 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead Detection
Head detection is the process of identifying and locating human heads in images or videos.
Papers and Code
TSPulse: Dual Space Tiny Pre-Trained Models for Rapid Time-Series Analysis
May 19, 2025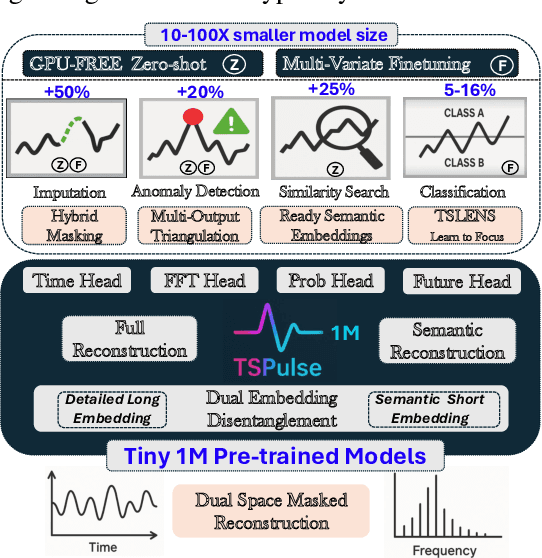

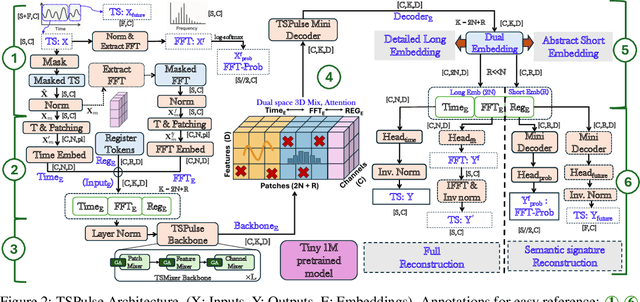

The rise of time-series pre-trained models has advanced temporal representation learning, but current state-of-the-art models are often large-scale, requiring substantial compute. We introduce TSPulse, ultra-compact time-series pre-trained models with only 1M parameters, specialized to perform strongly across classification, anomaly detection, imputation, and retrieval tasks. TSPulse introduces innovations at both the architecture and task levels. At the architecture level, it employs a dual-space masked reconstruction, learning from both time and frequency domains to capture complementary signals. This is further enhanced by a dual-embedding disentanglement, generating both detailed embeddings for fine-grained analysis and high-level semantic embeddings for broader task understanding. Notably, TSPulse's semantic embeddings are robust to shifts in time, magnitude, and noise, which is important for robust retrieval. At the task level, TSPulse incorporates TSLens, a fine-tuning component enabling task-specific feature attention. It also introduces a multi-head triangulation technique that correlates deviations from multiple prediction heads, enhancing anomaly detection by fusing complementary model outputs. Additionally, a hybrid mask pretraining is proposed to improves zero-shot imputation by reducing pre-training bias. These architecture and task innovations collectively contribute to TSPulse's significant performance gains: 5-16% on the UEA classification benchmarks, +20% on the TSB-AD anomaly detection leaderboard, +50% in zero-shot imputation, and +25% in time-series retrieval. Remarkably, these results are achieved with just 1M parameters, making TSPulse 10-100X smaller than existing pre-trained models. Its efficiency enables GPU-free inference and rapid pre-training, setting a new standard for efficient time-series pre-trained models. Models will be open-sourced soon.
