 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxelnet
VoxelNet is a 3D object detection model that uses voxelization and PointNet to detect objects in 3D point clouds.
Papers and Code
A Light Perspective for 3D Object Detection
Mar 10, 2025Comprehending the environment and accurately detecting objects in 3D space are essential for advancing autonomous vehicle technologies. Integrating Camera and LIDAR data has emerged as an effective approach for achieving high accuracy in 3D Object Detection models. However, existing methodologies often rely on heavy, traditional backbones that are computationally demanding. This paper introduces a novel approach that incorporates cutting-edge Deep Learning techniques into the feature extraction process, aiming to create more efficient models without compromising performance. Our model, NextBEV, surpasses established feature extractors like ResNet50 and MobileNetV2. On the KITTI 3D Monocular detection benchmark, NextBEV achieves an accuracy improvement of 2.39%, having less than 10% of the MobileNetV3 parameters. Moreover, we propose changes in LIDAR backbones that decreased the original inference time to 10 ms. Additionally, by fusing these lightweight proposals, we have enhanced the accuracy of the VoxelNet-based model by 2.93% and improved the F1-score of the PointPillar-based model by approximately 20%. Therefore, this work contributes to establishing lightweight and powerful models for individual or fusion techniques, making them more suitable for onboard implementations.
HEAD: A Bandwidth-Efficient Cooperative Perception Approach for Heterogeneous Connected and Autonomous Vehicles
Aug 27, 2024



In cooperative perception studies, there is often a trade-off between communication bandwidth and perception performance. While current feature fusion solutions are known for their excellent object detection performance, transmitting the entire sets of intermediate feature maps requires substantial bandwidth. Furthermore, these fusion approaches are typically limited to vehicles that use identical detection models. Our goal is to develop a solution that supports cooperative perception across vehicles equipped with different modalities of sensors. This method aims to deliver improved perception performance compared to late fusion techniques, while achieving precision similar to the state-of-art intermediate fusion, but requires an order of magnitude less bandwidth. We