 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
May 20, 2026Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts in latent user attributes, causing user drift where the implicit simulated population differs across treatment conditions, potentially distorting effect estimates. We formalize the confounding or selection bias that can arise due to user drift and show how intervention-dependent shifts can inflate or attenuate observed differences in user responses under intervention. To diagnose confounding, we propose using negative control outcomes--attributes that should remain invariant under intervention--to identify distribution shifts across intervention conditions, providing evidence of user drift. To mitigate drift, we study adjusting the persona specification by eliciting additional confounders, finding that targeted, setting-relevant confounders can substantially reduce bias across survey-style and multi-turn agent evaluations.
Deconfounding Scores and Representation Learning for Causal Effect Estimation with Weak Overlap
Apr 01, 2026Overlap, also known as positivity, is a key condition for causal treatment effect estimation. Many popular estimators suffer from high variance and become brittle when features differ strongly across treatment groups. This is especially challenging in high dimensions: the curse of dimensionality can make overlap implausible. To address this, we propose a class of feature representations called deconfounding scores, which preserve both identification and the target of estimation; the classical propensity and prognostic scores are two special cases. We characterize the problem of finding a representation with better overlap as minimizing an overlap divergence under a deconfounding score constraint. We then derive closed-form expressions for a class of deconfounding scores under a broad family of generalized linear models with Gaussian features and show that prognostic scores are overlap-optimal within this class. We conduct extensive experiments to assess this behavior empirically.
Understanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
When Can Proxies Improve the Sample Complexity of Preference Learning?
Dec 21, 2024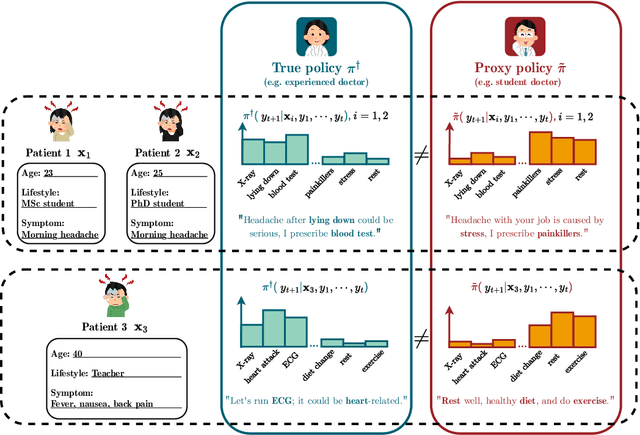
We address the problem of reward hacking, where maximising a proxy reward does not necessarily increase the true reward. This is a key concern for Large Language Models (LLMs), as they are often fine-tuned on human preferences that may not accurately reflect a true objective. Existing work uses various tricks such as regularisation, tweaks to the reward model, and reward hacking detectors, to limit the influence that such proxy preferences have on a model. Luckily, in many contexts such as medicine, education, and law, a sparse amount of expert data is often available. In these cases, it is often unclear whether the addition of proxy data can improve policy learning. We outline a set of sufficient conditions on proxy feedback that, if satisfied, indicate that proxy data can provably improve the sample complexity of learning the ground truth policy. These conditions can inform the data collection process for specific tasks. The result implies a parameterisation for LLMs that achieves this improved sample complexity. We detail how one can adapt existing architectures to yield this improved sample complexity.
Mind the Graph When Balancing Data for Fairness or Robustness
Jun 25, 2024



Failures of fairness or robustness in machine learning predictive settings can be due to undesired dependencies between covariates, outcomes and auxiliary factors of variation. A common strategy to mitigate these failures is data balancing, which attempts to remove those undesired dependencies. In this work, we define conditions on the training distribution for data balancing to lead to fair or robust models. Our results display that, in many cases, the balanced distribution does not correspond to selectively removing the undesired dependencies in a causal graph of the task, leading to multiple failure modes and even interference with other mitigation techniques such as regularization. Overall, our results highlight the importance of taking the causal graph into account before performing data balancing.
