 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepetitive Action Counting
Papers and Code
When the Gold Standard isn't Necessarily Standard: Challenges of Evaluating the Translation of User-Generated Content
Dec 19, 2025



User-generated content (UGC) is characterised by frequent use of non-standard language, from spelling errors to expressive choices such as slang, character repetitions, and emojis. This makes evaluating UGC translation particularly challenging: what counts as a "good" translation depends on the level of standardness desired in the output. To explore this, we examine the human translation guidelines of four UGC datasets, and derive a taxonomy of twelve non-standard phenomena and five translation actions (NORMALISE, COPY, TRANSFER, OMIT, CENSOR). Our analysis reveals notable differences in how UGC is treated, resulting in a spectrum of standardness in reference translations. Through a case study on large language models (LLMs), we show that translation scores are highly sensitive to prompts with explicit translation instructions for UGC, and that they improve when these align with the dataset's guidelines. We argue that when preserving UGC style is important, fair evaluation requires both models and metrics to be aware of translation guidelines. Finally, we call for clear guidelines during dataset creation and for the development of controllable, guideline-aware evaluation frameworks for UGC translation.
Action Dubber: Timing Audible Actions via Inflectional Flow
Jun 16, 2025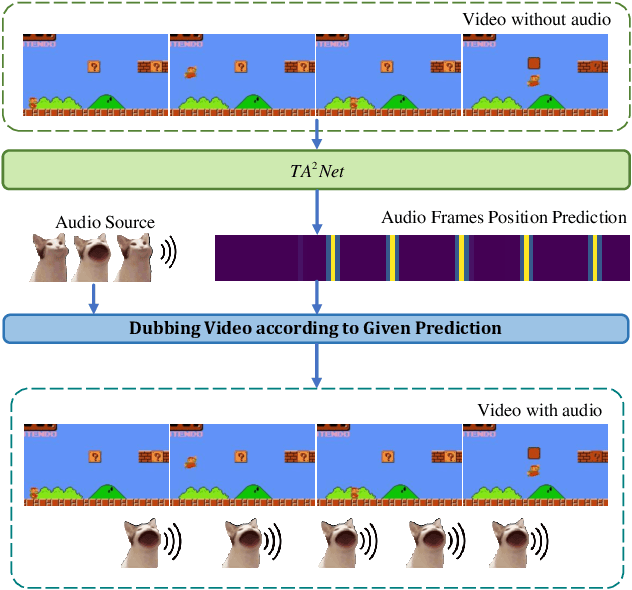


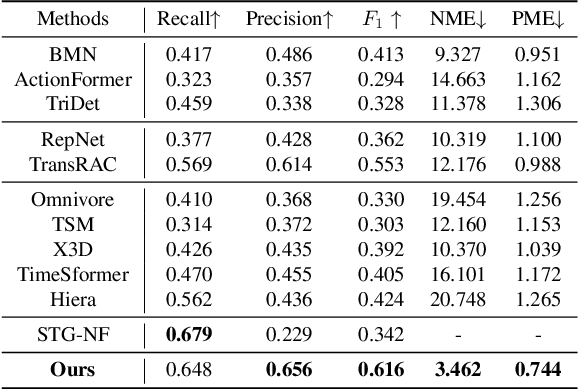
We introduce the task of Audible Action Temporal Localization, which aims to identify the spatio-temporal coordinates of audible movements. Unlike conventional tasks such as action recognition and temporal action localization, which broadly analyze video content, our task focuses on the distinct kinematic dynamics of audible actions. It is based on the premise that key actions are driven by inflectional movements; for example, collisions that produce sound often involve abrupt changes in motion. To capture this, we propose $TA^{2}Net$, a novel architecture that estimates inflectional flow using the second derivative of motion to determine collision timings without relying on audio input. $TA^{2}Net$ also integrates a self-supervised spatial localization strategy during training, combining contrastive learning with spatial analysis. This dual design improves temporal localization accuracy and simultaneously identifies sound sources within video frames. To support this task, we introduce a new benchmark dataset, $Audible623$, derived from Kinetics and UCF101 by removing non-essential vocalization subsets. Extensive experiments confirm the effectiveness of our approach on $Audible623$ and show strong generalizability to other domains, such as repetitive counting and sound source localization. Code and dataset are available at https://github.com/WenlongWan/Audible623.
Localization-Aware Multi-Scale Representation Learning for Repetitive Action Counting
Jan 13, 2025



