 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3d Human Pose Estimation
3D Human Pose Estimation is a computer vision task that involves estimating the 3D positions and orientations of body joints and bones from 2D images or videos. The goal is to reconstruct the 3D pose of a person in real time, which can be used in a variety of applications, such as virtual reality, human-computer interaction, and motion analysis.
Papers and Code
SAP-CoPE: Social-Aware Planning using Cooperative Pose Estimation with Infrastructure Sensor Nodes
Apr 08, 2025



Autonomous driving systems must operate safely in human-populated indoor environments, where challenges such as limited perception and occlusion sensitivity arise when relying solely on onboard sensors. These factors generate difficulties in the accurate recognition of human intentions and the generation of comfortable, socially aware trajectories. To address these issues, we propose SAP-CoPE, a social-aware planning framework that integrates cooperative infrastructure with a novel 3D human pose estimation method and a model predictive control-based controller. This real-time framework formulates an optimization problem that accounts for uncertainty propagation in the camera projection matrix while ensuring human joint coherence. The proposed method is adaptable to single- or multi-camera configurations and can incorporate sparse LiDAR point-cloud data. To enhance safety and comfort in human environments, we integrate a human personal space field based on human pose into a model predictive controller, enabling the system to navigate while avoiding discomfort zones. Extensive evaluations in both simulated and real-world settings demonstrate the effectiveness of our approach in generating socially aware trajectories for autonomous systems.
DeProPose: Deficiency-Proof 3D Human Pose Estimation via Adaptive Multi-View Fusion
Feb 23, 2025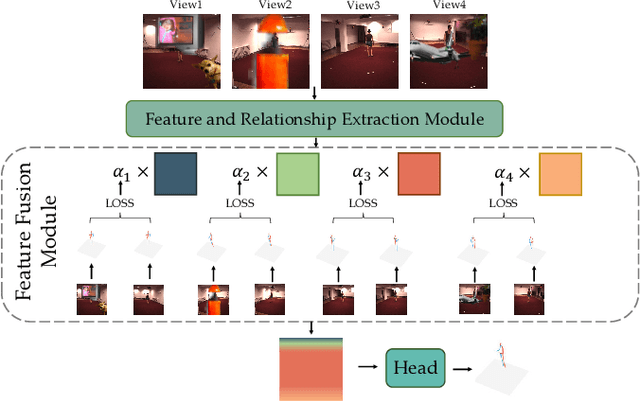
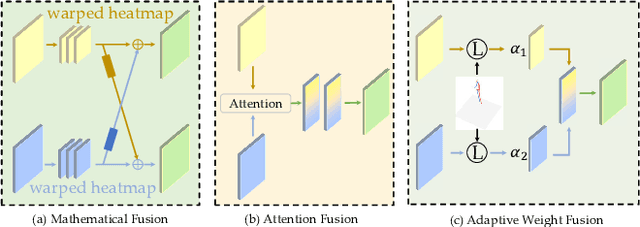
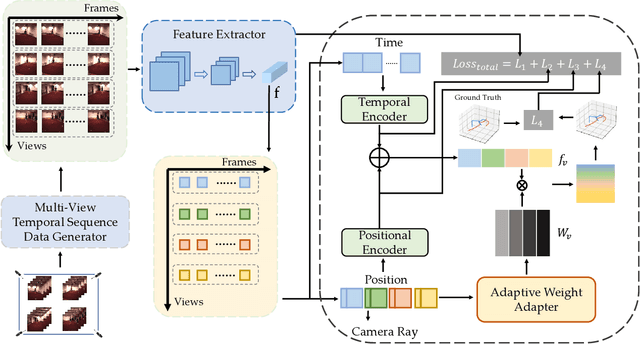
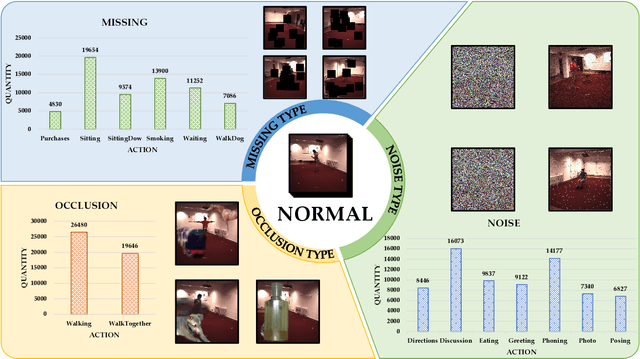
3D human pose estimation has wide applications in fields such as intelligent surveillance, motion capture, and virtual reality. However, in real-world scenarios, issues such as occlusion, noise interference, and missing viewpoints can severely affect pose estimation. To address these challenges, we introduce the task of Deficiency-Aware 3D Pose Estimation. Traditional 3D pose estimation methods often rely on multi-stage networks and modular combinations, which can lead to cumulative errors and increased training complexity, making them unable to effectively address deficiency-aware estimation. To this end, we propose DeProPose, a flexible method that simplifies the network architecture to reduce training complexity and avoid information loss in multi-stage designs. Additionally, the model innovatively introduces a multi-view feature fusion mechanism based on relative projection error, which effectively utilizes information from multiple viewpoints and dynamically assigns weights, enabling efficient integration and enhanced robustness to overcome deficiency-aware 3D Pose Estimation challenges. Furthermore, to thoroughly evaluate this end-to-end multi-view 3D human pose estimation model and to advance research on occlusion-related challenges, we have developed a novel 3D human pose estimation dataset, termed the Deficiency-Aware 3D Pose Estimation (DA-3DPE) dataset. This dataset encompasses a wide range of deficiency scenarios, including noise interference, missing viewpoints, and occlusion challenges. Compared to state-of-the-art methods, DeProPose not only excels in addressing the deficiency-aware problem but also shows improvement in conventional scenarios, providing a powerful and user-friendly solution for 3D human pose estimation. The source code will be available at https://github.com/WUJINHUAN/DeProPose.