The Impossibility of Fair LLMs
May 28, 2024The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
Proxy Methods for Domain Adaptation
Mar 12, 2024We study the problem of domain adaptation under distribution shift, where the shift is due to a change in the distribution of an unobserved, latent variable that confounds both the covariates and the labels. In this setting, neither the covariate shift nor the label shift assumptions apply. Our approach to adaptation employs proximal causal learning, a technique for estimating causal effects in settings where proxies of unobserved confounders are available. We demonstrate that proxy variables allow for adaptation to distribution shift without explicitly recovering or modeling latent variables. We consider two settings, (i) Concept Bottleneck: an additional ''concept'' variable is observed that mediates the relationship between the covariates and labels; (ii) Multi-domain: training data from multiple source domains is available, where each source domain exhibits a different distribution over the latent confounder. We develop a two-stage kernel estimation approach to adapt to complex distribution shifts in both settings. In our experiments, we show that our approach outperforms other methods, notably those which explicitly recover the latent confounder.
CLIP the Bias: How Useful is Balancing Data in Multimodal Learning?
Mar 07, 2024



We study the effectiveness of data-balancing for mitigating biases in contrastive language-image pretraining (CLIP), identifying areas of strength and limitation. First, we reaffirm prior conclusions that CLIP models can inadvertently absorb societal stereotypes. To counter this, we present a novel algorithm, called Multi-Modal Moment Matching (M4), designed to reduce both representation and association biases (i.e. in first- and second-order statistics) in multimodal data. We use M4 to conduct an in-depth analysis taking into account various factors, such as the model, representation, and data size. Our study also explores the dynamic nature of how CLIP learns and unlearns biases. In particular, we find that fine-tuning is effective in countering representation biases, though its impact diminishes for association biases. Also, data balancing has a mixed impact on quality: it tends to improve classification but can hurt retrieval. Interestingly, data and architectural improvements seem to mitigate the negative impact of data balancing on performance; e.g. applying M4 to SigLIP-B/16 with data quality filters improves COCO image-to-text retrieval @5 from 86% (without data balancing) to 87% and ImageNet 0-shot classification from 77% to 77.5%! Finally, we conclude with recommendations for improving the efficacy of data balancing in multimodal systems.
* 32 pages, 20 figures, 7 tables
Bias in Language Models: Beyond Trick Tests and Toward RUTEd Evaluation
Feb 20, 2024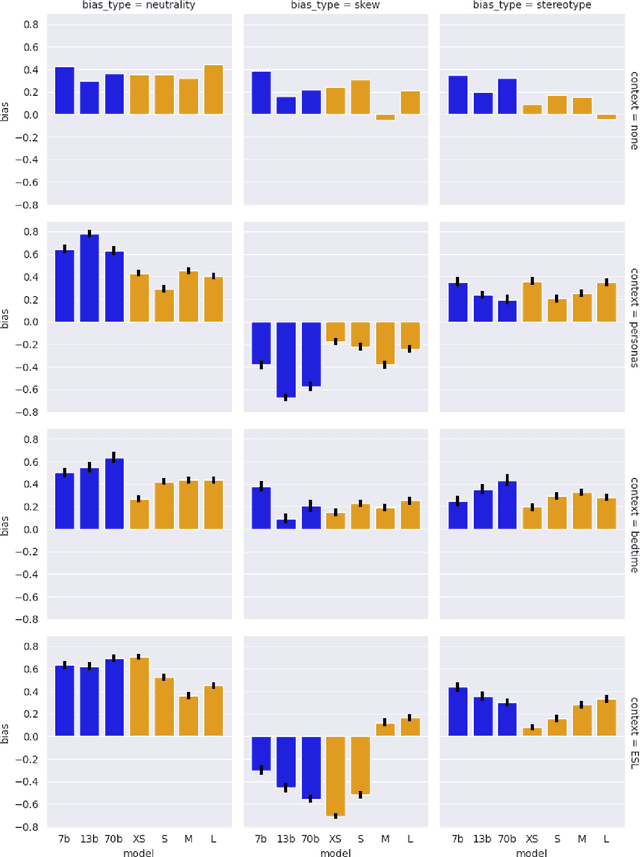
Bias benchmarks are a popular method for studying the negative impacts of bias in LLMs, yet there has been little empirical investigation of whether these benchmarks are actually indicative of how real world harm may manifest in the real world. In this work, we study the correspondence between such decontextualized "trick tests" and evaluations that are more grounded in Realistic Use and Tangible {Effects (i.e. RUTEd evaluations). We explore this correlation in the context of gender-occupation bias--a popular genre of bias evaluation. We compare three de-contextualized evaluations adapted from the current literature to three analogous RUTEd evaluations applied to long-form content generation. We conduct each evaluation for seven instruction-tuned LLMs. For the RUTEd evaluations, we conduct repeated trials of three text generation tasks: children's bedtime stories, user personas, and English language learning exercises. We found no correspondence between trick tests and RUTEd evaluations. Specifically, selecting the least biased model based on the de-contextualized results coincides with selecting the model with the best performance on RUTEd evaluations only as often as random chance. We conclude that evaluations that are not based in realistic use are likely insufficient to mitigate and assess bias and real-world harms.
