 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Open Vocabulary Instance Segmentation
Papers and Code
Retrieving Objects from 3D Scenes with Box-Guided Open-Vocabulary Instance Segmentation
Dec 22, 2025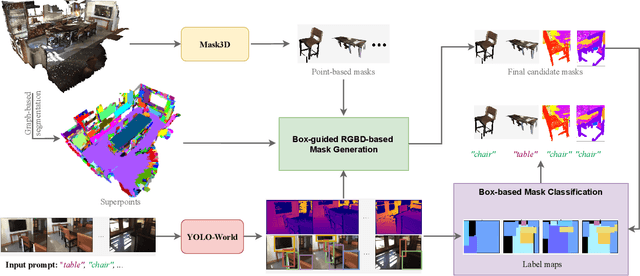



Locating and retrieving objects from scene-level point clouds is a challenging problem with broad applications in robotics and augmented reality. This task is commonly formulated as open-vocabulary 3D instance segmentation. Although recent methods demonstrate strong performance, they depend heavily on SAM and CLIP to generate and classify 3D instance masks from images accompanying the point cloud, leading to substantial computational overhead and slow processing that limit their deployment in real-world settings. Open-YOLO 3D alleviates this issue by using a real-time 2D detector to classify class-agnostic masks produced directly from the point cloud by a pretrained 3D segmenter, eliminating the need for SAM and CLIP and significantly reducing inference time. However, Open-YOLO 3D often fails to generalize to object categories that appear infrequently in the 3D training data. In this paper, we propose a method that generates 3D instance masks for novel objects from RGB images guided by a 2D open-vocabulary detector. Our approach inherits the 2D detector's ability to recognize novel objects while maintaining efficient classification, enabling fast and accurate retrieval of rare instances from open-ended text queries. Our code will be made available at https://github.com/ndkhanh360/BoxOVIS.
Unified Semantic Transformer for 3D Scene Understanding
Dec 18, 2025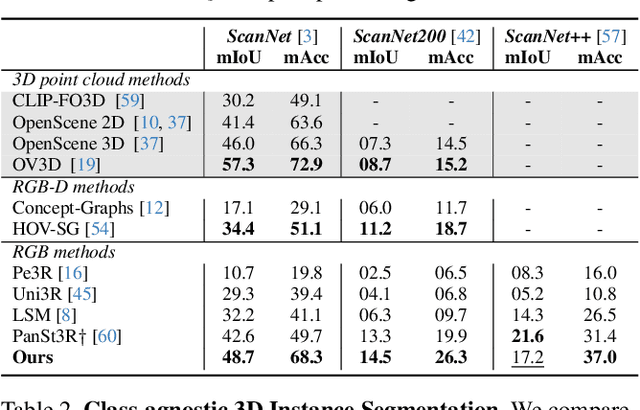
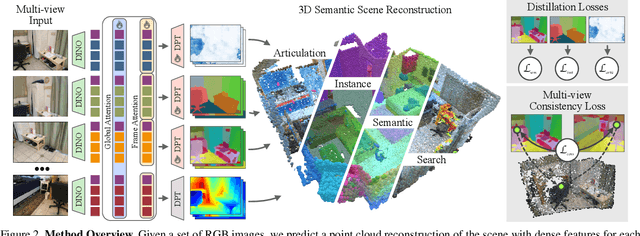
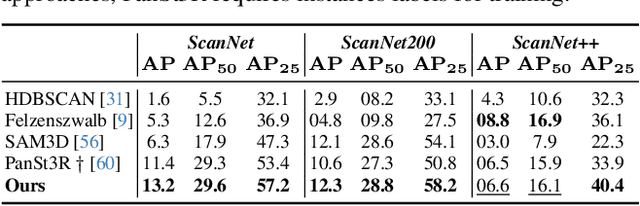
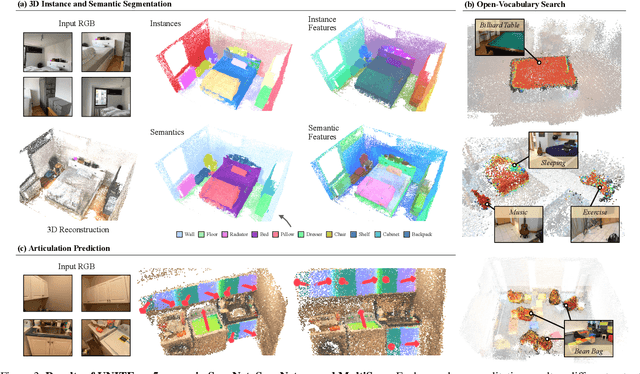
Holistic 3D scene understanding involves capturing and parsing unstructured 3D environments. Due to the inherent complexity of the real world, existing models have predominantly been developed and limited to be task-specific. We introduce UNITE, a Unified Semantic Transformer for 3D scene understanding, a novel feed-forward neural network that unifies a diverse set of 3D semantic tasks within a single model. Our model operates on unseen scenes in a fully end-to-end manner and only takes a few seconds to infer the full 3D semantic geometry. Our approach is capable of directly predicting multiple semantic attributes, including 3D scene segmentation, instance embeddings, open-vocabulary features, as well as affordance and articulations, solely from RGB images. The method is trained using a combination of 2D distillation, heavily relying on self-supervision and leverages novel multi-view losses designed to ensure 3D view consistency. We demonstrate that UNITE achieves state-of-the-art performance on several different semantic tasks and even outperforms task-specific models, in many cases, surpassing methods that operate on ground truth 3D geometry. See the project website at unite-page.github.io
