 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent Framework for Extensible Structured Text Generation in PLCs
Dec 03, 2024
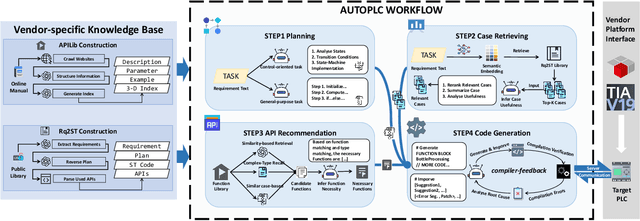
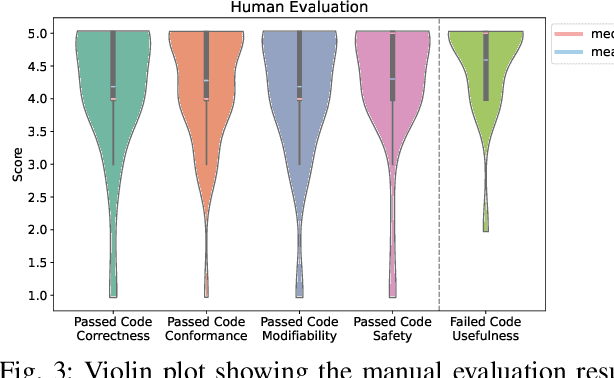
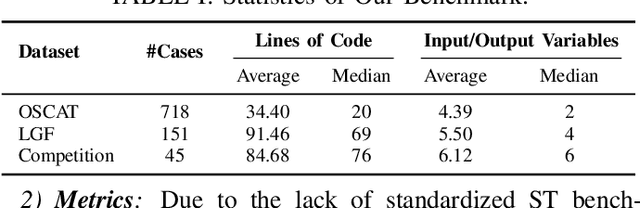
Programmable Logic Controllers (PLCs) are microcomputers essential for automating factory operations. Structured Text (ST), a high-level language adhering to the IEC 61131-3 standard, is pivotal for PLCs due to its ability to express logic succinctly and to seamlessly integrate with other languages within the same standard. However, vendors develop their own customized versions of ST, and the lack of comprehensive and standardized documentation for the full semantics of ST has contributed to inconsistencies in how the language is implemented. Consequently, the steep learning curve associated with ST, combined with ever-evolving industrial requirements, presents significant challenges for developers. In response to these issues, we present AutoPLC, an LLM-based approach designed to automate the generation of vendor-specific ST code. To facilitate effective code generation, we first built a comprehensive knowledge base, including Rq2ST Case Library (requirements and corresponding implementations) and Instruction libraries. Then we developed a retrieval module to incorporate the domain-specific knowledge by identifying pertinent cases and instructions, guiding the LLM to generate code that meets the requirements. In order to verify and improve the quality of the generated code, we designed an adaptable code checker. If errors are detected, we initiate an iterative self-improvement process to instruct the LLM to revise the generated code. We evaluate AutoPLC's performance against seven state-of-the-art baselines using three benchmarks, one for open-source basic ST and two for commercial Structured Control Language (SCL) from Siemens. The results show that our approach consistently achieves superior performance across all benchmarks. Ablation study emphasizes the significance of our modules. Further manual analysis confirm the practical utility of the ST code generated by AutoPLC.
Enhancing LLM-Based Automated Program Repair with Design Rationales
Aug 22, 2024Automatic Program Repair (APR) endeavors to autonomously rectify issues within specific projects, which generally encompasses three categories of tasks: bug resolution, new feature development, and feature enhancement. Despite extensive research proposing various methodologies, their efficacy in addressing real issues remains unsatisfactory. It's worth noting that, typically, engineers have design rationales (DR) on solution-planed solutions and a set of underlying reasons-before they start patching code. In open-source projects, these DRs are frequently captured in issue logs through project management tools like Jira. This raises a compelling question: How can we leverage DR scattered across the issue logs to efficiently enhance APR? To investigate this premise, we introduce DRCodePilot, an approach designed to augment GPT-4-Turbo's APR capabilities by incorporating DR into the prompt instruction. Furthermore, given GPT-4's constraints in fully grasping the broader project context and occasional shortcomings in generating precise identifiers, we have devised a feedback-based self-reflective framework, in which we prompt GPT-4 to reconsider and refine its outputs by referencing a provided patch and suggested identifiers. We have established a benchmark comprising 938 issue-patch pairs sourced from two open-source repositories hosted on GitHub and Jira. Our experimental results are impressive: DRCodePilot achieves a full-match ratio that is a remarkable 4.7x higher than when GPT-4 is utilized directly. Additionally, the CodeBLEU scores also exhibit promising enhancements. Moreover, our findings reveal that the standalone application of DR can yield promising increase in the full-match ratio across CodeLlama, GPT-3.5, and GPT-4 within our benchmark suite. We believe that our DRCodePilot initiative heralds a novel human-in-the-loop avenue for advancing the field of APR.