 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3d Human Pose Estimation
3D Human Pose Estimation is a computer vision task that involves estimating the 3D positions and orientations of body joints and bones from 2D images or videos. The goal is to reconstruct the 3D pose of a person in real time, which can be used in a variety of applications, such as virtual reality, human-computer interaction, and motion analysis.
Papers and Code
RopeTP: Global Human Motion Recovery via Integrating Robust Pose Estimation with Diffusion Trajectory Prior
Oct 27, 2024



We present RopeTP, a novel framework that combines Robust pose estimation with a diffusion Trajectory Prior to reconstruct global human motion from videos. At the heart of RopeTP is a hierarchical attention mechanism that significantly improves context awareness, which is essential for accurately inferring the posture of occluded body parts. This is achieved by exploiting the relationships with visible anatomical structures, enhancing the accuracy of local pose estimations. The improved robustness of these local estimations allows for the reconstruction of precise and stable global trajectories. Additionally, RopeTP incorporates a diffusion trajectory model that predicts realistic human motion from local pose sequences. This model ensures that the generated trajectories are not only consistent with observed local actions but also unfold naturally over time, thereby improving the realism and stability of 3D human motion reconstruction. Extensive experimental validation shows that RopeTP surpasses current methods on two benchmark datasets, particularly excelling in scenarios with occlusions. It also outperforms methods that rely on SLAM for initial camera estimates and extensive optimization, delivering more accurate and realistic trajectories.
Can Generative Video Models Help Pose Estimation?
Dec 20, 2024Pairwise pose estimation from images with little or no overlap is an open challenge in computer vision. Existing methods, even those trained on large-scale datasets, struggle in these scenarios due to the lack of identifiable correspondences or visual overlap. Inspired by the human ability to infer spatial relationships from diverse scenes, we propose a novel approach, InterPose, that leverages the rich priors encoded within pre-trained generative video models. We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense, visual transition, which significantly simplifies the problem of pose estimation. Since current video models can still produce implausible motion or inconsistent geometry, we introduce a self-consistency score that evaluates the consistency of pose predictions from sampled videos. We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R on four diverse datasets encompassing indoor, outdoor, and object-centric scenes. Our findings suggest a promising avenue for improving pose estimation models by leveraging large generative models trained on vast amounts of video data, which is more readily available than 3D data. See our project page for results: https://inter-pose.github.io/.
FreeCap: Hybrid Calibration-Free Motion Capture in Open Environments
Nov 07, 2024
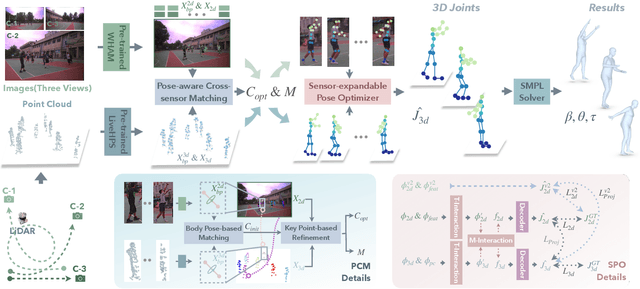
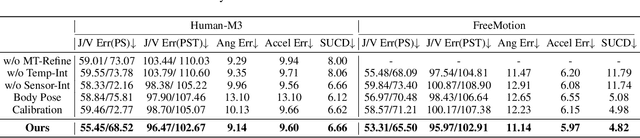