Chorus: Multi-Teacher Pretraining for Holistic 3D Gaussian Scene Encoding
Dec 22, 2025While 3DGS has emerged as a high-fidelity scene representation, encoding rich, general-purpose features directly from its primitives remains under-explored. We address this gap by introducing Chorus, a multi-teacher pretraining framework that learns a holistic feed-forward 3D Gaussian Splatting (3DGS) scene encoder by distilling complementary signals from 2D foundation models. Chorus employs a shared 3D encoder and teacher-specific projectors to learn from language-aligned, generalist, and object-aware teachers, encouraging a shared embedding space that captures signals from high-level semantics to fine-grained structure. We evaluate Chorus on a wide range of tasks: open-vocabulary semantic and instance segmentation, linear and decoder probing, as well as data-efficient supervision. Besides 3DGS, we also test Chorus on several benchmarks that only support point clouds by pretraining a variant using only Gaussians' centers, colors, estimated normals as inputs. Interestingly, this encoder shows strong transfer and outperforms the point clouds baseline while using 39.9 times fewer training scenes. Finally, we propose a render-and-distill adaptation that facilitates out-of-domain finetuning. Our code and model will be released upon publication.
Consistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025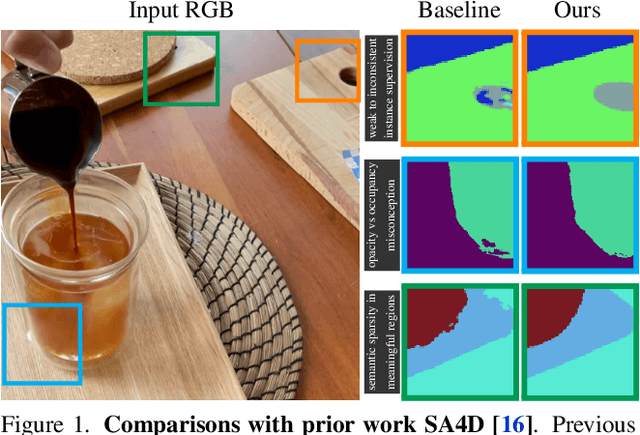
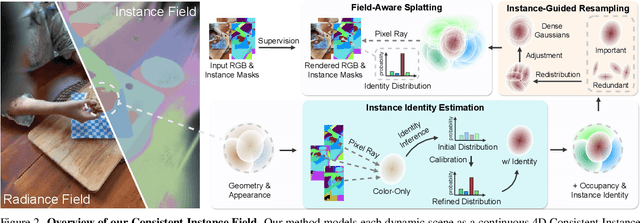
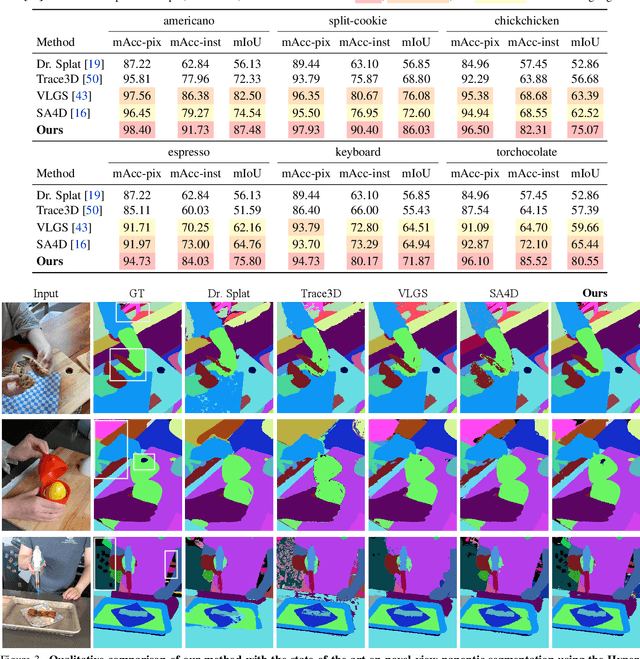
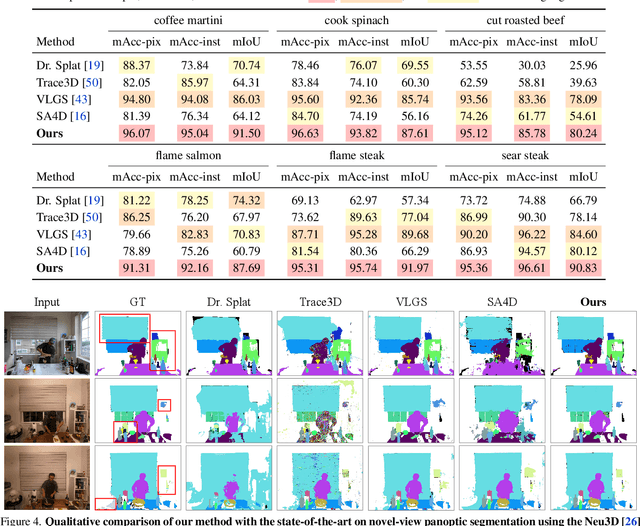
We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
OmniMap: A General Mapping Framework Integrating Optics, Geometry, and Semantics
Sep 09, 2025Robotic systems demand accurate and comprehensive 3D environment perception, requiring simultaneous capture of photo-realistic appearance (optical), precise layout shape (geometric), and open-vocabulary scene understanding (semantic). Existing methods typically achieve only partial fulfillment of these requirements while exhibiting optical blurring, geometric irregularities, and semantic ambiguities. To address these challenges, we propose OmniMap. Overall, OmniMap represents the first online mapping framework that simultaneously captures optical, geometric, and semantic scene attributes while maintaining real-time performance and model compactness. At the architectural level, OmniMap employs a tightly coupled 3DGS-Voxel hybrid representation that combines fine-grained modeling with structural stability. At the implementation level, OmniMap identifies key challenges across different modalities and introduces several innovations: adaptive camera modeling for motion blur and exposure compensation, hybrid incremental representation with normal constraints, and