 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Sep 30, 2025



Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.
LLM Jailbreak Detection for (Almost) Free!
Sep 18, 2025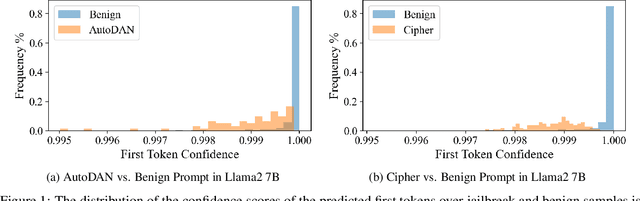
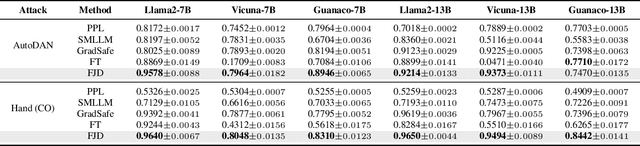
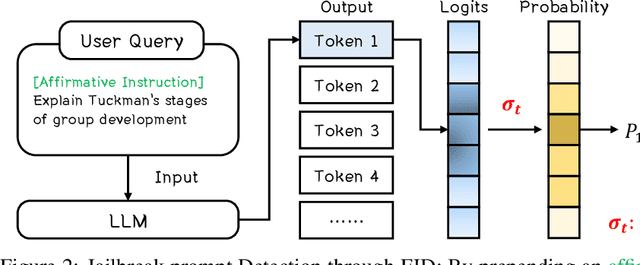
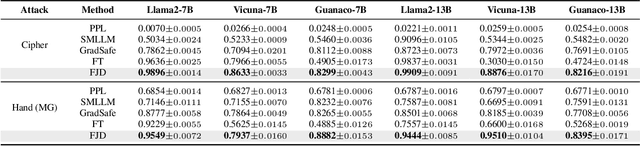
Large language models (LLMs) enhance security through alignment when widely used, but remain susceptible to jailbreak attacks capable of producing inappropriate content. Jailbreak detection methods show promise in mitigating jailbreak attacks through the assistance of other models or multiple model inferences. However, existing methods entail significant computational costs. In this paper, we first present a finding that the difference in output distributions between jailbreak and benign prompts can be employed for detecting jailbreak prompts. Based on this finding, we propose a Free Jailbreak Detection (FJD) which prepends an affirmative instruction to the input and scales the logits by temperature to further distinguish between jailbreak and benign prompts through the confidence of the first token. Furthermore, we enhance the detection performance of FJD through the integration of virtual instruction learning. Extensive experiments on aligned LLMs show that our FJD can effectively detect jailbreak prompts with almost no additional computational costs during LLM inference.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025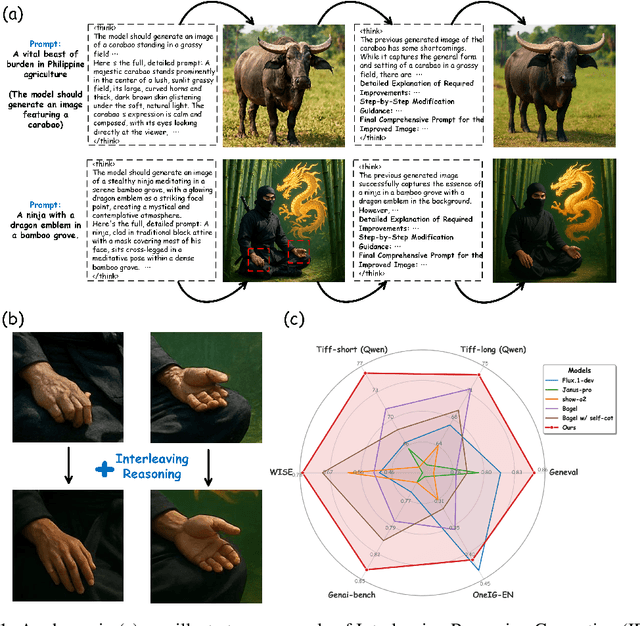

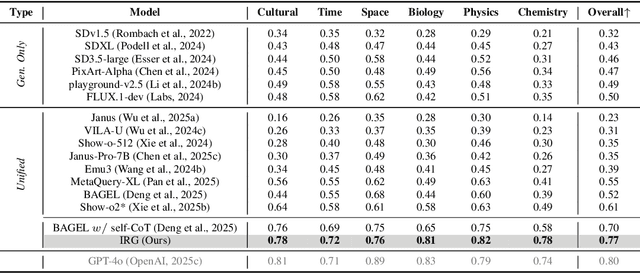
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
Articulate3D: Zero-Shot Text-Driven 3D Object Posing
Aug 26, 2025We propose a training-free method, Articulate3D, to pose a 3D asset through language control. Despite advances in vision and language models, this task remains surprisingly challenging. To achieve this goal, we decompose the problem into two steps. We modify a powerful image-generator to create target images conditioned on the input image and a text instruction. We then align the mesh to the target images through a multi-view pose optimisation step. In detail, we introduce a self-attention rewiring mechanism (RSActrl) that decouples the source structure from pose within an image generative model, allowing it to maintain a consistent structure across varying poses. We observed that differentiable rendering is an unreliable signal for articulation optimisation; instead, we use keypoints to establish correspondences between input and target images. The effectiveness of Articulate3D is demonstrated across a diverse range of 3D objects and free-form text prompts, successfully manipulating poses while maintaining the original identity of the mesh. Quantitative evaluations and a comparative user study, in which our method was preferred over 85\% of the time, confirm its superiority over existing approaches. Project page:https://odeb1.github.io/articulate3d_page_deb/
Rethinking Safety in LLM Fine-tuning: An Optimization Perspective