Repetitive action counting (RAC) aims to estimate the number of class-agnostic action occurrences in a video without exemplars. Most current RAC methods rely on a raw frame-to-frame similarity representation for period prediction. However, this approach can be significantly disrupted by common noise such as action interruptions and inconsistencies, leading to sub-optimal counting performance in realistic scenarios. In this paper, we introduce a foreground localization optimization objective into similarity representation learning to obtain more robust and efficient video features. We propose a Localization-Aware Multi-Scale Representation Learning (LMRL) framework. Specifically, we apply a Multi-Scale Period-Aware Representation (MPR) with a scale-specific design to accommodate various action frequencies and learn more flexible temporal correlations. Furthermore, we introduce the Repetition Foreground Localization (RFL) method, which enhances the representation by coarsely identifying periodic actions and incorporating global semantic information. These two modules can be jointly optimized, resulting in a more discerning periodic action representation. Our approach significantly reduces the impact of noise, thereby improving counting accuracy. Additionally, the framework is designed to be scalable and adaptable to different types of video content. Experimental results on the RepCountA and UCFRep datasets demonstrate that our proposed method effectively handles repetitive action counting.
Automated Meta Prompt Engineering for Alignment with the Theory of Mind
May 13, 2025We introduce a method of meta-prompting that jointly produces fluent text for complex tasks while optimizing the similarity of neural states between a human's mental expectation and a Large Language Model's (LLM) neural processing. A technique of agentic reinforcement learning is applied, in which an LLM as a Judge (LLMaaJ) teaches another LLM, through in-context learning, how to produce content by interpreting the intended and unintended generated text traits. To measure human mental beliefs around content production, users modify long form AI-generated text articles before publication at the US Open 2024 tennis Grand Slam. Now, an LLMaaJ can solve the Theory of Mind (ToM) alignment problem by anticipating and including human edits within the creation of text from an LLM. Throughout experimentation and by interpreting the results of a live production system, the expectations of human content reviewers had 100% of alignment with AI 53.8% of the time with an average iteration count of 4.38. The geometric interpretation of content traits such as factualness, novelty, repetitiveness, and relevancy over a Hilbert vector space combines spatial volume (all trait importance) with vertices alignment (individual trait relevance) enabled the LLMaaJ to optimize on Human ToM. This resulted in an increase in content quality by extending the coverage of tennis action. Our work that was deployed at the US Open 2024 has been used across other live events within sports and entertainment.
Repetitive Action Counting with Hybrid Temporal Relation Modeling
Dec 10, 2024



Repetitive Action Counting (RAC) aims to count the number of repetitive actions occurring in videos. In the real world, repetitive actions have great diversity and bring numerous challenges (e.g., viewpoint changes, non-uniform periods, and action interruptions). Existing methods based on the temporal self-similarity matrix (TSSM) for RAC are trapped in the bottleneck of insufficient capturing action periods when applied to complicated daily videos. To tackle this issue, we propose a novel method named Hybrid Temporal Relation Modeling Network (HTRM-Net) to build diverse TSSM for RAC. The HTRM-Net mainly consists of three key components: bi-modal temporal self-similarity matrix modeling, random matrix dropping, and local temporal context modeling. Specifically, we construct temporal self-similarity matrices by bi-modal (self-attention and dual-softmax) operations, yielding diverse matrix representations from the combination of row-wise and column-wise correlations. To further enhance matrix representations, we propose incorporating a random matrix dropping module to guide channel-wise learning of the matrix explicitly. After that, we inject the local temporal context of video frames and the learned matrix into temporal correlation modeling, which can make the model robust enough to cope with error-prone situations, such as action interruption. Finally, a multi-scale matrix fusion module is designed to aggregate temporal correlations adaptively in multi-scale matrices. Extensive experiments across intra- and cross-datasets demonstrate that the proposed method not only outperforms current state-of-the-art methods but also exhibits robust capabilities in accurately counting repetitive actions in unseen action categories. Notably, our method surpasses the classical TransRAC method by 20.04\% in MAE and 22.76\% in OBO.
MultiCounter: Multiple Action Agnostic Repetition Counting in Untrimmed Videos
Sep 06, 2024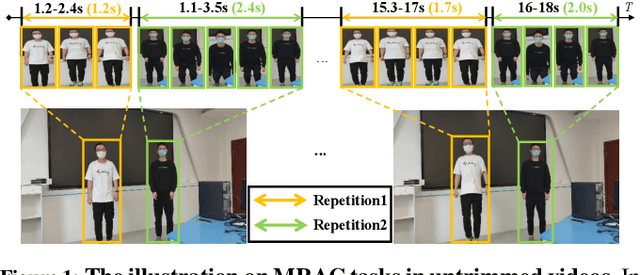

