 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Pose Estimation From A Single Image
Papers and Code
Flexible Geometric Guidance for Probabilistic Human Pose Estimation with Diffusion Models
Feb 03, 20263D human pose estimation from 2D images is a challenging problem due to depth ambiguity and occlusion. Because of these challenges the task is underdetermined, where there exists multiple -- possibly infinite -- poses that are plausible given the image. Despite this, many prior works assume the existence of a deterministic mapping and estimate a single pose given an image. Furthermore, methods based on machine learning require a large amount of paired 2D-3D data to train and suffer from generalization issues to unseen scenarios. To address both of these issues, we propose a framework for pose estimation using diffusion models, which enables sampling from a probability distribution over plausible poses which are consistent with a 2D image. Our approach falls under the guidance framework for conditional generation, and guides samples from an unconditional diffusion model, trained only on 3D data, using the gradients of the heatmaps from a 2D keypoint detector. We evaluate our method on the Human 3.6M dataset under best-of-$m$ multiple hypothesis evaluation, showing state-of-the-art performance among methods which do not require paired 2D-3D data for training. We additionally evaluate the generalization ability using the MPI-INF-3DHP and 3DPW datasets and demonstrate competitive performance. Finally, we demonstrate the flexibility of our framework by using it for novel tasks including pose generation and pose completion, without the need to train bespoke conditional models. We make code available at https://github.com/fsnelgar/diffusion_pose .
PandaPose: 3D Human Pose Lifting from a Single Image via Propagating 2D Pose Prior to 3D Anchor Space
Feb 01, 20263D human pose lifting from a single RGB image is a challenging task in 3D vision. Existing methods typically establish a direct joint-to-joint mapping from 2D to 3D poses based on 2D features. This formulation suffers from two fundamental limitations: inevitable error propagation from input predicted 2D pose to 3D predictions and inherent difficulties in handling self-occlusion cases. In this paper, we propose PandaPose, a 3D human pose lifting approach via propagating 2D pose prior to 3D anchor space as the unified intermediate representation. Specifically, our 3D anchor space comprises: (1) Joint-wise 3D anchors in the canonical coordinate system, providing accurate and robust priors to mitigate 2D pose estimation inaccuracies. (2) Depth-aware joint-wise feature lifting that hierarchically integrates depth information to resolve self-occlusion ambiguities. (3) The anchor-feature interaction decoder that incorporates 3D anchors with lifted features to generate unified anchor queries encapsulating joint-wise 3D anchor set, visual cues and geometric depth information. The anchor queries are further employed to facilitate anchor-to-joint ensemble prediction. Experiments on three well-established benchmarks (i.e., Human3.6M, MPI-INF-3DHP and 3DPW) demonstrate the superiority of our proposition. The substantial reduction in error by $14.7\%$ compared to SOTA methods on the challenging conditions of Human3.6M and qualitative comparisons further showcase the effectiveness and robustness of our approach.
PEAR: Pixel-aligned Expressive humAn mesh Recovery
Jan 30, 2026Reconstructing detailed 3D human meshes from a single in-the-wild image remains a fundamental challenge in computer vision. Existing SMPLX-based methods often suffer from slow inference, produce only coarse body poses, and exhibit misalignments or unnatural artifacts in fine-grained regions such as the face and hands. These issues make current approaches difficult to apply to downstream tasks. To address these challenges, we propose PEAR-a fast and robust framework for pixel-aligned expressive human mesh recovery. PEAR explicitly tackles three major limitations of existing methods: slow inference, inaccurate localization of fine-grained human pose details, and insufficient facial expression capture. Specifically, to enable real-time SMPLX parameter inference, we depart from prior designs that rely on high resolution inputs or multi-branch architectures. Instead, we adopt a clean and unified ViT-based model capable of recovering coarse 3D human geometry. To compensate for the loss of fine-grained details caused by this simplified architecture, we introduce pixel-level supervision to optimize the geometry, significantly improving the reconstruction accuracy of fine-grained human details. To make this approach practical, we further propose a modular data annotation strategy that enriches the training data and enhances the robustness of the model. Overall, PEAR is a preprocessing-free framework that can simultaneously infer EHM-s (SMPLX and scaled-FLAME) parameters at over 100 FPS. Extensive experiments on multiple benchmark datasets demonstrate that our method achieves substantial improvements in pose estimation accuracy compared to previous SMPLX-based approaches. Project page: https://wujh2001.github.io/PEAR
On the Role of Rotation Equivariance in Monocular 3D Human Pose Estimation
Jan 20, 2026Estimating 3D from 2D is one of the central tasks in computer vision. In this work, we consider the monocular setting, i.e. single-view input, for 3D human pose estimation (HPE). Here, the task is to predict a 3D point set of human skeletal joints from a single 2D input image. While by definition this is an ill-posed problem, recent work has presented methods that solve it with up to several-centimetre error. Typically, these methods employ a two-step approach, where the first step is to detect the 2D skeletal joints in the input image, followed by the step of 2D-to-3D lifting. We find that common lifting models fail when encountering a rotated input. We argue that learning a single human pose along with its in-plane rotations is considerably easier and more geometrically grounded than directly learning a point-to-point mapping. Furthermore, our intuition is that endowing the model with the notion of rotation equivariance without explicitly constraining its parameter space should lead to a more straightforward learning process than one with equivariance by design. Utilising the common HPE benchmarks, we confirm that the 2D rotation equivariance per se improves the model performance on human poses akin to rotations in the image plane, and can be efficiently and straightforwardly learned by augmentation, outperforming state-of-the-art equivariant-by-design methods.
