic BERT Sentence Embedding (LaBSE)
Dec 05, 2024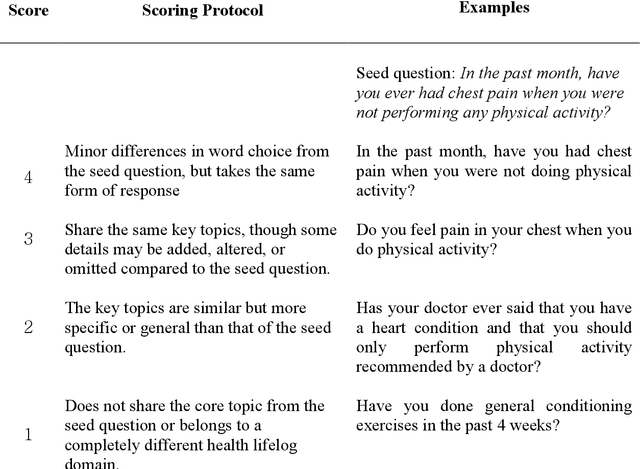
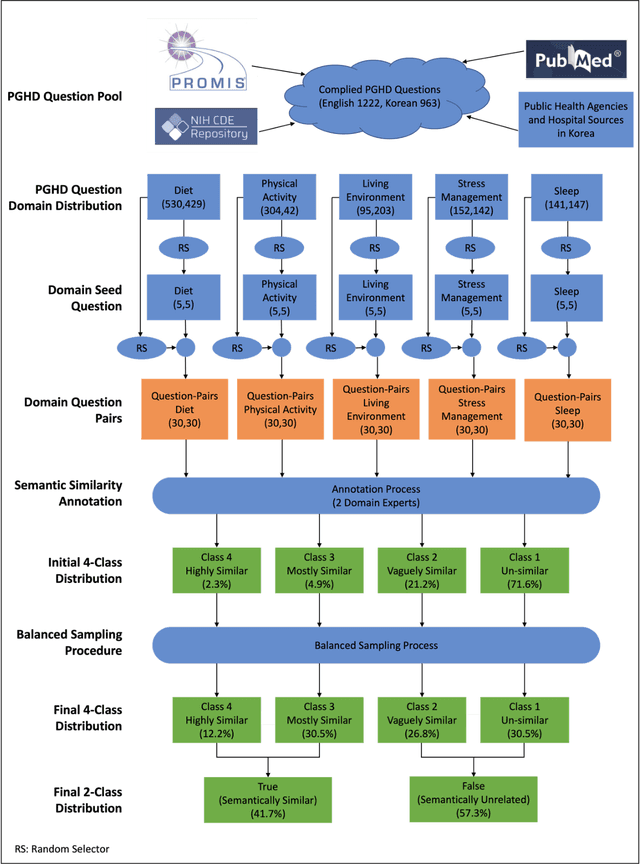
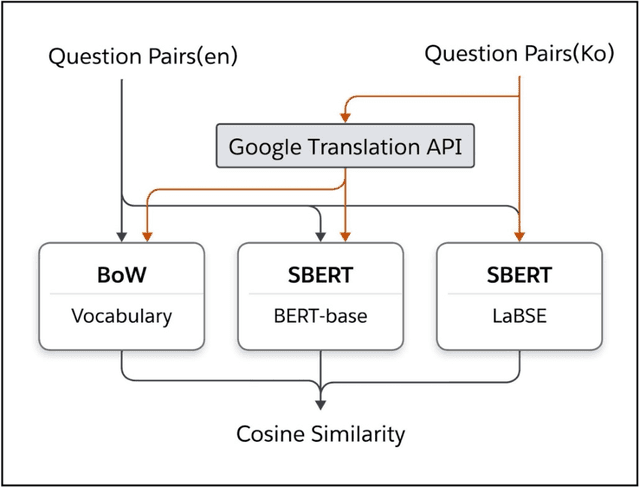

The goal of this work was to compute the semantic similarity among publicly available health survey questions in order to facilitate the standardization of survey-based Person-Generated Health Data (PGHD). We compiled various health survey questions authored in both English and Korean from the NIH CDE Repository, PROMIS, Korean public health agencies, and academic publications. Questions were drawn from various health lifelog domains. A randomized question pairing scheme was used to generate a Semantic Text Similarity (STS) dataset consisting of 1758 question pairs. Similarity scores between each question pair were assigned by two human experts. The tagged dataset was then used to build three classifiers featuring: Bag-of-Words, SBERT with BERT-based embeddings, and SBRET with LaBSE embeddings. The algorithms were evaluated using traditional contingency statistics. Among the three algorithms, SBERT-LaBSE demonstrated the highest performance in assessing question similarity across both languages, achieving an Area Under the Receiver Operating Characteristic (ROC) and Precision-Recall Curves of over 0.99. Additionally, it proved effective in identifying cross-lingual semantic similarities.The SBERT-LaBSE algorithm excelled at aligning semantically equivalent sentences across both languages but encountered challenges in capturing subtle nuances and maintaining computational efficiency. Future research should focus on testing with larger multilingual datasets and on calibrating and normalizing scores across the health lifelog domains to improve consistency. This study introduces the SBERT-LaBSE algorithm for calculating semantic similarity across two languages, showing it outperforms BERT-based models and the Bag of Words approach, highlighting its potential to improve semantic interoperability of survey-based PGHD across language barriers.
Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Sep 13, 2024Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.