Benchmarking Foundation Models for Zero-Shot Biometric Tasks
May 30, 2025The advent of foundation models, particularly Vision-Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), has redefined the frontiers of artificial intelligence, enabling remarkable generalization across diverse tasks with minimal or no supervision. Yet, their potential in biometric recognition and analysis remains relatively underexplored. In this work, we introduce a comprehensive benchmark that evaluates the zero-shot and few-shot performance of state-of-the-art publicly available VLMs and MLLMs across six biometric tasks spanning the face and iris modalities: face verification, soft biometric attribute prediction (gender and race), iris recognition, presentation attack detection (PAD), and face manipulation detection (morphs and deepfakes). A total of 41 VLMs were used in this evaluation. Experiments show that embeddings from these foundation models can be used for diverse biometric tasks with varying degrees of success. For example, in the case of face verification, a True Match Rate (TMR) of 96.77 percent was obtained at a False Match Rate (FMR) of 1 percent on the Labeled Face in the Wild (LFW) dataset, without any fine-tuning. In the case of iris recognition, the TMR at 1 percent FMR on the IITD-R-Full dataset was 97.55 percent without any fine-tuning. Further, we show that applying a simple classifier head to these embeddings can help perform DeepFake detection for faces, Presentation Attack Detection (PAD) for irides, and extract soft biometric attributes like gender and ethnicity from faces with reasonably high accuracy. This work reiterates the potential of pretrained models in achieving the long-term vision of Artificial General Intelligence.
RQR3D: Reparametrizing the regression targets for BEV-based 3D object detection
May 23, 2025Accurate, fast, and reliable 3D perception is essential for autonomous driving. Recently, bird's-eye view (BEV)-based perception approaches have emerged as superior alternatives to perspective-based solutions, offering enhanced spatial understanding and more natural outputs for planning. Existing BEV-based 3D object detection methods, typically adhering to angle-based representation, directly estimate the size and orientation of rotated bounding boxes. We observe that BEV-based 3D object detection is analogous to aerial oriented object detection, where angle-based methods are recognized for being affected by discontinuities in their loss functions. Drawing inspiration from this domain, we propose Restricted Quadrilateral Representation to define 3D regression targets. RQR3D regresses the smallest horizontal bounding box encapsulating the oriented box, along with the offsets between the corners of these two boxes, thereby transforming the oriented object detection problem into a keypoint regression task. RQR3D is compatible with any 3D object detection approach. We employ RQR3D within an anchor-free single-stage object detection method and introduce an objectness head to address class imbalance problem. Furthermore, we introduce a simplified radar fusion backbone that eliminates the need for voxel grouping and processes the BEV-mapped point cloud with standard 2D convolutions, rather than sparse convolutions. Extensive evaluations on the nuScenes dataset demonstrate that RQR3D achieves state-of-the-art performance in camera-radar 3D object detection, outperforming the previous best method by +4% in NDS and +2.4% in mAP, and significantly reducing the translation and orientation errors, which are crucial for safe autonomous driving. These consistent gains highlight the robustness, precision, and real-world readiness of our approach.
RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
Jun 16, 2025



Accurate road topology reasoning is critical for autonomous driving, enabling effective navigation and adherence to traffic regulations. Central to this task are lane perception and topology reasoning. However, existing methods typically focus on either lane detection or Lane-to-Lane (L2L) topology reasoning, often \textit{neglecting} Lane-to-Traffic-element (L2T) relationships or \textit{failing} to optimize these tasks jointly. Furthermore, most approaches either overlook relational modeling or apply it in a limited scope, despite the inherent spatial relationships among road elements. We argue that relational modeling is beneficial for both perception and reasoning, as humans naturally leverage contextual relationships for road element recognition and their connectivity inference. To this end, we introduce relational modeling into both perception and reasoning, \textit{jointly} enhancing structural understanding. Specifically, we propose: 1) a relation-aware lane detector, where our geometry-biased self-attention and \curve\ cross-attention refine lane representations by capturing relational dependencies; 2) relation-enhanced topology heads, including a geometry-enhanced L2L head and a cross-view L2T head, boosting reasoning with relational cues; and 3) a contrastive learning strategy with InfoNCE loss to regularize relationship embeddings. Extensive experiments on OpenLane-V2 demonstrate that our approach significantly improves both detection and topology reasoning metrics, achieving +3.1 in DET$_l$, +5.3 in TOP$_{ll}$, +4.9 in TOP$_{lt}$, and an overall +4.4 in OLS, setting a new state-of-the-art. Code will be released.
