 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
Are You Copying My Prompt? Protecting the Copyright of Vision Prompt for VPaaS via Watermark
May 24, 2024
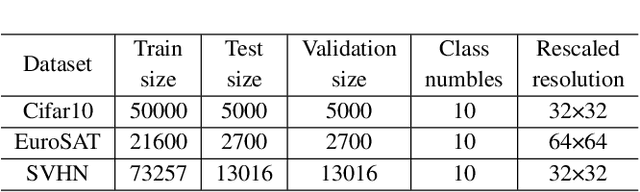
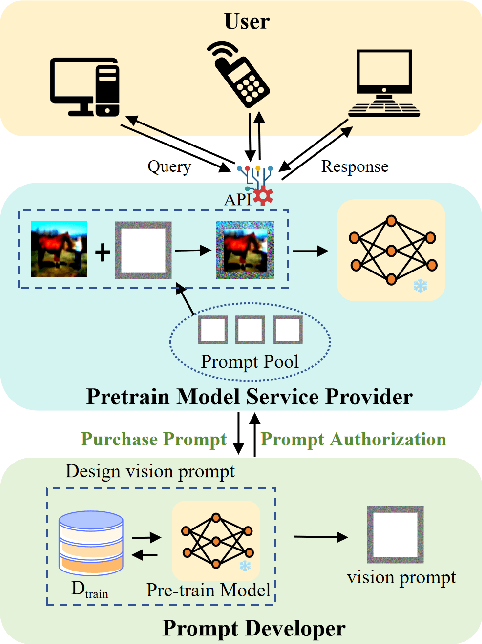
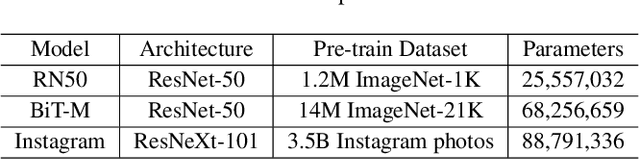
Visual Prompt Learning (VPL) differs from traditional fine-tuning methods in reducing significant resource consumption by avoiding updating pre-trained model parameters. Instead, it focuses on learning an input perturbation, a visual prompt, added to downstream task data for making predictions. Since learning generalizable prompts requires expert design and creation, which is technically demanding and time-consuming in the optimization process, developers of Visual Prompts as a Service (VPaaS) have emerged. These developers profit by providing well-crafted prompts to authorized customers. However, a significant drawback is that prompts can be easily copied and redistributed, threatening the intellectual property of VPaaS developers. Hence, there is an urgent need for technology to protect the rights of VPaaS developers. To this end, we present a method named \textbf{WVPrompt} that employs visual prompt watermarking in a black-box way. WVPrompt consists of two parts: prompt watermarking and prompt verification. Specifically, it utilizes a poison-only backdoor attack method to embed a watermark into the prompt and then employs a hypothesis-testing approach for remote verification of prompt ownership. Extensive experiments have been conducted on three well-known benchmark datasets using three popular pre-trained models: RN50, BIT-M, and Instagram. The experimental results demonstrate that WVPrompt is efficient, harmless, and robust to various adversarial operations.
JSMNet Improving Indoor Point Cloud Semantic and Instance Segmentation through Self-Attention and Multiscale
Sep 25, 2023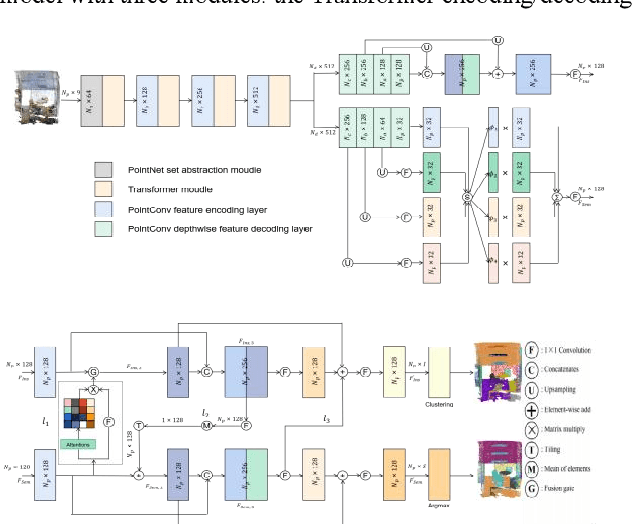
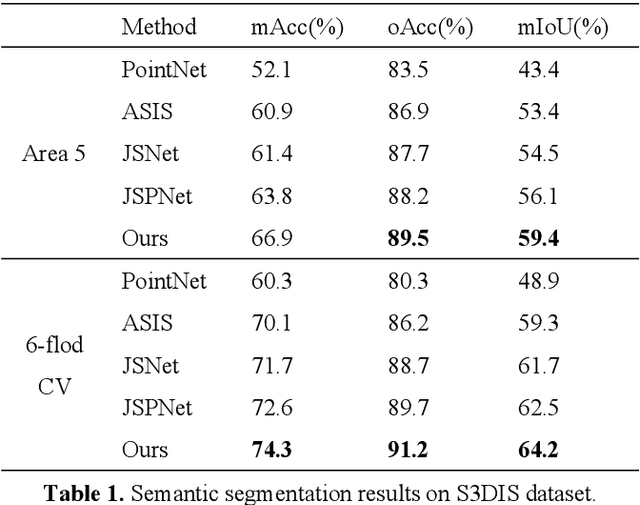
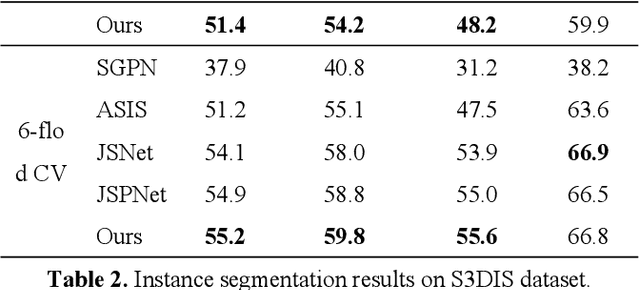
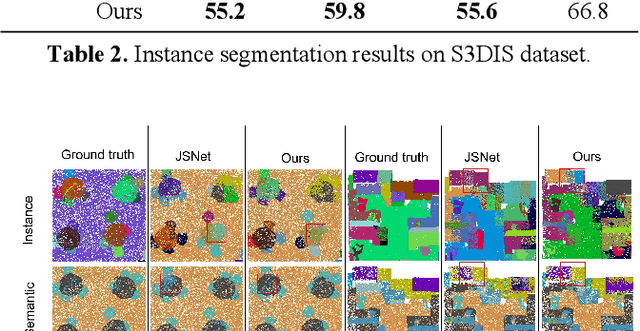
The semantic understanding of indoor 3D point cloud data is crucial for a range of subsequent applications, including indoor service robots, navigation systems, and digital twin engineering. Global features are crucial for achieving high-quality semantic and instance segmentation of indoor point clouds, as they provide essential long-range context information. To this end, we propose JSMNet, which combines a multi-layer network with a global feature self-attention module to jointly segment three-dimensional point cloud semantics and