 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration
Papers and Code
Scene Coordinate Reconstruction Priors
Oct 14, 2025Scene coordinate regression (SCR) models have proven to be powerful implicit scene representations for 3D vision, enabling visual relocalization and structure-from-motion. SCR models are trained specifically for one scene. If training images imply insufficient multi-view constraints SCR models degenerate. We present a probabilistic reinterpretation of training SCR models, which allows us to infuse high-level reconstruction priors. We investigate multiple such priors, ranging from simple priors over the distribution of reconstructed depth values to learned priors over plausible scene coordinate configurations. For the latter, we train a 3D point cloud diffusion model on a large corpus of indoor scans. Our priors push predicted 3D scene points towards plausible geometry at each training step to increase their likelihood. On three indoor datasets our priors help learning better scene representations, resulting in more coherent scene point clouds, higher registration rates and better camera poses, with a positive effect on down-stream tasks such as novel view synthesis and camera relocalization.
Self-Supervised Cross-Modal Learning for Image-to-Point Cloud Registration
Sep 19, 2025Bridging 2D and 3D sensor modalities is critical for robust perception in autonomous systems. However, image-to-point cloud (I2P) registration remains challenging due to the semantic-geometric gap between texture-rich but depth-ambiguous images and sparse yet metrically precise point clouds, as well as the tendency of existing methods to converge to local optima. To overcome these limitations, we introduce CrossI2P, a self-supervised framework that unifies cross-modal learning and two-stage registration in a single end-to-end pipeline. First, we learn a geometric-semantic fused embedding space via dual-path contrastive learning, enabling annotation-free, bidirectional alignment of 2D textures and 3D structures. Second, we adopt a coarse-to-fine registration paradigm: a global stage establishes superpoint-superpixel correspondences through joint intra-modal context and cross-modal interaction modeling, followed by a geometry-constrained point-level refinement for precise registration. Third, we employ a dynamic training mechanism with gradient normalization to balance losses for feature alignment, correspondence refinement, and pose estimation. Extensive experiments demonstrate that CrossI2P outperforms state-of-the-art methods by 23.7% on the KITTI Odometry benchmark and by 37.9% on nuScenes, significantly improving both accuracy and robustness.
An Adaptive ICP LiDAR Odometry Based on Reliable Initial Pose
Sep 26, 2025As a key technology for autonomous navigation and positioning in mobile robots, light detection and ranging (LiDAR) odometry is widely used in autonomous driving applications. The Iterative Closest Point (ICP)-based methods have become the core technique in LiDAR odometry due to their efficient and accurate point cloud registration capability. However, some existing ICP-based methods do not consider the reliability of the initial pose, which may cause the method to converge to a local optimum. Furthermore, the absence of an adaptive mechanism hinders the effective handling of complex dynamic environments, resulting in a significant degradation of registration accuracy. To address these issues, this paper proposes an adaptive ICP-based LiDAR odometry method that relies on a reliable initial pose. First, distributed coarse registration based on density filtering is employed to obtain the initial pose estimation. The reliable initial pose is then selected by comparing it with the motion prediction pose, reducing the initial error between the source and target point clouds. Subsequently, by combining the current and historical errors, the adaptive threshold is dynamically adjusted to accommodate the real-time changes in the dynamic environment. Finally, based on the reliable initial pose and the adaptive threshold, point-to-plane adaptive ICP registration is performed from the current frame to the local map, achieving high-precision alignment of the source and target point clouds. Extensive experiments on the public KITTI dataset demonstrate that the proposed method outperforms existing approaches and significantly enhances the accuracy of LiDAR odometry.
iMatcher: Improve matching in point cloud registration via local-to-global geometric consistency learning
Sep 10, 2025This paper presents iMatcher, a fully differentiable framework for feature matching in point cloud registration. The proposed method leverages learned features to predict a geometrically consistent confidence matrix, incorporating both local and global consistency. First, a local graph embedding module leads to an initialization of the score matrix. A subsequent repositioning step refines this matrix by considering bilateral source-to-target and target-to-source matching via nearest neighbor search in 3D space. The paired point features are then stacked together to be refined through global geometric consistency learning to predict a point-wise matching probability. Extensive experiments on real-world outdoor (KITTI, KITTI-360) and indoor (3DMatch) datasets, as well as on 6-DoF pose estimation (TUD-L) and partial-to-partial matching (MVP-RG), demonstrate that iMatcher significantly improves rigid registration performance. The method achieves state-of-the-art inlier ratios, scoring 95% - 97% on KITTI, 94% - 97% on KITTI-360, and up to 81.1% on 3DMatch, highlighting its robustness across diverse settings.