Team RAS in 9th ABAW Competition: Multimodal Compound Expression Recognition Approach
Jul 02, 2025Compound Expression Recognition (CER), a subfield of affective computing, aims to detect complex emotional states formed by combinations of basic emotions. In this work, we present a novel zero-shot multimodal approach for CER that combines six heterogeneous modalities into a single pipeline: static and dynamic facial expressions, scene and label matching, scene context, audio, and text. Unlike previous approaches relying on task-specific training data, our approach uses zero-shot components, including Contrastive Language-Image Pretraining (CLIP)-based label matching and Qwen-VL for semantic scene understanding. We further introduce a Multi-Head Probability Fusion (MHPF) module that dynamically weights modality-specific predictions, followed by a Compound Expressions (CE) transformation module that uses Pair-Wise Probability Aggregation (PPA) and Pair-Wise Feature Similarity Aggregation (PFSA) methods to produce interpretable compound emotion outputs. Evaluated under multi-corpus training, the proposed approach shows F1 scores of 46.95% on AffWild2, 49.02% on Acted Facial Expressions in The Wild (AFEW), and 34.85% on C-EXPR-DB via zero-shot testing, which is comparable to the results of supervised approaches trained on target data. This demonstrates the effectiveness of the proposed approach for capturing CE without domain adaptation. The source code is publicly available.
Automated Fetal Biometry Assessment with Deep Ensembles using Sparse-Sampling of 2D Intrapartum Ultrasound Images
May 20, 2025



The International Society of Ultrasound advocates Intrapartum Ultrasound (US) Imaging in Obstetrics and Gynecology (ISUOG) to monitor labour progression through changes in fetal head position. Two reliable ultrasound-derived parameters that are used to predict outcomes of instrumental vaginal delivery are the angle of progression (AoP) and head-symphysis distance (HSD). In this work, as part of the Intrapartum Ultrasounds Grand Challenge (IUGC) 2024, we propose an automated fetal biometry measurement pipeline to reduce intra- and inter-observer variability and improve measurement reliability. Our pipeline consists of three key tasks: (i) classification of standard planes (SP) from US videos, (ii) segmentation of fetal head and pubic symphysis from the detected SPs, and (iii) computation of the AoP and HSD from the segmented regions. We perform sparse sampling to mitigate class imbalances and reduce spurious correlations in task (i), and utilize ensemble-based deep learning methods for task (i) and (ii) to enhance generalizability under different US acquisition settings. Finally, to promote robustness in task iii) with respect to the structural fidelity of measurements, we retain the largest connected components and apply ellipse fitting to the segmentations. Our solution achieved ACC: 0.9452, F1: 0.9225, AUC: 0.983, MCC: 0.8361, DSC: 0.918, HD: 19.73, ASD: 5.71, $\Delta_{AoP}$: 8.90 and $\Delta_{HSD}$: 14.35 across an unseen hold-out set of 4 patients and 224 US frames. The results from the proposed automated pipeline can improve the understanding of labour arrest causes and guide the development of clinical risk stratification tools for efficient and effective prenatal care.
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
Pierce the Mists, Greet the Sky: Decipher Knowledge Overshadowing via Knowledge Circuit Analysis
May 21, 2025Large Language Models (LLMs), despite their remarkable capabilities, are hampered by hallucinations. A particularly challenging variant, knowledge overshadowing, occurs when one piece of activated knowledge inadvertently masks another relevant piece, leading to erroneous outputs even with high-quality training data. Current understanding of overshadowing is largely confined to inference-time observations, lacking deep insights into its origins and internal mechanisms during model training. Therefore, we introduce PhantomCircuit, a novel framework designed to comprehensively analyze and detect knowledge overshadowing. By innovatively employing knowledge circuit analysis, PhantomCircuit dissects the internal workings of attention heads, tracing how competing knowledge pathways contribute to the overshadowing phenomenon and its evolution throughout the training process. Extensive experiments demonstrate PhantomCircuit's effectiveness in identifying such instances, offering novel insights into this elusive hallucination and providing the research community with a new methodological lens for its potential mitigation.