probabilistic fusion for robust instance-level understanding. Extensive experiments show OmniMap's superior performance in rendering fidelity, geometric accuracy, and zero-shot semantic segmentation compared to state-of-the-art methods across diverse scenes. The framework's versatility is further evidenced through a variety of downstream applications, including multi-domain scene Q&A, interactive editing, perception-guided manipulation, and map-assisted navigation.
OpenSplat3D: Open-Vocabulary 3D Instance Segmentation using Gaussian Splatting
Jun 09, 20253D Gaussian Splatting (3DGS) has emerged as a powerful representation for neural scene reconstruction, offering high-quality novel view synthesis while maintaining computational efficiency. In this paper, we extend the capabilities of 3DGS beyond pure scene representation by introducing an approach for open-vocabulary 3D instance segmentation without requiring manual labeling, termed OpenSplat3D. Our method leverages feature-splatting techniques to associate semantic information with individual Gaussians, enabling fine-grained scene understanding. We incorporate Segment Anything Model instance masks with a contrastive loss formulation as guidance for the instance features to achieve accurate instance-level segmentation. Furthermore, we utilize language embeddings of a vision-language model, allowing for flexible, text-driven instance identification. This combination enables our system to identify and segment arbitrary objects in 3D scenes based on natural language descriptions. We show results on LERF-mask and LERF-OVS as well as the full ScanNet++ validation set, demonstrating the effectiveness of our approach.
OV-MAP : Open-Vocabulary Zero-Shot 3D Instance Segmentation Map for Robots
Jun 13, 2025We introduce OV-MAP, a novel approach to open-world 3D mapping for mobile robots by integrating open-features into 3D maps to enhance object recognition capabilities. A significant challenge arises when overlapping features from adjacent voxels reduce instance-level precision, as features spill over voxel boundaries, blending neighboring regions together. Our method overcomes this by employing a class-agnostic segmentation model to project 2D masks into 3D space, combined with a supplemented depth image created by merging raw and synthetic depth from point clouds. This approach, along with a 3D mask voting mechanism, enables accurate zero-shot 3D instance segmentation without relying on 3D supervised segmentation models. We assess the effectiveness of our method through comprehensive experiments on public datasets such as ScanNet200 and Replica, demonstrating superior zero-shot performance, robustness, and adaptability across diverse environments. Additionally, we conducted real-world experiments to demonstrate our method's adaptability and robustness when applied to diverse real-world environments.