We propose a novel hybrid calibration-free method FreeCap to accurately capture global multi-person motions in open environments. Our system combines a single LiDAR with expandable moving cameras, allowing for flexible and precise motion estimation in a unified world coordinate. In particular, We introduce a local-to-global pose-aware cross-sensor human-matching module that predicts the alignment among each sensor, even in the absence of calibration. Additionally, our coarse-to-fine sensor-expandable pose optimizer further optimizes the 3D human key points and the alignments, it is also capable of incorporating additional cameras to enhance accuracy. Extensive experiments on Human-M3 and FreeMotion datasets demonstrate that our method significantly outperforms state-of-the-art single-modal methods, offering an expandable and efficient solution for multi-person motion capture across various applications.
Estimating Body and Hand Motion in an Ego-sensed World
Oct 04, 2024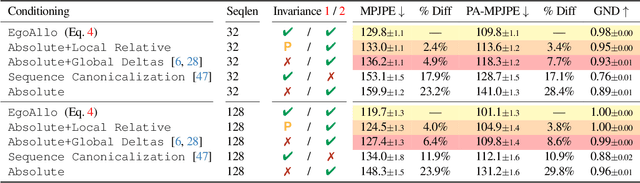
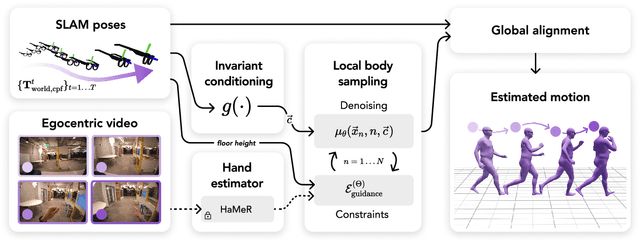
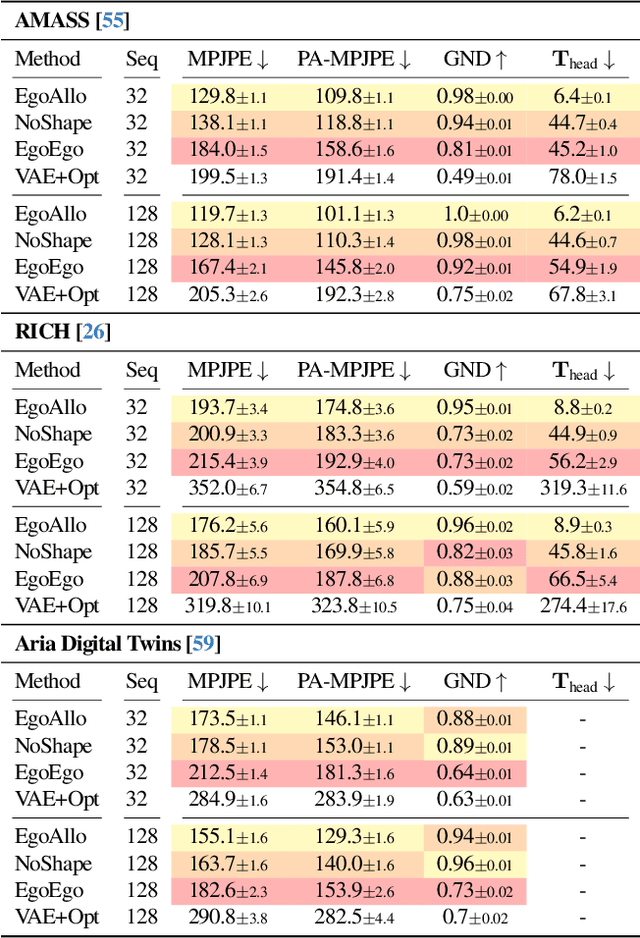
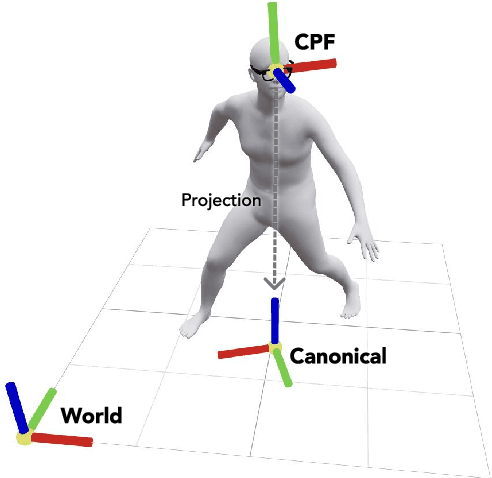
We present EgoAllo, a system for human motion estimation from a head-mounted device. Using only egocentric SLAM poses and images, EgoAllo guides sampling from a conditional diffusion model to estimate 3D body pose, height, and hand parameters that capture the wearer's actions in the allocentric coordinate frame of the scene. To achieve this, our key insight is in representation: we propose spatial and temporal invariance criteria for improving model performance, from which we derive a head motion conditioning parameterization that improves estimation by up to 18%. We also show how the bodies estimated by our system can improve the hands: the resulting kinematic and temporal constraints result in over 40% lower hand estimation errors compared to noisy monocular estimates. Project page: https://egoallo.github.io/
A vision-based framework for human behavior understanding in industrial assembly lines
Sep 25, 2024



This paper introduces a vision-based framework for capturing and understanding human behavior in industrial assembly lines, focusing on car door manufacturing. The framework leverages advanced computer vision techniques to estimate workers' locations and 3D poses and analyze work postures, actions, and task progress. A key contribution is the introduction of the CarDA dataset, which contains domain-relevant assembly actions captured in a realistic setting to support the analysis of the framework for human pose and action analysis. The dataset comprises time-synchronized multi-camera RGB-D videos, motion capture data recorded in a real car manufacturing environment, and annotations for EAWS-based ergonomic risk scores and assembly activities. Experimental results demonstrate the effectiveness of the proposed approach in classifying worker postures and robust performance in monitoring assembly task progress.
Lost & Found: Updating Dynamic 3D Scene Graphs from Egocentric Observations
Nov 28, 2024