GazeD: Context-Aware Diffusion for Accurate 3D Gaze Estimation
Jan 19, 2026We introduce GazeD, a new 3D gaze estimation method that jointly provides 3D gaze and human pose from a single RGB image. Leveraging the ability of diffusion models to deal with uncertainty, it generates multiple plausible 3D gaze and pose hypotheses based on the 2D context information extracted from the input image. Specifically, we condition the denoising process on the 2D pose, the surroundings of the subject, and the context of the scene. With GazeD we also introduce a novel way of representing the 3D gaze by positioning it as an additional body joint at a fixed distance from the eyes. The rationale is that the gaze is usually closely related to the pose, and thus it can benefit from being jointly denoised during the diffusion process. Evaluations across three benchmark datasets demonstrate that GazeD achieves state-of-the-art performance in 3D gaze estimation, even surpassing methods that rely on temporal information. Project details will be available at https://aimagelab.ing.unimore.it/go/gazed.
ClothHMR: 3D Mesh Recovery of Humans in Diverse Clothing from Single Image
Dec 19, 2025With 3D data rapidly emerging as an important form of multimedia information, 3D human mesh recovery technology has also advanced accordingly. However, current methods mainly focus on handling humans wearing tight clothing and perform poorly when estimating body shapes and poses under diverse clothing, especially loose garments. To this end, we make two key insights: (1) tailoring clothing to fit the human body can mitigate the adverse impact of clothing on 3D human mesh recovery, and (2) utilizing human visual information from large foundational models can enhance the generalization ability of the estimation. Based on these insights, we propose ClothHMR, to accurately recover 3D meshes of humans in diverse clothing. ClothHMR primarily consists of two modules: clothing tailoring (CT) and FHVM-based mesh recovering (MR). The CT module employs body semantic estimation and body edge prediction to tailor the clothing, ensuring it fits the body silhouette. The MR module optimizes the initial parameters of the 3D human mesh by continuously aligning the intermediate representations of the 3D mesh with those inferred from the foundational human visual model (FHVM). ClothHMR can accurately recover 3D meshes of humans wearing diverse clothing, precisely estimating their body shapes and poses. Experimental results demonstrate that ClothHMR significantly outperforms existing state-of-the-art methods across benchmark datasets and in-the-wild images. Additionally, a web application for online fashion and shopping powered by ClothHMR is developed, illustrating that ClothHMR can effectively serve real-world usage scenarios. The code and model for ClothHMR are available at: \url{https://github.com/starVisionTeam/ClothHMR}.
VPHO: Joint Visual-Physical Cue Learning and Aggregation for Hand-Object Pose Estimation
Nov 15, 2025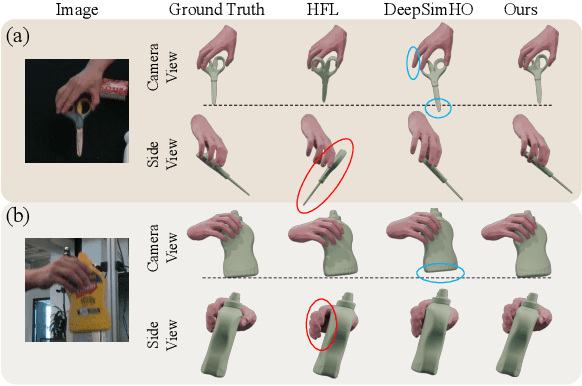
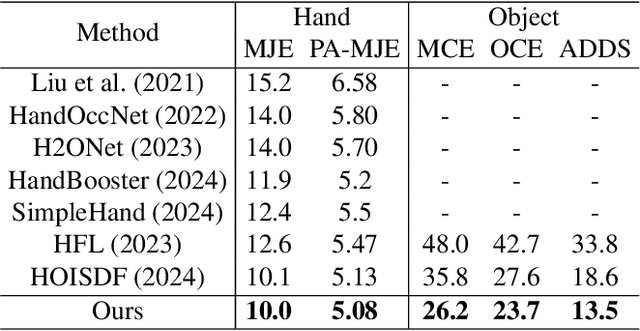
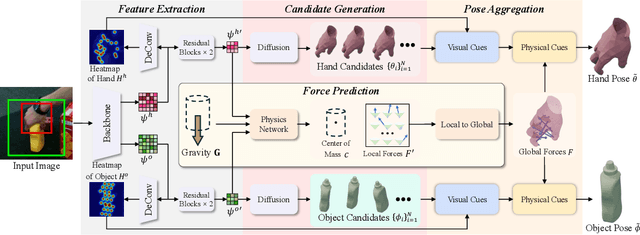
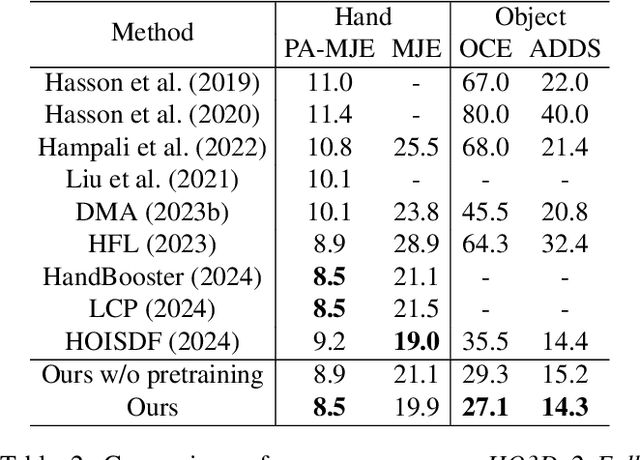
Estimating the 3D poses of hands and objects from a single RGB image is a fundamental yet challenging problem, with broad applications in augmented reality and human-computer interaction. Existing methods largely rely on visual cues alone, often producing results that violate physical constraints such as interpenetration or non-contact. Recent efforts to incorporate physics reasoning typically depend on post-optimization or non-differentiable physics engines, which compromise visual consistency and end-to-end trainability. To overcome these limitations, we propose a novel framework that jointly integrates visual and physical cues for hand-object pose estimation. This integration is achieved through two key ideas: 1) joint visual-physical cue learning: The model is trained to extract 2D visual cues and 3D physical cues, thereby enabling more comprehensive representation learning for hand-object interactions; 2) candidate pose aggregation: A novel refinement process that aggregates multiple diffusion-generated candidate poses by leveraging both visual and physical predictions, yielding a final estimate that is visually consistent and physically plausible. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches in both pose accuracy and physical plausibility.