propose HEAD, a method that fuses features from the classification and regression heads in 3D object detection networks. Our method is compatible with heterogeneous detection networks such as LiDAR PointPillars, SECOND, VoxelNet, and camera Bird's-eye View (BEV) Encoder. Given the naturally smaller feature size in the detection heads, we design a self-attention mechanism to fuse the classification head and a complementary feature fusion layer to fuse the regression head. Our experiments, comprehensively evaluated on the V2V4Real and OPV2V datasets, demonstrate that HEAD is a fusion method that effectively balances communication bandwidth and perception performance.
Arbitrary-Scale Point Cloud Upsampling by Voxel-Based Network with Latent Geometric-Consistent Learning
Mar 08, 2024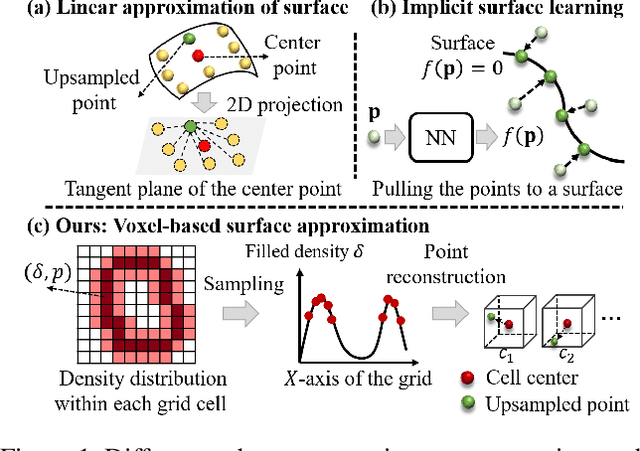
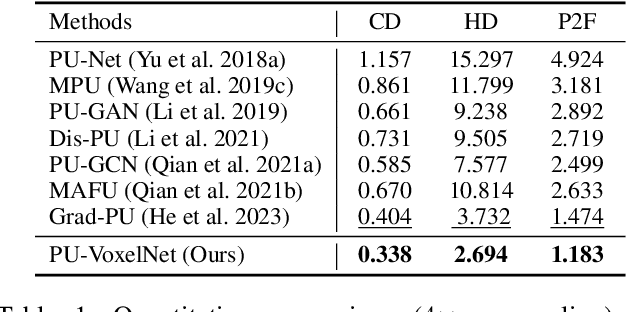
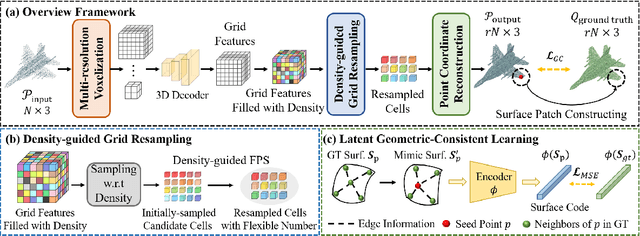
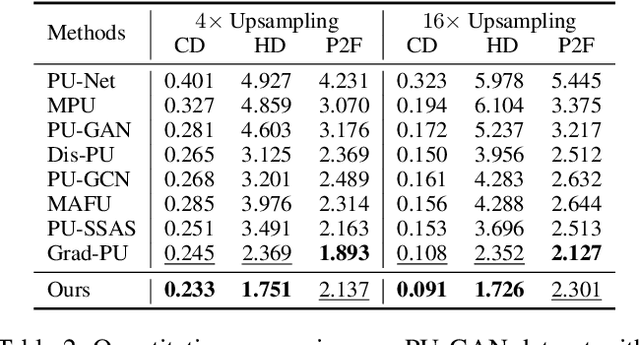
Recently, arbitrary-scale point cloud upsampling mechanism became increasingly popular due to its efficiency and convenience for practical applications. To achieve this, most previous approaches formulate it as a problem of surface approximation and employ point-based networks to learn surface representations. However, learning surfaces from sparse point clouds is more challenging, and thus they often suffer from the low-fidelity geometry approximation. To address it, we propose an arbitrary-scale Point cloud Upsampling framework using Voxel-based Network (\textbf{PU-VoxelNet}). Thanks to the completeness and regularity inherited from the voxel representation, voxel-based networks are capable of providing predefined grid space to approximate 3D surface, and an arbitrary number of points can be reconstructed according to the predicted density distribution within each grid cell. However, we investigate the inaccurate grid sampling caused by imprecise density predictions. To address this issue, a density-guided grid resampling method is developed to generate high-fidelity points while effectively avoiding sampling outliers. Further, to improve the fine-grained details, we present an auxiliary training supervision to enforce the latent geometric consistency among local surface patches. Extensive experiments indicate the proposed approach outperforms the state-of-the-art approaches not only in terms of fixed upsampling rates but also for arbitrary-scale upsampling.
VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking
Mar 20, 2023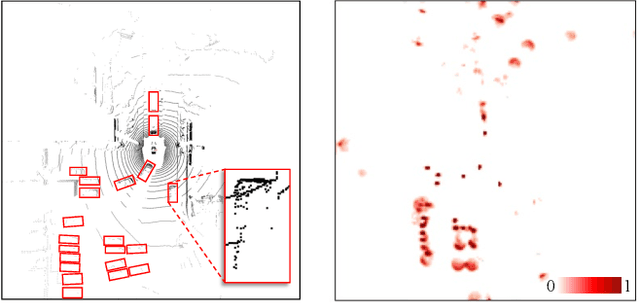


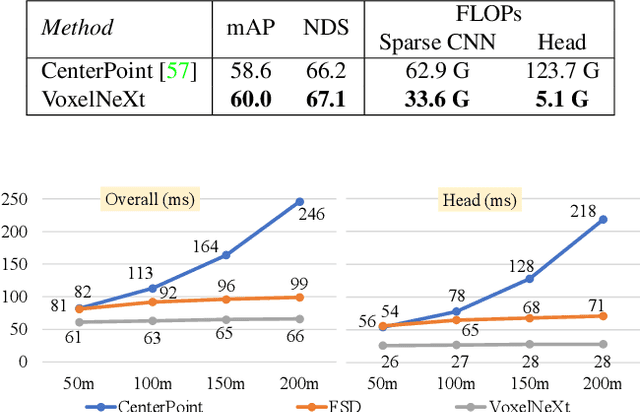
3D object detectors usually rely on hand-crafted proxies, e.g., anchors or centers, and translate well-studied 2D frameworks to 3D. Thus, sparse voxel features need to be densified and processed by dense prediction heads, which inevitably costs extra computation. In this paper, we instead propose VoxelNext for fully sparse 3D object detection. Our core insight is to predict objects directly based on sparse voxel features, without relying on hand-crafted proxies. Our strong sparse convolutional network VoxelNeXt detects and tracks 3D objects through voxel features entirely. It is an elegant and efficient framework, with no need for sparse-to-dense conversion or NMS post-processing. Our method achieves a better speed-accuracy trade-off than other mainframe detectors on the nuScenes dataset. For the first time, we show that a fully sparse voxel-based representation works decently for LIDAR 3D object detection and tracking. Extensive experiments on nuScenes, Waymo, and Argoverse2 benchmarks validate the effectiveness of our approach. Without bells and whistles, our model outperforms all existing LIDAR methods on the nuScenes tracking test benchmark.
Generative VoxelNet: Learning Energy-Based Models for 3D Shape Synthesis and Analysis
Dec 25, 2020
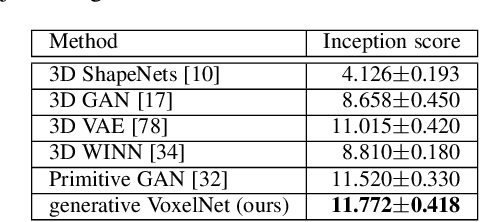

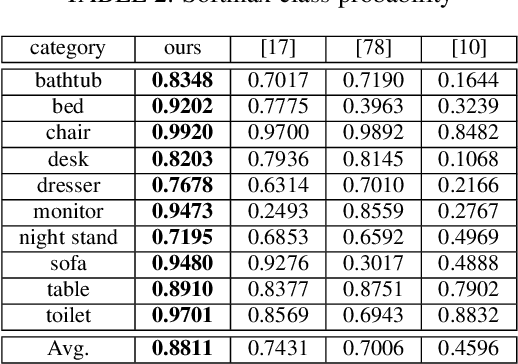
3D data that contains rich geometry information of objects and scenes is valuable for understanding 3D physical world. With the recent emergence of large-scale 3D datasets, it becomes increasingly crucial to have a powerful 3D generative model for 3D shape synthesis and analysis. This paper proposes a deep 3D energy-based model to represent volumetric shapes. The maximum likelihood training of the model follows an "analysis by synthesis" scheme. The benefits of the proposed model are six-fold: first, unlike GANs and VAEs, the model training does not rely on any auxiliary models; second, the model can synthesize realistic 3D shapes by Markov chain Monte Carlo (MCMC); third, the conditional model can be applied to 3D object recovery and super resolution; fourth, the model can serve as a building block in a multi-grid modeling and sampling framework for high resolution 3D shape synthesis; fifth, the model can be used to train a 3D generator via MCMC teaching; sixth, the unsupervisedly trained model provides a powerful feature extractor for 3D data, which is useful for 3D object classification. Experiments demonstrate that the proposed model can generate high-quality 3D shape patterns and can be useful for a wide variety of 3D shape analysis.