AthletePose3D: A Benchmark Dataset for 3D Human Pose Estimation and Kinematic Validation in Athletic Movements
Mar 11, 2025Human pose estimation is a critical task in computer vision and sports biomechanics, with applications spanning sports science, rehabilitation, and biomechanical research. While significant progress has been made in monocular 3D pose estimation, current datasets often fail to capture the complex, high-acceleration movements typical of competitive sports. In this work, we introduce AthletePose3D, a novel dataset designed to address this gap. AthletePose3D includes 12 types of sports motions across various disciplines, with approximately 1.3 million frames and 165 thousand individual postures, specifically capturing high-speed, high-acceleration athletic movements. We evaluate state-of-the-art (SOTA) monocular 2D and 3D pose estimation models on the dataset, revealing that models trained on conventional datasets perform poorly on athletic motions. However, fine-tuning these models on AthletePose3D notably reduces the SOTA model mean per joint position error (MPJPE) from 214mm to 65mm-a reduction of over 69%. We also validate the kinematic accuracy of monocular pose estimations through waveform analysis, highlighting strong correlations in joint angle estimations but limitations in velocity estimation. Our work provides a comprehensive evaluation of monocular pose estimation models in the context of sports, contributing valuable insights for advancing monocular pose estimation techniques in high-performance sports environments. The dataset, code, and model checkpoints are available at: https://github.com/calvinyeungck/AthletePose3D
GenHPE: Generative Counterfactuals for 3D Human Pose Estimation with Radio Frequency Signals
Mar 12, 2025Human pose estimation (HPE) detects the positions of human body joints for various applications. Compared to using cameras, HPE using radio frequency (RF) signals is non-intrusive and more robust to adverse conditions, exploiting the signal variations caused by human interference. However, existing studies focus on single-domain HPE confined by domain-specific confounders, which cannot generalize to new domains and result in diminished HPE performance. Specifically, the signal variations caused by different human body parts are entangled, containing subject-specific confounders. RF signals are also intertwined with environmental noise, involving environment-specific confounders. In this paper, we propose GenHPE, a 3D HPE approach that generates counterfactual RF signals to eliminate domain-specific confounders. GenHPE trains generative models conditioned on human skeleton labels, learning how human body parts and confounders interfere with RF signals. We manipulate skeleton labels (i.e., removing body parts) as counterfactual conditions for generative models to synthesize counterfactual RF signals. The differences between counterfactual signals approximately eliminate domain-specific confounders and regularize an encoder-decoder model to learn domain-independent representations. Such representations help GenHPE generalize to new subjects/environments for cross-domain 3D HPE. We evaluate GenHPE on three public datasets from WiFi, ultra-wideband, and millimeter wave. Experimental results show that GenHPE outperforms state-of-the-art methods and reduces estimation errors by up to 52.2mm for cross-subject HPE and 10.6mm for cross-environment HPE.