Recent approaches have successfully focused on the segmentation of static reconstructions, thereby equipping downstream applications with semantic 3D understanding. However, the world in which we live is dynamic, characterized by numerous interactions between the environment and humans or robotic agents. Static semantic maps are unable to capture this information, and the naive solution of rescanning the environment after every change is both costly and ineffective in tracking e.g. objects being stored away in drawers. With Lost & Found we present an approach that addresses this limitation. Based solely on egocentric recordings with corresponding hand position and camera pose estimates, we are able to track the 6DoF poses of the moving object within the detected interaction interval. These changes are applied online to a transformable scene graph that captures object-level relations. Compared to state-of-the-art object pose trackers, our approach is more reliable in handling the challenging egocentric viewpoint and the lack of depth information. It outperforms the second-best approach by 34% and 56% for translational and orientational error, respectively, and produces visibly smoother 6DoF object trajectories. In addition, we illustrate how the acquired interaction information in the dynamic scene graph can be employed in the context of robotic applications that would otherwise be unfeasible: We show how our method allows to command a mobile manipulator through teach & repeat, and how information about prior interaction allows a mobile manipulator to retrieve an object hidden in a drawer. Code, videos and corresponding data are accessible at https://behretj.github.io/LostAndFound.
SCRREAM : SCan, Register, REnder And Map:A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a Benchmark
Oct 30, 2024



Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing & object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
CondiMen: Conditional Multi-Person Mesh Recovery
Dec 17, 2024Multi-person human mesh recovery (HMR) consists in detecting all individuals in a given input image, and predicting the body shape, pose, and 3D location for each detected person. The dominant approaches to this task rely on neural networks trained to output a single prediction for each detected individual. In contrast, we propose CondiMen, a method that outputs a joint parametric distribution over likely poses, body shapes, intrinsics and distances to the camera, using a Bayesian network. This approach offers several advantages. First, a probability distribution can handle some inherent ambiguities of this task -- such as the uncertainty between a person's size and their distance to the camera, or simply the loss of information when projecting 3D data onto the 2D image plane. Second, the output distribution can be combined with additional information to produce better predictions, by using e.g. known camera or body shape parameters, or by exploiting multi-view observations. Third, one can efficiently extract the most likely predictions from the output distribution, making our proposed approach suitable for real-time applications. Empirically we find that our model i) achieves performance on par with or better than the state-of-the-art, ii) captures uncertainties and correlations inherent in pose estimation and iii) can exploit additional information at test time, such as multi-view consistency or body shape priors. CondiMen spices up the modeling of ambiguity, using just the right ingredients on hand.
Lifting Motion to the 3D World via 2D Diffusion
Nov 27, 2024Estimating 3D motion from 2D observations is a long-standing research challenge. Prior work typically requires training on datasets containing ground truth 3D motions, limiting their applicability to activities well-represented in existing motion capture data. This dependency particularly hinders generalization to out-of-distribution scenarios or subjects where collecting 3D ground truth is challenging, such as complex athletic movements or animal motion. We introduce MVLift, a novel approach to predict global 3D motion -- including both joint rotations and root trajectories in the world coordinate system -- using only 2D pose sequences for training. Our multi-stage framework leverages 2D motion diffusion models to progressively generate consistent 2D pose sequences across multiple views, a key step in recovering accurate global 3D motion. MVLift generalizes across various domains, including human poses, human-object interactions, and animal poses. Despite not requiring 3D supervision, it outperforms prior work on five datasets, including those methods that require 3D supervision.
Crowd3D++: Robust Monocular Crowd Reconstruction with Upright Space
Nov 09, 2024This paper aims to reconstruct hundreds of people's 3D poses, shapes, and locations from a single image with unknown camera parameters. Due to the small and highly varying 2D human scales, depth ambiguity, and perspective distortion, no existing methods can achieve globally consistent reconstruction and accurate reprojection. To address these challenges, we first propose Crowd3D, which leverages a new concept, Human-scene Virtual Interaction Point (HVIP), to convert the complex 3D human localization into 2D-pixel localization with robust camera and ground estimation to achieve globally consistent reconstruction. To achieve stable generalization on different camera FoVs without test-time optimization, we propose an extended version, Crowd3D++, which eliminates the influence of camera parameters and the cropping operation by the proposed canonical upright space and ground-aware normalization transform. In the defined upright space, Crowd3D++ also designs an HVIPNet to regress 2D HVIP and infer the depths. Besides, we contribute two benchmark datasets, LargeCrowd and SyntheticCrowd, for evaluating crowd reconstruction in large scenes. The source code and data will be made publicly available after acceptance.