Predictive Churn with the Set of Good Models
Feb 12, 2024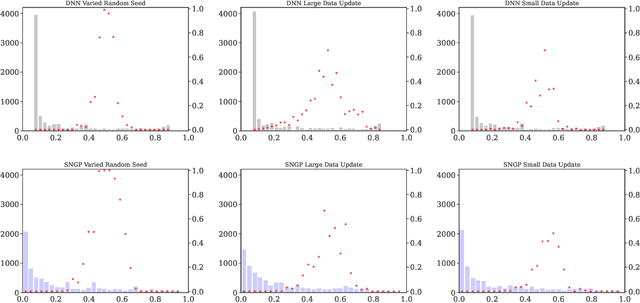

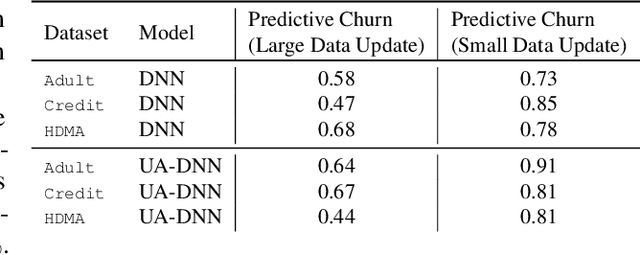
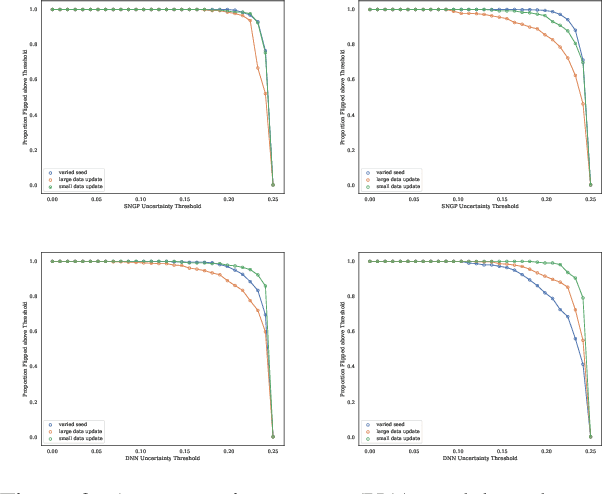
Machine learning models in modern mass-market applications are often updated over time. One of the foremost challenges faced is that, despite increasing overall performance, these updates may flip specific model predictions in unpredictable ways. In practice, researchers quantify the number of unstable predictions between models pre and post update -- i.e., predictive churn. In this paper, we study this effect through the lens of predictive multiplicity -- i.e., the prevalence of conflicting predictions over the set of near-optimal models (the Rashomon set). We show how traditional measures of predictive multiplicity can be used to examine expected churn over this set of prospective models -- i.e., the set of models that may be used to replace a baseline model in deployment. We present theoretical results on the expected churn between models within the Rashomon set from different perspectives. And we characterize expected churn over model updates via the Rashomon set, pairing our analysis with empirical results on real-world datasets -- showing how our approach can be used to better anticipate, reduce, and avoid churn in consumer-facing applications. Further, we show that our approach is useful even for models enhanced with uncertainty awareness.