Adaptive graph Kolmogorov-Arnold network for 3D human pose estimation
Nov 11, 2025Graph convolutional network (GCN)-based methods have shown strong performance in 3D human pose estimation by leveraging the natural graph structure of the human skeleton. However, their local receptive field limits their ability to capture long-range dependencies essential for handling occlusions and depth ambiguities. They also exhibit spectral bias, which prioritizes low-frequency components while struggling to model high-frequency details. In this paper, we introduce PoseKAN, an adaptive graph Kolmogorov-Arnold Network (KAN), framework that extends KANs to graph-based learning for 2D-to-3D pose lifting from a single image. Unlike GCNs that use fixed activation functions, KANs employ learnable functions on graph edges, allowing data-driven, adaptive feature transformations. This enhances the model's adaptability and expressiveness, making it more expressive in learning complex pose variations. Our model employs multi-hop feature aggregation, ensuring the body joints can leverage information from both local and distant neighbors, leading to improved spatial awareness. It also incorporates residual PoseKAN blocks for deeper feature refinement, and a global response normalization for improved feature selectivity and contrast. Extensive experiments on benchmark datasets demonstrate the competitive performance of our model against state-of-the-art methods.
SyncHuman: Synchronizing 2D and 3D Generative Models for Single-view Human Reconstruction
Oct 09, 2025Photorealistic 3D full-body human reconstruction from a single image is a critical yet challenging task for applications in films and video games due to inherent ambiguities and severe self-occlusions. While recent approaches leverage SMPL estimation and SMPL-conditioned image generative models to hallucinate novel views, they suffer from inaccurate 3D priors estimated from SMPL meshes and have difficulty in handling difficult human poses and reconstructing fine details. In this paper, we propose SyncHuman, a novel framework that combines 2D multiview generative model and 3D native generative model for the first time, enabling high-quality clothed human mesh reconstruction from single-view images even under challenging human poses. Multiview generative model excels at capturing fine 2D details but struggles with structural consistency, whereas 3D native generative model generates coarse yet structurally consistent 3D shapes. By integrating the complementary strengths of these two approaches, we develop a more effective generation framework. Specifically, we first jointly fine-tune the multiview generative model and the 3D native generative model with proposed pixel-aligned 2D-3D synchronization attention to produce geometrically aligned 3D shapes and 2D multiview images. To further improve details, we introduce a feature injection mechanism that lifts fine details from 2D multiview images onto the aligned 3D shapes, enabling accurate and high-fidelity reconstruction. Extensive experiments demonstrate that SyncHuman achieves robust and photo-realistic 3D human reconstruction, even for images with challenging poses. Our method outperforms baseline methods in geometric accuracy and visual fidelity, demonstrating a promising direction for future 3D generation models.
IDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.