P2P-Insole: Human Pose Estimation Using Foot Pressure Distribution and Motion Sensors
May 01, 2025This work presents P2P-Insole, a low-cost approach for estimating and visualizing 3D human skeletal data using insole-type sensors integrated with IMUs. Each insole, fabricated with e-textile garment techniques, costs under USD 1, making it significantly cheaper than commercial alternatives and ideal for large-scale production. Our approach uses foot pressure distribution, acceleration, and rotation data to overcome limitations, providing a lightweight, minimally intrusive, and privacy-aware solution. The system employs a Transformer model for efficient temporal feature extraction, enriched by first and second derivatives in the input stream. Including multimodal information, such as accelerometers and rotational measurements, improves the accuracy of complex motion pattern recognition. These facts are demonstrated experimentally, while error metrics show the robustness of the approach in various posture estimation tasks. This work could be the foundation for a low-cost, practical application in rehabilitation, injury prevention, and health monitoring while enabling further development through sensor optimization and expanded datasets.
Analyzing the Synthetic-to-Real Domain Gap in 3D Hand Pose Estimation
Mar 25, 2025



Recent synthetic 3D human datasets for the face, body, and hands have pushed the limits on photorealism. Face recognition and body pose estimation have achieved state-of-the-art performance using synthetic training data alone, but for the hand, there is still a large synthetic-to-real gap. This paper presents the first systematic study of the synthetic-to-real gap of 3D hand pose estimation. We analyze the gap and identify key components such as the forearm, image frequency statistics, hand pose, and object occlusions. To facilitate our analysis, we propose a data synthesis pipeline to synthesize high-quality data. We demonstrate that synthetic hand data can achieve the same level of accuracy as real data when integrating our identified components, paving the path to use synthetic data alone for hand pose estimation. Code and data are available at: https://github.com/delaprada/HandSynthesis.git.
UA-Pose: Uncertainty-Aware 6D Object Pose Estimation and Online Object Completion with Partial References
Jun 09, 2025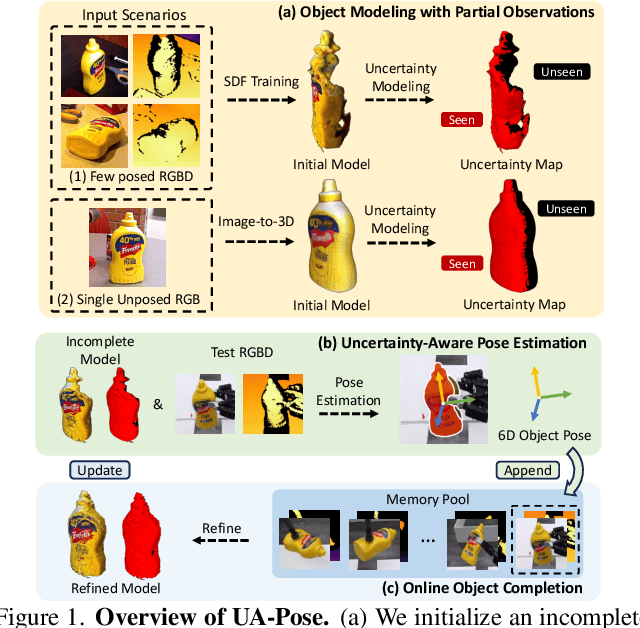

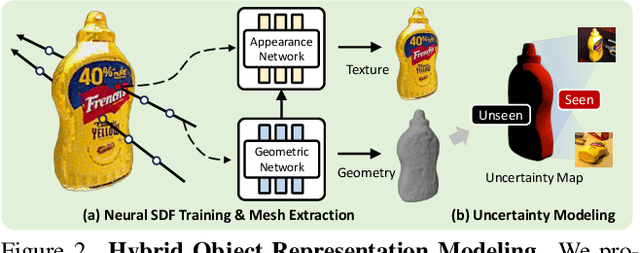

6D object pose estimation has shown strong generalizability to novel objects. However, existing methods often require either a complete, well-reconstructed 3D model or numerous reference images that fully cover the object. Estimating 6D poses from partial references, which capture only fragments of an object's appearance and geometry, remains challenging. To address this, we propose UA-Pose, an uncertainty-aware approach for 6D object pose estimation and online object completion specifically designed for partial references. We assume access to either (1) a limited set of RGBD images with known poses or (2) a single 2D image. For the first case, we initialize a partial object 3D model based on the provided images and poses, while for the second, we use image-to-3D techniques to generate an initial object 3D model. Our method integrates uncertainty into the incomplete 3D model, distinguishing between seen and unseen regions. This uncertainty enables confidence assessment in pose estimation and guides an uncertainty-aware sampling strategy for online object completion, enhancing robustness in pose estimation accuracy and improving object completeness. We evaluate our method on the YCB-Video, YCBInEOAT, and HO3D datasets, including RGBD sequences of YCB objects manipulated by robots and human hands. Experimental results demonstrate significant performance improvements over existing methods, particularly when object observations are incomplete or partially captured. Project page: https://minfenli.github.io/UA-Pose/
FinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
May 19, 2025Despite significant advances in video generation, synthesizing physically plausible human actions remains a persistent challenge, particularly in modeling fine-grained semantics and complex temporal dynamics. For instance, generating gymnastics routines such as "switch leap with 0.5 turn" poses substantial difficulties for current methods, often yielding unsatisfactory results. To bridge this gap, we propose FinePhys, a Fine-grained human action generation framework that incorporates Physics to obtain effective skeletal guidance. Specifically, FinePhys first estimates 2D poses in an online manner and then performs 2D-to-3D dimension lifting via in-context learning. To mitigate the instability and limited interpretability of purely data-driven 3D poses, we further introduce a physics-based motion re-estimation module governed by Euler-Lagrange equations, calculating joint accelerations via bidirectional temporal updating. The physically predicted 3D poses are then fused with data-driven ones, offering multi-scale 2D heatmap guidance for the diffusion process. Evaluated on three fine-grained action subsets from FineGym (FX-JUMP, FX-TURN, and FX-SALTO), FinePhys significantly outperforms competitive baselines. Comprehensive qualitative results further demonstrate FinePhys's ability to generate more natural and plausible fine-grained human actions.
ODHSR: Online Dense 3D Reconstruction of Humans and Scenes from Monocular Videos
Apr 18, 2025Creating a photorealistic scene and human reconstruction from a single monocular in-the-wild video figures prominently in the perception of a human-centric 3D world. Recent neural rendering advances have enabled holistic human-scene reconstruction but require pre-calibrated camera and human poses, and days of training time. In this work, we introduce a novel unified framework that simultaneously performs camera tracking, human pose estimation and human-scene reconstruction in an online fashion. 3D Gaussian Splatting is utilized to learn Gaussian primitives for humans and scenes efficiently, and reconstruction-based camera tracking and human pose estimation modules are designed to enable holistic understanding and effective disentanglement of pose and appearance. Specifically, we design a human deformation module to reconstruct the details and enhance generalizability to out-of-distribution poses faithfully. Aiming to learn the spatial correlation between human and scene accurately, we introduce occlusion-aware human silhouette rendering and monocular geometric priors, which further improve reconstruction quality. Experiments on the EMDB and NeuMan datasets demonstrate superior or on-par performance with existing methods in camera tracking, human pose estimation, novel view synthesis and runtime. Our project page is at https://eth-ait.github.io/ODHSR.
Human Motion Prediction via Test-domain-aware Adaptation with Easily-available Human Motions Estimated from Videos
May 13, 2025In 3D Human Motion Prediction (HMP), conventional methods train HMP models with expensive motion capture data. However, the data collection cost of such motion capture data limits the data diversity, which leads to poor generalizability to unseen motions or subjects. To address this issue, this paper proposes to enhance HMP with additional learning using estimated poses from easily available videos. The 2D poses estimated from the monocular videos are carefully transformed into motion capture-style 3D motions through our pipeline. By additional learning with the obtained motions, the HMP model is adapted to the test domain. The experimental results demonstrate the quantitative and qualitative impact of our method.