RemoteSAM: Towards Segment Anything for Earth Observation
May 23, 2025
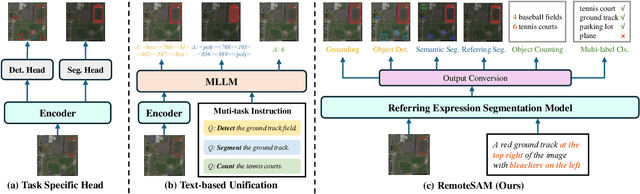
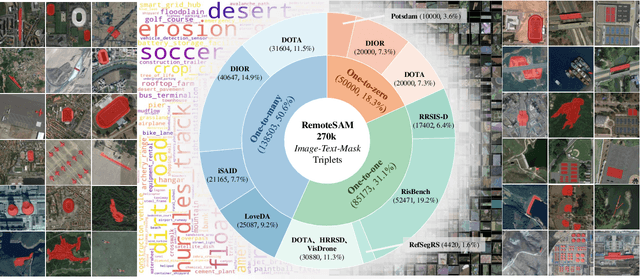
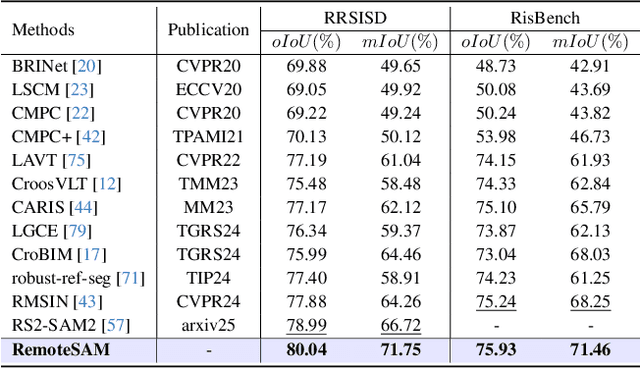
We aim to develop a robust yet flexible visual foundation model for Earth observation. It should possess strong capabilities in recognizing and localizing diverse visual targets while providing compatibility with various input-output interfaces required across different task scenarios. Current systems cannot meet these requirements, as they typically utilize task-specific architecture trained on narrow data domains with limited semantic coverage. Our study addresses these limitations from two aspects: data and modeling. We first introduce an automatic data engine that enjoys significantly better scalability compared to previous human annotation or rule-based approaches. It has enabled us to create the largest dataset of its kind to date, comprising 270K image-text-mask triplets covering an unprecedented range of diverse semantic categories and attribute specifications. Based on this data foundation, we further propose a task unification paradigm that centers around referring expression segmentation. It effectively handles a wide range of vision-centric perception tasks, including classification, detection, segmentation, grounding, etc, using a single model without any task-specific heads. Combining these innovations on data and modeling, we present RemoteSAM, a foundation model that establishes new SoTA on several earth observation perception benchmarks, outperforming other foundation models such as Falcon, GeoChat, and LHRS-Bot with significantly higher efficiency. Models and data are publicly available at https://github.com/1e12Leon/RemoteSAM.
Leveraging Intermediate Features of Vision Transformer for Face Anti-Spoofing
May 30, 2025Face recognition systems are designed to be robust against changes in head pose, illumination, and blurring during image capture. If a malicious person presents a face photo of the registered user, they may bypass the authentication process illegally. Such spoofing attacks need to be detected before face recognition. In this paper, we propose a spoofing attack detection method based on Vision Transformer (ViT) to detect minute differences between live and spoofed face images. The proposed method utilizes the intermediate features of ViT, which have a good balance between local and global features that are important for spoofing attack detection, for calculating loss in training and score in inference. The proposed method also introduces two data augmentation methods: face anti-spoofing data augmentation and patch-wise data augmentation, to improve the accuracy of spoofing attack detection. We demonstrate the effectiveness of the proposed method through experiments using the OULU-NPU and SiW datasets.