Manual-Label Free 3D Detection via An Open-Source Simulator
Nov 16, 2020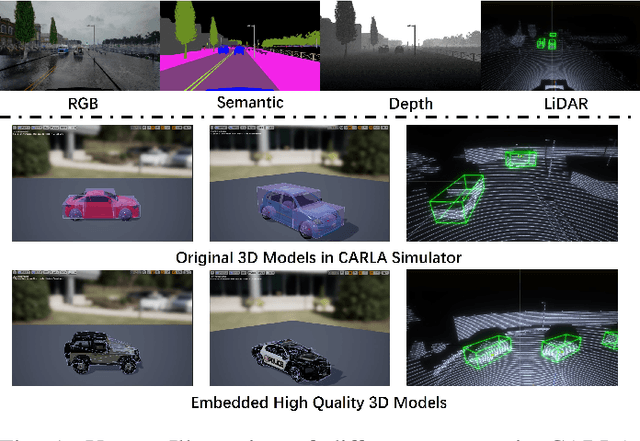
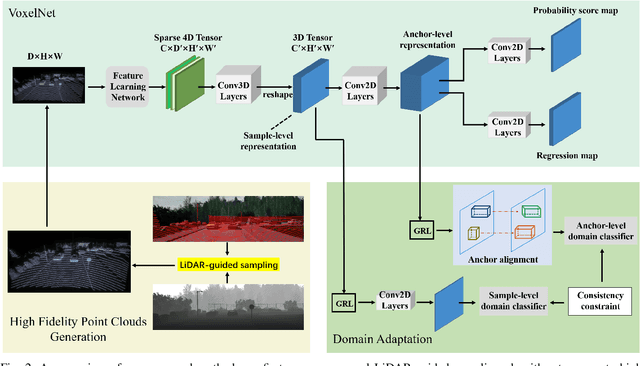


LiDAR based 3D object detectors typically need a large amount of detailed-labeled point cloud data for training, but these detailed labels are commonly expensive to acquire. In this paper, we propose a manual-label free 3D detection algorithm that leverages the CARLA simulator to generate a large amount of self-labeled training samples and introduces a novel Domain Adaptive VoxelNet (DA-VoxelNet) that can cross the distribution gap from the synthetic data to the real scenario. The self-labeled training samples are generated by a set of high quality 3D models embedded in a CARLA simulator and a proposed LiDAR-guided sampling algorithm. Then a DA-VoxelNet that integrates both a sample-level DA module and an anchor-level DA module is proposed to enable the detector trained by the synthetic data to adapt to real scenario. Experimental results show that the proposed unsupervised DA 3D detector on KITTI evaluation set can achieve 76.66% and 56.64% mAP on BEV mode and 3D mode respectively. The results reveal a promising perspective of training a LIDAR-based 3D detector without any hand-tagged label.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019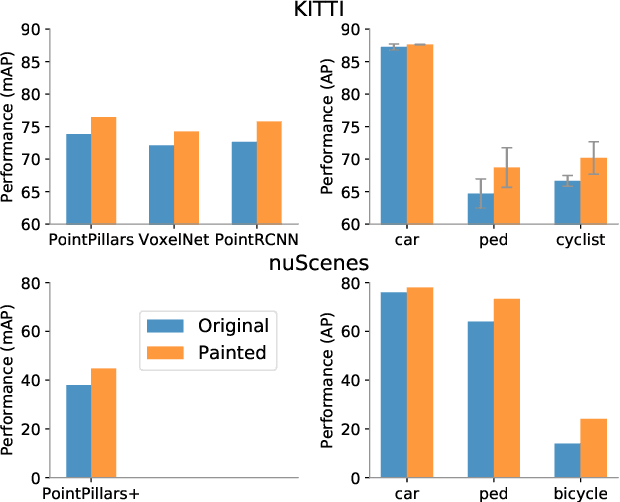
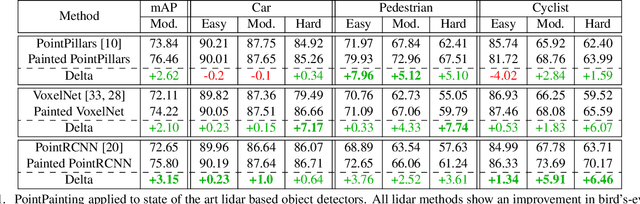
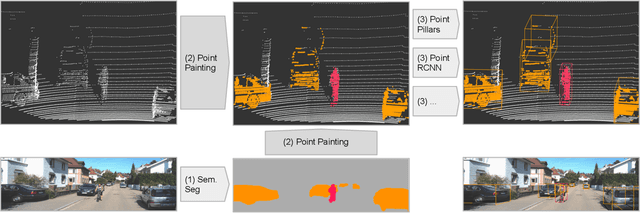
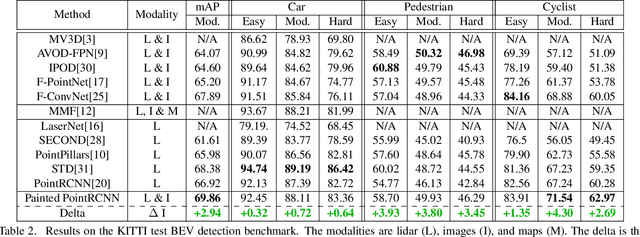
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.