MATTER: Multiscale Attention for Registration Error Regression
Sep 16, 2025

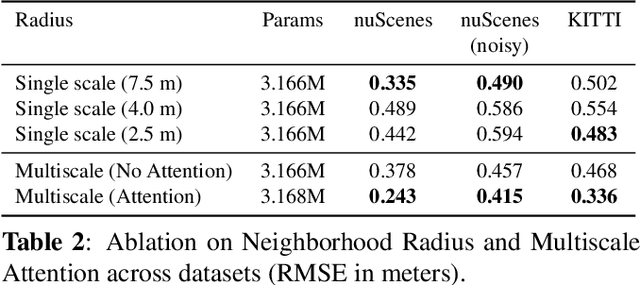

Point cloud registration (PCR) is crucial for many downstream tasks, such as simultaneous localization and mapping (SLAM) and object tracking. This makes detecting and quantifying registration misalignment, i.e.,~{\it PCR quality validation}, an important task. All existing methods treat validation as a classification task, aiming to assign the PCR quality to a few classes. In this work, we instead use regression for PCR validation, allowing for a more fine-grained quantification of the registration quality. We also extend previously used misalignment-related features by using multiscale extraction and attention-based aggregation. This leads to accurate and robust registration error estimation on diverse datasets, especially for point clouds with heterogeneous spatial densities. Furthermore, when used to guide a mapping downstream task, our method significantly improves the mapping quality for a given amount of re-registered frames, compared to the state-of-the-art classification-based method.
DisorientLiDAR: Physical Attacks on LiDAR-based Localization
Sep 16, 2025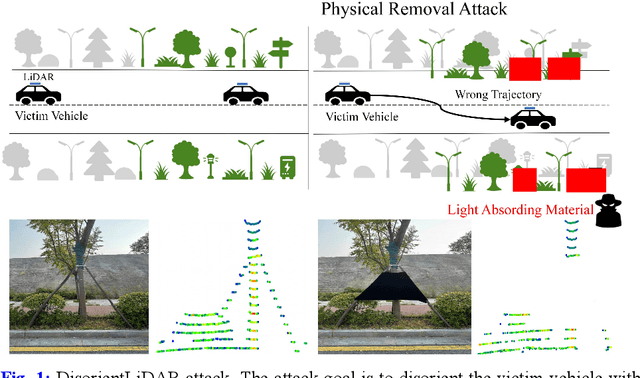
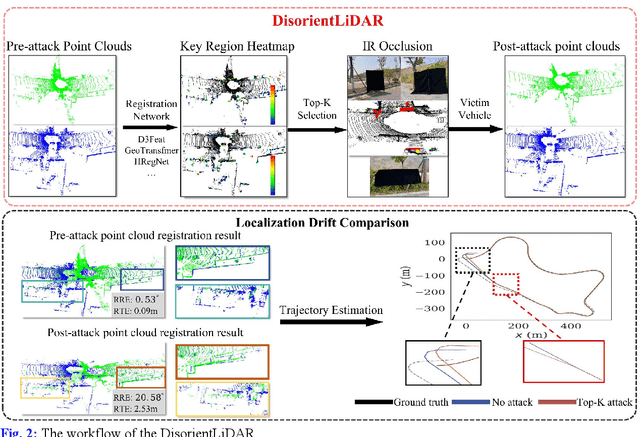
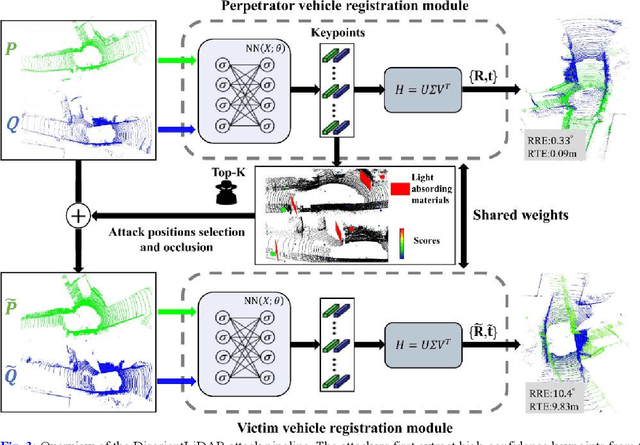
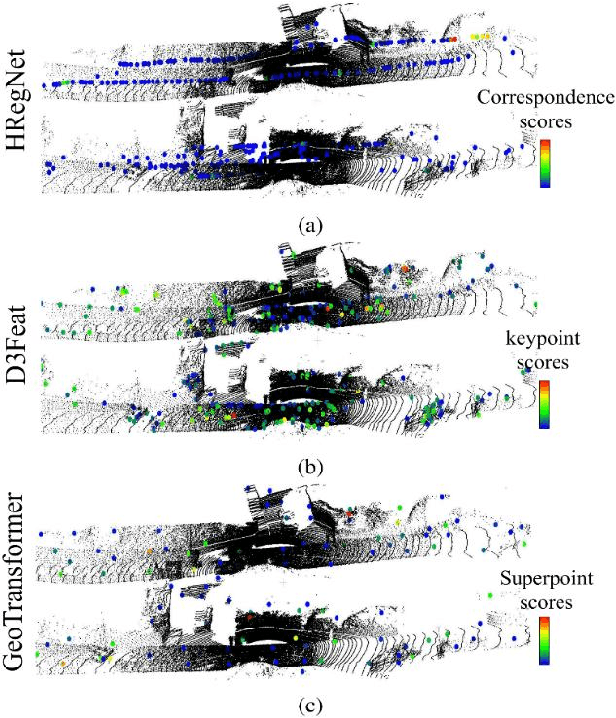
Deep learning models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Even this poses a serious security challenge for the localization of self-driving cars, there has been very little exploration of attack on it, as most of adversarial attacks have been applied to 3D perception. In this work, we propose a novel adversarial attack framework called DisorientLiDAR targeting LiDAR-based localization. By reverse-engineering localization models (e.g., feature extraction networks), adversaries can identify critical keypoints and strategically remove them, thereby disrupting LiDAR-based localization. Our proposal is first evaluated on three state-of-the-art point-cloud registration models (HRegNet, D3Feat, and GeoTransformer) using the KITTI dataset. Experimental results demonstrate that removing regions containing Top-K keypoints significantly degrades their registration accuracy. We further validate the attack's impact on the Autoware autonomous driving platform, where hiding merely a few critical regions induces noticeable localization drift. Finally, we extended our attacks to the physical world by hiding critical regions with near-infrared absorptive materials, thereby successfully replicate the attack effects observed in KITTI data. This step has been closer toward the realistic physical-world attack that demonstrate the veracity and generality of our proposal.
