 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGsr Baseline
Papers and Code
GSR: Learning Structured Reasoning for Embodied Manipulation
Feb 02, 2026Despite rapid progress, embodied agents still struggle with long-horizon manipulation that requires maintaining spatial consistency, causal dependencies, and goal constraints. A key limitation of existing approaches is that task reasoning is implicitly embedded in high-dimensional latent representations, making it challenging to separate task structure from perceptual variability. We introduce Grounded Scene-graph Reasoning (GSR), a structured reasoning paradigm that explicitly models world-state evolution as transitions over semantically grounded scene graphs. By reasoning step-wise over object states and spatial relations, rather than directly mapping perception to actions, GSR enables explicit reasoning about action preconditions, consequences, and goal satisfaction in a physically grounded space. To support learning such reasoning, we construct Manip-Cognition-1.6M, a large-scale dataset that jointly supervises world understanding, action planning, and goal interpretation. Extensive evaluations across RLBench, LIBERO, GSR-benchmark, and real-world robotic tasks show that GSR significantly improves zero-shot generalization and long-horizon task completion over prompting-based baselines. These results highlight explicit world-state representations as a key inductive bias for scalable embodied reasoning.
PRISM: Purified Representation and Integrated Semantic Modeling for Generative Sequential Recommendation
Jan 23, 2026Generative Sequential Recommendation (GSR) has emerged as a promising paradigm, reframing recommendation as an autoregressive sequence generation task over discrete Semantic IDs (SIDs), typically derived via codebook-based quantization. Despite its great potential in unifying retrieval and ranking, existing GSR frameworks still face two critical limitations: (1) impure and unstable semantic tokenization, where quantization methods struggle with interaction noise and codebook collapse, resulting in SIDs with ambiguous discrimination; and (2) lossy and weakly structured generation, where reliance solely on coarse-grained discrete tokens inevitably introduces information loss and neglects items' hierarchical logic. To address these issues, we propose a novel generative recommendation framework, PRISM, with Purified Representation and Integrated Semantic Modeling. Specifically, to ensure high-quality tokenization, we design a Purified Semantic Quantizer that constructs a robust codebook via adaptive collaborative denoising and hierarchical semantic anchoring mechanisms. To compensate for information loss during quantization, we further propose an Integrated Semantic Recommender, which incorporates a dynamic semantic integration mechanism to integrate fine-grained semantics and enforces logical validity through a semantic structure alignment objective. PRISM consistently outperforms state-of-the-art baselines across four real-world datasets, demonstrating substantial performance gains, particularly in high-sparsity scenarios.
VocSim: A Training-free Benchmark for Zero-shot Content Identity in Single-source Audio
Dec 10, 2025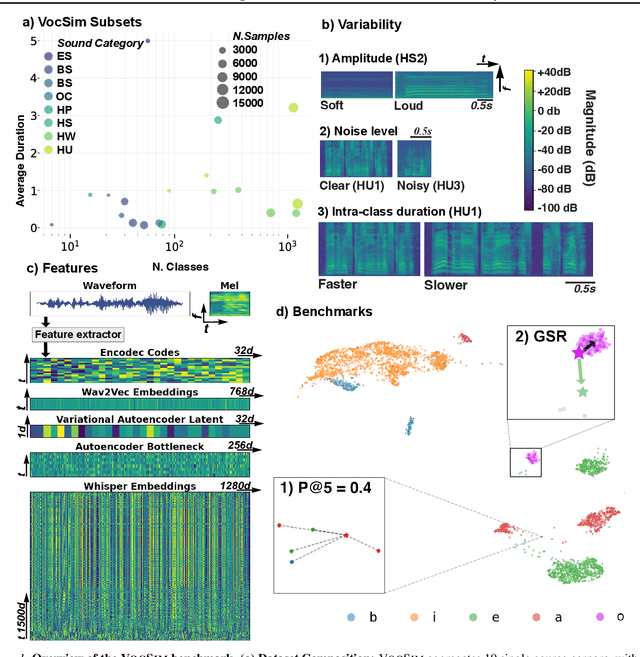