Patch Refinement -- Localized 3D Object Detection
Oct 09, 2019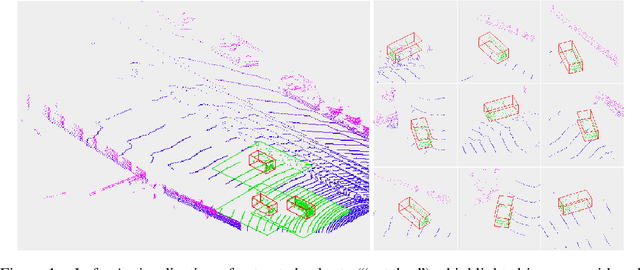
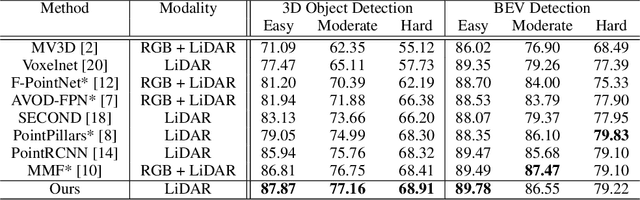
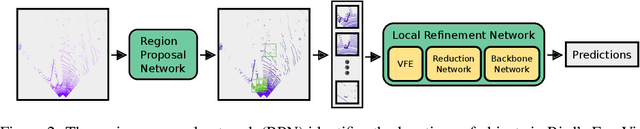
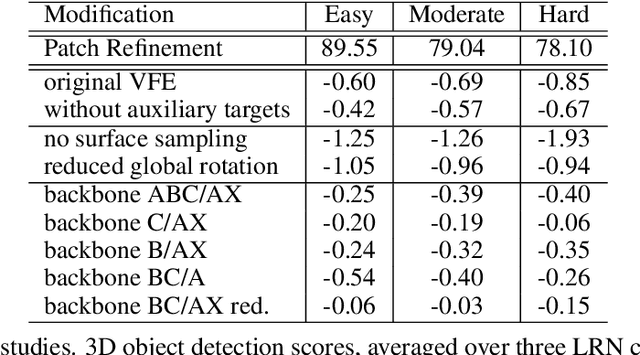
We introduce Patch Refinement a two-stage model for accurate 3D object detection and localization from point cloud data. Patch Refinement is composed of two independently trained Voxelnet-based networks, a Region Proposal Network (RPN) and a Local Refinement Network (LRN). We decompose the detection task into a preliminary Bird's Eye View (BEV) detection step and a local 3D detection step. Based on the proposed BEV locations by the RPN, we extract small point cloud subsets ("patches"), which are then processed by the LRN, which is less limited by memory constraints due to the small area of each patch. Therefore, we can apply encoding with a higher voxel resolution locally. The independence of the LRN enables the use of additional augmentation techniques and allows for an efficient, regression focused training as it uses only a small fraction of each scene. Evaluated on the KITTI 3D object detection benchmark, our submission from January 28, 2019, outperformed all previous entries on all three difficulties of the class car, using only 50 % of the available training data and only LiDAR information.