NVSMask3D: Hard Visual Prompting with Camera Pose Interpolation for 3D Open Vocabulary Instance Segmentation
Apr 20, 2025Vision-language models (VLMs) have demonstrated impressive zero-shot transfer capabilities in image-level visual perception tasks. However, they fall short in 3D instance-level segmentation tasks that require accurate localization and recognition of individual objects. To bridge this gap, we introduce a novel 3D Gaussian Splatting based hard visual prompting approach that leverages camera interpolation to generate diverse viewpoints around target objects without any 2D-3D optimization or fine-tuning. Our method simulates realistic 3D perspectives, effectively augmenting existing hard visual prompts by enforcing geometric consistency across viewpoints. This training-free strategy seamlessly integrates with prior hard visual prompts, enriching object-descriptive features and enabling VLMs to achieve more robust and accurate 3D instance segmentation in diverse 3D scenes.
A Neural Representation Framework with LLM-Driven Spatial Reasoning for Open-Vocabulary 3D Visual Grounding
Jul 09, 2025



Open-vocabulary 3D visual grounding aims to localize target objects based on free-form language queries, which is crucial for embodied AI applications such as autonomous navigation, robotics, and augmented reality. Learning 3D language fields through neural representations enables accurate understanding of 3D scenes from limited viewpoints and facilitates the localization of target objects in complex environments. However, existing language field methods struggle to accurately localize instances using spatial relations in language queries, such as ``the book on the chair.'' This limitation mainly arises from inadequate reasoning about spatial relations in both language queries and 3D scenes. In this work, we propose SpatialReasoner, a novel neural representation-based framework with large language model (LLM)-driven spatial reasoning that constructs a visual properties-enhanced hierarchical feature field for open-vocabulary 3D visual grounding. To enable spatial reasoning in language queries, SpatialReasoner fine-tunes an LLM to capture spatial relations and explicitly infer instructions for the target, anchor, and spatial relation. To enable spatial reasoning in 3D scenes, SpatialReasoner incorporates visual properties (opacity and color) to construct a hierarchical feature field. This field represents language and instance features using distilled CLIP features and masks extracted via the Segment Anything Model (SAM). The field is then queried using the inferred instructions in a hierarchical manner to localize the target 3D instance based on the spatial relation in the language query. Extensive experiments show that our framework can be seamlessly integrated into different neural representations, outperforming baseline models in 3D visual grounding while empowering their spatial reasoning capability.
Cues3D: Unleashing the Power of Sole NeRF for Consistent and Unique Instances in Open-Vocabulary 3D Panoptic Segmentation
May 01, 2025Open-vocabulary 3D panoptic segmentation has recently emerged as a significant trend. Top-performing methods currently integrate 2D segmentation with geometry-aware 3D primitives. However, the advantage would be lost without high-fidelity 3D point clouds, such as methods based on Neural Radiance Field (NeRF). These methods are limited by the insufficient capacity to maintain consistency across partial observations. To address this, recent works have utilized contrastive loss or cross-view association pre-processing for view consensus. In contrast to them, we present Cues3D, a compact approach that relies solely on NeRF instead of pre-associations. The core idea is that NeRF's implicit 3D field inherently establishes a globally consistent geometry, enabling effective object distinction without explicit cross-view supervision. We propose a three-phase training framework for NeRF, initialization-disambiguation-refinement, whereby the instance IDs are corrected using the initially-learned knowledge. Additionally, an instance disambiguation method is proposed to match NeRF-rendered 3D masks and ensure globally unique 3D instance identities. With the aid of Cues3D, we obtain highly consistent and unique 3D instance ID for each object across views with a balanced version of NeRF. Our experiments are conducted on ScanNet v2, ScanNet200, ScanNet++, and Replica datasets for 3D instance, panoptic, and semantic segmentation tasks. Cues3D outperforms other 2D image-based methods and competes with the latest 2D-3D merging based methods, while even surpassing them when using additional 3D point clouds. The code link could be found in the appendix and will be released on \href{https://github.com/mRobotit/Cues3D}{github}