General-purpose audio representations aim to map acoustically variable instances of the same event to nearby points, resolving content identity in a zero-shot setting. Unlike supervised classification benchmarks that measure adaptability via parameter updates, we introduce VocSim, a training-free benchmark probing the intrinsic geometric alignment of frozen embeddings. VocSim aggregates 125k single-source clips from 19 corpora spanning human speech, animal vocalizations, and environmental sounds. By restricting to single-source audio, we isolate content representation from the confound of source separation. We evaluate embeddings using Precision@k for local purity and the Global Separation Rate (GSR) for point-wise class separation. To calibrate GSR, we report lift over an empirical permutation baseline. Across diverse foundation models, a simple pipeline, frozen Whisper encoder features, time-frequency pooling, and label-free PCA, yields strong zero-shot performance. However, VocSim also uncovers a consistent generalization gap. On blind, low-resource speech, local retrieval drops sharply. While performance remains statistically distinguishable from chance, the absolute geometric structure collapses, indicating a failure to generalize to unseen phonotactics. As external validation, our top embeddings predict avian perceptual similarity, improve bioacoustic classification, and achieve state-of-the-art results on the HEAR benchmark. We posit that the intrinsic geometric quality measured here proxies utility in unlisted downstream applications. We release data, code, and a public leaderboard to standardize the evaluation of intrinsic audio geometry.
Graph Structure Refinement with Energy-based Contrastive Learning
Dec 20, 2024



Graph Neural Networks (GNNs) have recently gained widespread attention as a successful tool for analyzing graph-structured data. However, imperfect graph structure with noisy links lacks enough robustness and may damage graph representations, therefore limiting the GNNs' performance in practical tasks. Moreover, existing generative architectures fail to fit discriminative graph-related tasks. To tackle these issues, we introduce an unsupervised method based on a joint of generative training and discriminative training to learn graph structure and representation, aiming to improve the discriminative performance of generative models. We propose an Energy-based Contrastive Learning (ECL) guided Graph Structure Refinement (GSR) framework, denoted as ECL-GSR. To our knowledge, this is the first work to combine energy-based models with contrastive learning for GSR. Specifically, we leverage ECL to approximate the joint distribution of sample pairs, which increases the similarity between representations of positive pairs while reducing the similarity between negative ones. Refined structure is produced by augmenting and removing edges according to the similarity metrics among node representations. Extensive experiments demonstrate that ECL-GSR outperforms \textit{the state-of-the-art on eight benchmark datasets} in node classification. ECL-GSR achieves \textit{faster training with fewer samples and memories} against the leading baseline, highlighting its simplicity and efficiency in downstream tasks.
OVGaussian: Generalizable 3D Gaussian Segmentation with Open Vocabularies
Dec 31, 2024Open-vocabulary scene understanding using 3D Gaussian (3DGS) representations has garnered considerable attention. However, existing methods mostly lift knowledge from large 2D vision models into 3DGS on a scene-by-scene basis, restricting the capabilities of open-vocabulary querying within their training scenes so that lacking the generalizability to novel scenes. In this work, we propose \textbf{OVGaussian}, a generalizable \textbf{O}pen-\textbf{V}ocabulary 3D semantic segmentation framework based on the 3D \textbf{Gaussian} representation. We first construct a large-scale 3D scene dataset based on 3DGS, dubbed \textbf{SegGaussian}, which provides detailed semantic and instance annotations for both Gaussian points and multi-view images. To promote semantic generalization across scenes, we introduce Generalizable Semantic Rasterization (GSR), which leverages a 3D neural network to learn and predict the semantic property for each 3D Gaussian point, where the semantic property can be rendered as multi-view consistent 2D semantic maps. In the next, we propose a Cross-modal Consistency Learning (CCL) framework that utilizes open-vocabulary annotations of 2D images and 3D Gaussians within SegGaussian to train the 3D neural network capable of open-vocabulary semantic segmentation across Gaussian-based 3D scenes. Experimental results demonstrate that OVGaussian significantly outperforms baseline methods, exhibiting robust cross-scene, cross-domain, and novel-view generalization capabilities. Code and the SegGaussian dataset will be released. (https://github.com/runnanchen/OVGaussian).
Toward Foundation Model for Multivariate Wearable Sensing of Physiological Signals
Dec 12, 2024