MVX-Net: Multimodal VoxelNet for 3D Object Detection
Apr 02, 2019

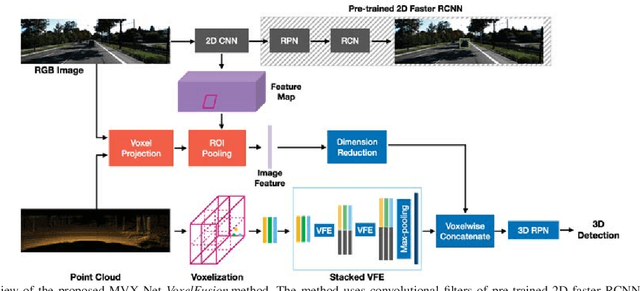

Many recent works on 3D object detection have focused on designing neural network architectures that can consume point cloud data. While these approaches demonstrate encouraging performance, they are typically based on a single modality and are unable to leverage information from other modalities, such as a camera. Although a few approaches fuse data from different modalities, these methods either use a complicated pipeline to process the modalities sequentially, or perform late-fusion and are unable to learn interaction between different modalities at early stages. In this work, we present PointFusion and VoxelFusion: two simple yet effective early-fusion approaches to combine the RGB and point cloud modalities, by leveraging the recently introduced VoxelNet architecture. Evaluation on the KITTI dataset demonstrates significant improvements in performance over approaches which only use point cloud data. Furthermore, the proposed method provides results competitive with the state-of-the-art multimodal algorithms, achieving top-2 ranking in five of the six bird's eye view and 3D detection categories on the KITTI benchmark, by using a simple single stage network.
* 7 pages
Focal Loss in 3D Object Detection
Sep 18, 2018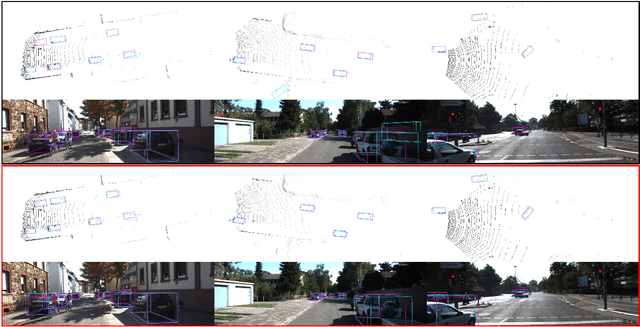


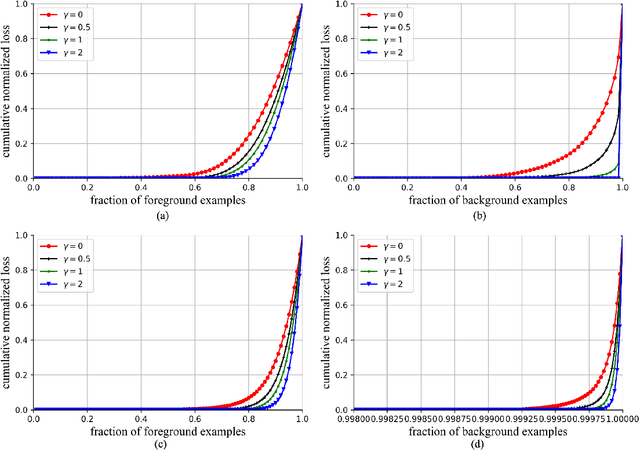
3D object detection is still an open problem in autonomous driving scenes. Robots recognize and localize key objects from sparse inputs, and suffer from a larger continuous searching space as well as serious fore-background imbalance compared to the image-based detection. In this paper, we try to solve the fore-background imbalance in the 3D object detection task. Inspired by the recent improvement of focal loss on image-based detection which is seen as a hard-mining improvement of binary cross entropy, we extend it to point-cloud-based object detection and conduct experiments to show its performance based on two different type of 3D detectors: 3D-FCN and VoxelNet. The results show up to 11.2 AP gains from focal loss in a wide range of hyperparameters in 3D object detection. Our code is available at https://github.com/pyun-ram/FL3D.