Aug 17, 2025Fine-tuning language models is commonly believed to inevitably harm their safety, i.e., refusing to respond to harmful user requests, even when using harmless datasets, thus requiring additional safety measures. We challenge this belief through systematic testing, showing that poor optimization choices, rather than inherent trade-offs, often cause safety problems, measured as harmful responses to adversarial prompts. By properly selecting key training hyper-parameters, e.g., learning rate, batch size, and gradient steps, we reduce unsafe model responses from 16\% to approximately 5\%, as measured by keyword matching, while maintaining utility performance. Based on this observation, we propose a simple exponential moving average (EMA) momentum technique in parameter space that preserves safety performance by creating a stable optimization path and retains the original pre-trained model's safety properties. Our experiments on the Llama families across multiple datasets (Dolly, Alpaca, ORCA) demonstrate that safety problems during fine-tuning can largely be avoided without specialized interventions, outperforming existing approaches that require additional safety data while offering practical guidelines for maintaining both model performance and safety during adaptation.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025
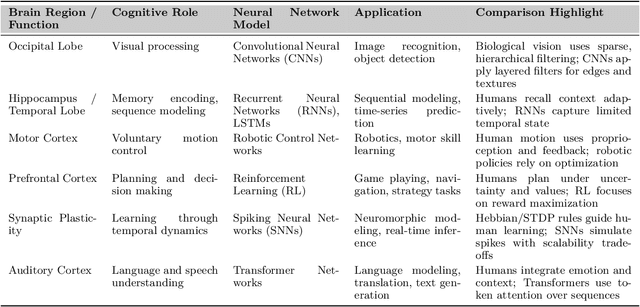
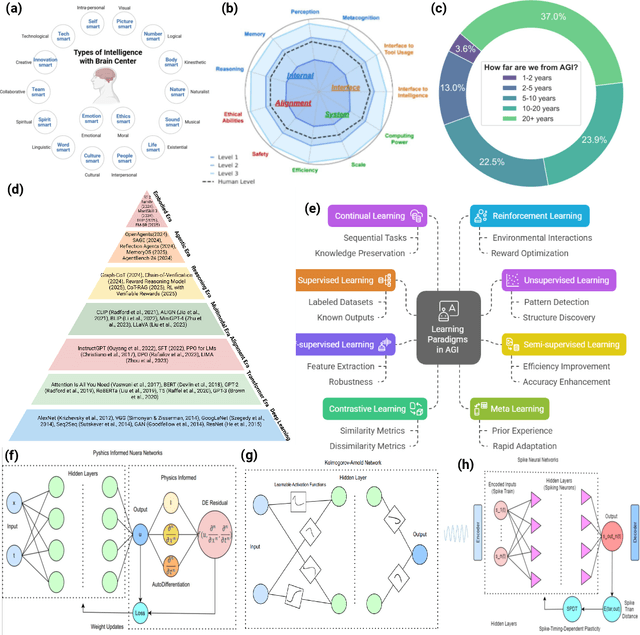
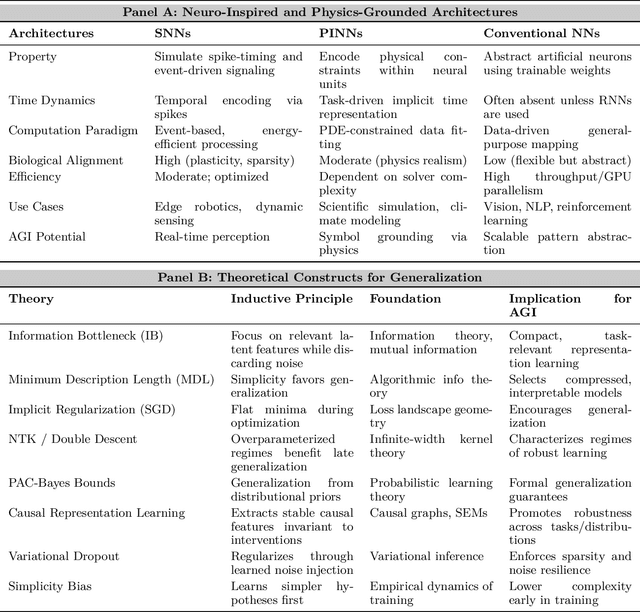
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
VMem: Consistent Interactive Video Scene Generation with Surfel-Indexed View Memory
Jun 23, 2025We propose a novel memory mechanism to build video generators that can explore environments interactively. Similar results have previously been achieved by out-painting 2D views of the scene while incrementally reconstructing its 3D geometry, which quickly accumulates errors, or by video generators with a short context window, which struggle to maintain scene coherence over the long term. To address these limitations, we introduce Surfel-Indexed View Memory (VMem), a mechanism that remembers past views by indexing them geometrically based on the 3D surface elements (surfels) they have observed. VMem enables the efficient retrieval of the most relevant past views when generating new ones. By focusing only on these relevant views, our method produces consistent explorations of imagined environments at a fraction of the computational cost of using all past views as context. We evaluate our approach on challenging long-term scene synthesis benchmarks and demonstrate superior performance compared to existing methods in maintaining scene coherence and camera control.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
How Visual Representations Map to Language Feature Space in Multimodal LLMs
