 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre You Copying My Prompt? Protecting the Copyright of Vision Prompt for VPaaS via Watermark
Paper and Code
May 24, 2024
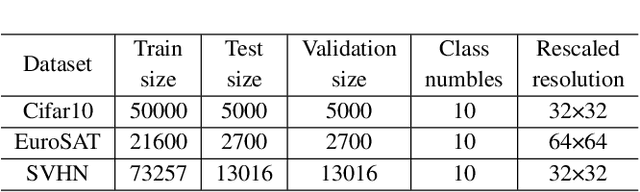
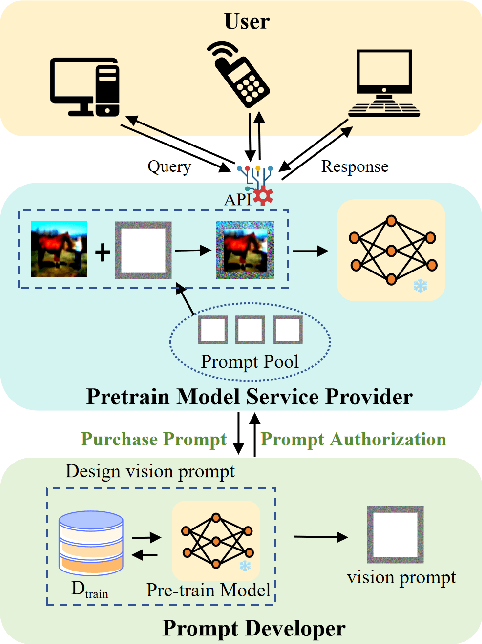
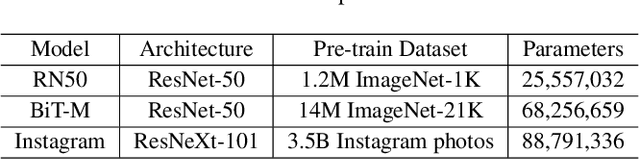
Visual Prompt Learning (VPL) differs from traditional fine-tuning methods in reducing significant resource consumption by avoiding updating pre-trained model parameters. Instead, it focuses on learning an input perturbation, a visual prompt, added to downstream task data for making predictions. Since learning generalizable prompts requires expert design and creation, which is technically demanding and time-consuming in the optimization process, developers of Visual Prompts as a Service (VPaaS) have emerged. These developers profit by providing well-crafted prompts to authorized customers. However, a significant drawback is that prompts can be easily copied and redistributed, threatening the intellectual property of VPaaS developers. Hence, there is an urgent need for technology to protect the rights of VPaaS developers. To this end, we present a method named \textbf{WVPrompt} that employs visual prompt watermarking in a black-box way. WVPrompt consists of two parts: prompt watermarking and prompt verification. Specifically, it utilizes a poison-only backdoor attack method to embed a watermark into the prompt and then employs a hypothesis-testing approach for remote verification of prompt ownership. Extensive experiments have been conducted on three well-known benchmark datasets using three popular pre-trained models: RN50, BIT-M, and Instagram. The experimental results demonstrate that WVPrompt is efficient, harmless, and robust to various adversarial operations.