Time-series foundation models have the ability to run inference, mainly forecasting, on any type of time series data, thanks to the informative representations comprising waveform features. Wearable sensing data, on the other hand, contain more variability in both patterns and frequency bands of interest and generally emphasize more on the ability to infer healthcare-related outcomes. The main challenge of crafting a foundation model for wearable sensing physiological signals is to learn generalizable representations that support efficient adaptation across heterogeneous sensing configurations and applications. In this work, we propose NormWear, a step toward such a foundation model, aiming to extract generalized and informative wearable sensing representations. NormWear has been pretrained on a large set of physiological signals, including PPG, ECG, EEG, GSR, and IMU, from various public resources. For a holistic assessment, we perform downstream evaluation on 11 public wearable sensing datasets, spanning 18 applications in the areas of mental health, body state inference, biomarker estimations, and disease risk evaluations. We demonstrate that NormWear achieves a better performance improvement over competitive baselines in general time series foundation modeling. In addition, leveraging a novel representation-alignment-match-based method, we align physiological signals embeddings with text embeddings. This alignment enables our proposed foundation model to perform zero-shot inference, allowing it to generalize to previously unseen wearable signal-based health applications. Finally, we perform nonlinear dynamic analysis on the waveform features extracted by the model at each intermediate layer. This analysis quantifies the model's internal processes, offering clear insights into its behavior and fostering greater trust in its inferences among end users.
Strongly Topology-preserving GNNs for Brain Graph Super-resolution
Nov 01, 2024Brain graph super-resolution (SR) is an under-explored yet highly relevant task in network neuroscience. It circumvents the need for costly and time-consuming medical imaging data collection, preparation, and processing. Current SR methods leverage graph neural networks (GNNs) thanks to their ability to natively handle graph-structured datasets. However, most GNNs perform node feature learning, which presents two significant limitations: (1) they require computationally expensive methods to learn complex node features capable of inferring connectivity strength or edge features, which do not scale to larger graphs; and (2) computations in the node space fail to adequately capture higher-order brain topologies such as cliques and hubs. However, numerous studies have shown that brain graph topology is crucial in identifying the onset and presence of various neurodegenerative disorders like Alzheimer and Parkinson. Motivated by these challenges and applications, we propose our STP-GSR framework. It is the first graph SR architecture to perform representation learning in higher-order topological space. Specifically, using the primal-dual graph formulation from graph theory, we develop an efficient mapping from the edge space of our low-resolution (LR) brain graphs to the node space of a high-resolution (HR) dual graph. This approach ensures that node-level computations on this dual graph correspond naturally to edge-level learning on our HR brain graphs, thereby enforcing strong topological consistency within our framework. Additionally, our framework is GNN layer agnostic and can easily learn from smaller, scalable GNNs, reducing computational requirements. We comprehensively benchmark our framework across seven key topological measures and observe that it significantly outperforms the previous state-of-the-art methods and baselines.
Offline Imitation Learning Through Graph Search and Retrieval
Jul 22, 2024



Imitation learning is a powerful machine learning algorithm for a robot to acquire manipulation skills. Nevertheless, many real-world manipulation tasks involve precise and dexterous robot-object interactions, which make it difficult for humans to collect high-quality expert demonstrations. As a result, a robot has to learn skills from suboptimal demonstrations and unstructured interactions, which remains a key challenge. Existing works typically use offline deep reinforcement learning (RL) to solve this challenge, but in practice these algorithms are unstable and fragile due to the deadly triad issue. To overcome this problem, we propose GSR, a simple yet effective algorithm that learns from suboptimal demonstrations through Graph Search and Retrieval. We first use pretrained representation to organize the interaction experience into a graph and perform a graph search to calculate the values of different behaviors. Then, we apply a retrieval-based procedure to identify the best behavior (actions) on each state and use behavior cloning to learn that behavior. We evaluate our method in both simulation and real-world robotic manipulation tasks with complex visual inputs, covering various precise and dexterous manipulation skills with objects of different physical properties. GSR can achieve a 10% to 30% higher success rate and over 30% higher proficiency compared to baselines. Our project page is at https://zhaohengyin.github.io/gsr.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024



Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
VoiceFixer: Toward General Speech Restoration with Neural Vocoder
Oct 05, 2021



Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on single-task speech restoration (SSR), such as speech denoising or speech declipping. However, SSR systems only focus on one task and do not address the general speech restoration problem. In addition, previous SSR systems show limited performance in some speech restoration tasks such as speech super-resolution. To overcome those limitations, we propose a general speech restoration (GSR) task that attempts to remove multiple distortions simultaneously. Furthermore, we propose VoiceFixer, a generative framework to address the GSR task. VoiceFixer consists of an analysis stage and a synthesis stage to mimic the speech analysis and comprehension of the human auditory system. We employ a ResUNet to model the analysis stage and a neural vocoder to model the synthesis stage. We evaluate VoiceFixer with additive noise, room reverberation, low-resolution, and clipping distortions. Our baseline GSR model achieves a 0.499 higher mean opinion score (MOS) than the speech enhancement SSR model. VoiceFixer further surpasses the GSR baseline model on the MOS score by 0.256. Moreover, we observe that VoiceFixer generalizes well to severely degraded real speech recordings, indicating its potential in restoring old movies and historical speeches. The source code is available at https://github.com/haoheliu/voicefixer_main.