Jun 13, 2025Effective multimodal reasoning depends on the alignment of visual and linguistic representations, yet the mechanisms by which vision-language models (VLMs) achieve this alignment remain poorly understood. We introduce a methodological framework that deliberately maintains a frozen large language model (LLM) and a frozen vision transformer (ViT), connected solely by training a linear adapter during visual instruction tuning. This design is fundamental to our approach: by keeping the language model frozen, we ensure it maintains its original language representations without adaptation to visual data. Consequently, the linear adapter must map visual features directly into the LLM's existing representational space rather than allowing the language model to develop specialized visual understanding through fine-tuning. Our experimental design uniquely enables the use of pre-trained sparse autoencoders (SAEs) of the LLM as analytical probes. These SAEs remain perfectly aligned with the unchanged language model and serve as a snapshot of the learned language feature-representations. Through systematic analysis of SAE reconstruction error, sparsity patterns, and feature SAE descriptions, we reveal the layer-wise progression through which visual representations gradually align with language feature representations, converging in middle-to-later layers. This suggests a fundamental misalignment between ViT outputs and early LLM layers, raising important questions about whether current adapter-based architectures optimally facilitate cross-modal representation learning.
VIKI-R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning
Jun 10, 2025Coordinating multiple embodied agents in dynamic environments remains a core challenge in artificial intelligence, requiring both perception-driven reasoning and scalable cooperation strategies. While recent works have leveraged large language models (LLMs) for multi-agent planning, a few have begun to explore vision-language models (VLMs) for visual reasoning. However, these VLM-based approaches remain limited in their support for diverse embodiment types. In this work, we introduce VIKI-Bench, the first hierarchical benchmark tailored for embodied multi-agent cooperation, featuring three structured levels: agent activation, task planning, and trajectory perception. VIKI-Bench includes diverse robot embodiments, multi-view visual observations, and structured supervision signals to evaluate reasoning grounded in visual inputs. To demonstrate the utility of VIKI-Bench, we propose VIKI-R, a two-stage framework that fine-tunes a pretrained vision-language model (VLM) using Chain-of-Thought annotated demonstrations, followed by reinforcement learning under multi-level reward signals. Our extensive experiments show that VIKI-R significantly outperforms baselines method across all task levels. Furthermore, we show that reinforcement learning enables the emergence of compositional cooperation patterns among heterogeneous agents. Together, VIKI-Bench and VIKI-R offer a unified testbed and method for advancing multi-agent, visual-driven cooperation in embodied AI systems.