instances. To better express the characteristics of indoor targets, we have designed a multi-resolution feature adaptive fusion module that takes into account the differences in point cloud density caused by varying scanner distances from the target. Additionally, we propose a framework for joint semantic and instance segmentation by integrating semantic and instance features to achieve superior results. We conduct experiments on S3DIS, which is a large three-dimensional indoor point cloud dataset. Our proposed method is compared against other methods, and the results show that it outperforms existing methods in semantic and instance segmentation and provides better results in target local area segmentation. Specifically, our proposed method outperforms PointNet (Qi et al., 2017a) by 16.0% and 26.3% in terms of semantic segmentation mIoU in S3DIS (Area 5) and instance segmentation mPre, respectively. Additionally, it surpasses ASIS (Wang et al., 2019) by 6.0% and 4.6%, respectively, as well as JSPNet (Chen et al., 2022) by a margin of 3.3% for semantic segmentation mIoU and a slight improvement of 0.3% for instance segmentation mPre.
Research on self-cross transformer model of point cloud change detecter
Sep 14, 2023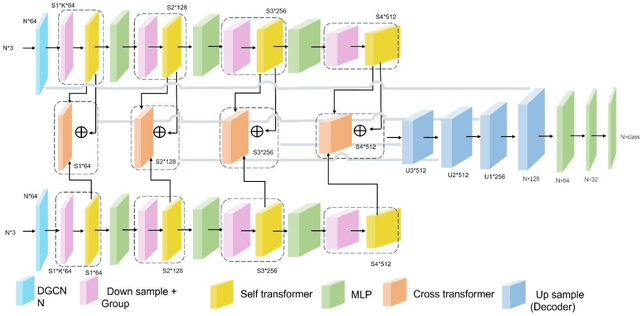

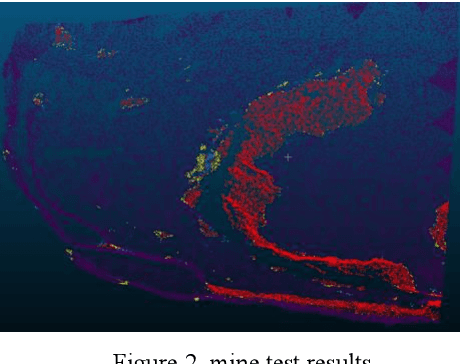
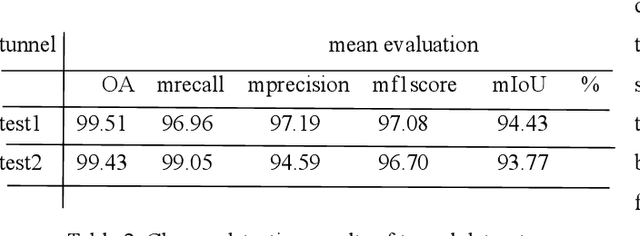
With the vigorous development of the urban construction industry, engineering deformation or changes often occur during the construction process. To combat this phenomenon, it is necessary to detect changes in order to detect construction loopholes in time, ensure the integrity of the project and reduce labor costs. Or the inconvenience and injuriousness of the road. In the study of change detection in 3D point clouds, researchers have published various research methods on 3D point clouds. Directly based on but mostly based ontraditional threshold distance methods (C2C, M3C2, M3C2-EP), and some are to convert 3D point clouds into DSM, which loses a lot of original information. Although deep learning is used in remote sensing methods, in terms of change detection of 3D point clouds, it is more converted into two-dimensional patches, and neural networks are rarely applied directly. We prefer that the network is given at the level of pixels or points. Variety. Therefore, in this article, our network builds a network for 3D point cloud change detection, and proposes a new module Cross transformer suitable for change detection. Simultaneously simulate tunneling data for change detection, and do test experiments with our network.