Robust Point Cloud Registration via Geometric Overlapping Guided Rotation Search
Aug 24, 2025Point cloud registration based on correspondences computes the rigid transformation that maximizes the number of inliers constrained within the noise threshold. Current state-of-the-art (SOTA) methods employing spatial compatibility graphs or branch-and-bound (BnB) search mainly focus on registration under high outlier ratios. However, graph-based methods require at least quadratic space and time complexity for graph construction, while multi-stage BnB search methods often suffer from inaccuracy due to local optima between decomposed stages. This paper proposes a geometric maximum overlapping registration framework via rotation-only BnB search. The rigid transformation is decomposed using Chasles' theorem into a translation along rotation axis and a 2D rigid transformation. The optimal rotation axis and angle are searched via BnB, with residual parameters formulated as range maximum query (RMQ) problems. Firstly, the top-k candidate rotation axes are searched within a hemisphere parameterized by cube mapping, and the translation along each axis is estimated through interval stabbing of the correspondences projected onto that axis. Secondly, the 2D registration is relaxed to 1D rotation angle search with 2D RMQ of geometric overlapping for axis-aligned rectangles, which is solved deterministically in polynomial time using sweep line algorithm with segment tree. Experimental results on 3DMatch, 3DLoMatch, and KITTI datasets demonstrate superior accuracy and efficiency over SOTA methods, while the time complexity is polynomial and the space complexity increases linearly with the number of points, even in the worst case.
Surfel-based 3D Registration with Equivariant SE(3) Features
Aug 28, 2025Point cloud registration is crucial for ensuring 3D alignment consistency of multiple local point clouds in 3D reconstruction for remote sensing or digital heritage. While various point cloud-based registration methods exist, both non-learning and learning-based, they ignore point orientations and point uncertainties, making the model susceptible to noisy input and aggressive rotations of the input point cloud like orthogonal transformation; thus, it necessitates extensive training point clouds with transformation augmentations. To address these issues, we propose a novel surfel-based pose learning regression approach. Our method can initialize surfels from Lidar point cloud using virtual perspective camera parameters, and learns explicit $\mathbf{SE(3)}$ equivariant features, including both position and rotation through $\mathbf{SE(3)}$ equivariant convolutional kernels to predict relative transformation between source and target scans. The model comprises an equivariant convolutional encoder, a cross-attention mechanism for similarity computation, a fully-connected decoder, and a non-linear Huber loss. Experimental results on indoor and outdoor datasets demonstrate our model superiority and robust performance on real point-cloud scans compared to state-of-the-art methods.
* 5 pages, 4 figures
Deep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
DuLoc: Life-Long Dual-Layer Localization in Changing and Dynamic Expansive Scenarios
Jul 31, 2025LiDAR-based localization serves as a critical component in autonomous systems, yet existing approaches face persistent challenges in balancing repeatability, accuracy, and environmental adaptability. Traditional point cloud registration methods relying solely on offline maps often exhibit limited robustness against long-term environmental changes, leading to localization drift and reliability degradation in dynamic real-world scenarios. To address these challenges, this paper proposes DuLoc, a robust and accurate localization method that tightly couples LiDAR-inertial odometry with offline map-based localization, incorporating a constant-velocity motion model to mitigate outlier noise in real-world scenarios. Specifically, we develop a LiDAR-based localization framework that seamlessly integrates a prior global map with dynamic real-time local maps, enabling robust localization in unbounded and changing environments. Extensive real-world experiments in ultra unbounded port that involve 2,856 hours of operational data across 32 Intelligent Guided Vehicles (IGVs) are conducted and reported in this study. The results attained demonstrate that our system outperforms other state-of-the-art LiDAR localization systems in large-scale changing outdoor environments.