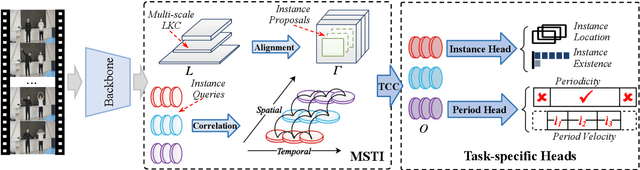
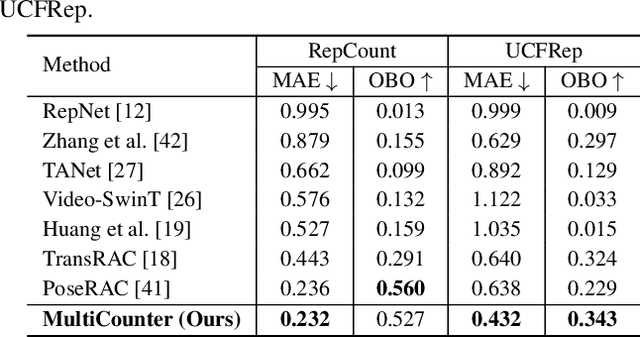
Multi-instance Repetitive Action Counting (MRAC) aims to estimate the number of repetitive actions performed by multiple instances in untrimmed videos, commonly found in human-centric domains like sports and exercise. In this paper, we propose MultiCounter, a fully end-to-end deep learning framework that enables simultaneous detection, tracking, and counting of repetitive actions of multiple human instances. Specifically, MultiCounter incorporates two novel modules: 1) mixed spatiotemporal interaction for efficient context correlation across consecutive frames, and 2) task-specific heads for accurate perception of periodic boundaries and generalization for action-agnostic human instances. We train MultiCounter on a synthetic dataset called MultiRep generated from annotated real-world videos. Experiments on the MultiRep dataset validate the fundamental challenge of MRAC tasks and showcase the superiority of our proposed model. Compared to ByteTrack+RepNet, a solution that combines an advanced tracker with a single repetition counter, MultiCounter substantially improves Period-mAP by 41.0%, reduces AvgMAE by 58.6%, and increases AvgOBO 1.48 times. This sets a new benchmark in the field of MRAC. Moreover, MultiCounter runs in real-time on a commodity GPU server and is insensitive to the number of human instances in a video.
GMFL-Net: A Global Multi-geometric Feature Learning Network for Repetitive Action Counting
Aug 31, 2024



With the continuous development of deep learning, the field of repetitive action counting is gradually gaining notice from many researchers. Extraction of pose keypoints using human pose estimation networks is proven to be an effective pose-level method. However, existing pose-level methods suffer from the shortcomings that the single coordinate is not stable enough to handle action distortions due to changes in camera viewpoints, thus failing to accurately identify salient poses, and is vulnerable to misdetection during the transition from the exception to the actual action. To overcome these problems, we propose a simple but efficient Global Multi-geometric Feature Learning Network (GMFL-Net). Specifically, we design a MIA-Module that aims to improve information representation by fusing multi-geometric features, and learning the semantic similarity among the input multi-geometric features. Then, to improve the feature representation from a global perspective, we also design a GBFL-Module that enhances the inter-dependencies between point-wise and channel-wise elements and combines them with the rich local information generated by the MIA-Module to synthesise a comprehensive and most representative global feature representation. In addition, considering the insufficient existing dataset, we collect a new dataset called Countix-Fitness-pose (https://github.com/Wantong66/Countix-Fitness) which contains different cycle lengths and exceptions, a test set with longer duration, and annotate it with fine-grained annotations at the pose-level. We also add two new action classes, namely lunge and rope push-down. Finally, extensive experiments on the challenging RepCount-pose, UCFRep-pose, and Countix-Fitness-pose benchmarks show that our proposed GMFL-Net achieves state-of-the-art performance.
Rethinking temporal self-similarity for repetitive action counting
Jul 12, 2024



Counting repetitive actions in long untrimmed videos is a challenging task that has many applications such as rehabilitation. State-of-the-art methods predict action counts by first generating a temporal self-similarity matrix (TSM) from the sampled frames and then feeding the matrix to a predictor network. The self-similarity matrix, however, is not an optimal input to a network since it discards too much information from the frame-wise embeddings. We thus rethink how a TSM can be utilized for counting repetitive actions and propose a framework that learns embeddings and predicts action start probabilities at full temporal resolution. The number of repeated actions is then inferred from the action start probabilities. In contrast to current approaches that have the TSM as an intermediate representation, we propose a novel loss based on a generated reference TSM, which enforces that the self-similarity of the learned frame-wise embeddings is consistent with the self-similarity of repeated actions. The proposed framework achieves state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and Countix.
FCA-RAC: First Cycle Annotated Repetitive Action Counting
Jun 18, 2024



Repetitive action counting quantifies the frequency of specific actions performed by individuals. However, existing action-counting datasets have limited action diversity, potentially hampering model performance on unseen actions. To address this issue, we propose a framework called First Cycle Annotated Repetitive Action Counting (FCA-RAC). This framework contains 4 parts: 1) a labeling technique that annotates each training video with the start and end of the first action cycle, along with the total action count. This technique enables the model to capture the correlation between the initial action cycle and subsequent actions; 2) an adaptive sampling strategy that maximizes action information retention by adjusting to the speed of the first annotated action cycle in videos; 3) a Multi-Temporal Granularity Convolution (MTGC) module, that leverages the muli-scale first action as a kernel to convolve across the entire video. This enables the model to capture action variations at different time scales within the video; 4) a strategy called Training Knowledge Augmentation (TKA) that exploits the annotated first action cycle information from the entire dataset. This allows the network to harness shared characteristics across actions effectively, thereby enhancing model performance and generalizability to unseen actions. Experimental results demonstrate that our approach achieves superior outcomes on RepCount-A and related datasets, highlighting the efficacy of our framework in improving model performance on seen and unseen actions. Our paper makes significant contributions to the field of action counting by addressing the limitations of existing datasets and proposing novel techniques for improving model generalizability.
Skim then Focus: Integrating Contextual and Fine-grained Views for Repetitive Action Counting
Jun 13, 2024



The key to action counting is accurately locating each video's repetitive actions. Instead of estimating the probability of each frame belonging to an action directly, we propose a dual-branch network, i.e., SkimFocusNet, working in a two-step manner. The model draws inspiration from empirical observations indicating that humans typically engage in coarse skimming of entire sequences to grasp the general action pattern initially, followed by a finer, frame-by-frame focus to determine if it aligns with the target action. Specifically, SkimFocusNet incorporates a skim branch and a focus branch. The skim branch scans the global contextual information throughout the sequence to identify potential target action for guidance. Subsequently, the focus branch utilizes the guidance to diligently identify repetitive actions using a long-short adaptive guidance (LSAG) block. Additionally, we have observed that videos in existing datasets often feature only one type of repetitive action, which inadequately represents real-world scenarios. To more accurately describe real-life situations, we establish the Multi-RepCount dataset, which includes videos containing multiple repetitive motions. On Multi-RepCount, our SkimFoucsNet can perform specified action counting, that is, to enable counting a particular action type by referencing an exemplary video. This capability substantially exhibits the robustness of our method. Extensive experiments demonstrate that SkimFocusNet achieves state-of-the-art performances with significant improvements. We also conduct a thorough ablation study to evaluate the network components. The source code will be published upon acceptance.