 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Act Classification
Dialogue act classification is the process of categorizing utterances or dialogues into different dialogue acts or speech acts.
Papers and Code
Automated Classification of Tutors' Dialogue Acts Using Generative AI: A Case Study Using the CIMA Corpus
Sep 11, 2025



This study explores the use of generative AI for automating the classification of tutors' Dialogue Acts (DAs), aiming to reduce the time and effort required by traditional manual coding. This case study uses the open-source CIMA corpus, in which tutors' responses are pre-annotated into four DA categories. Both GPT-3.5-turbo and GPT-4 models were tested using tailored prompts. Results show that GPT-4 achieved 80% accuracy, a weighted F1-score of 0.81, and a Cohen's Kappa of 0.74, surpassing baseline performance and indicating substantial agreement with human annotations. These findings suggest that generative AI has strong potential to provide an efficient and accessible approach to DA classification, with meaningful implications for educational dialogue analysis. The study also highlights the importance of task-specific label definitions and contextual information in enhancing the quality of automated annotation. Finally, it underscores the ethical considerations associated with the use of generative AI and the need for responsible and transparent research practices. The script of this research is publicly available at https://github.com/liqunhe27/Generative-AI-for-educational-dialogue-act-tagging.
Learning LLM Preference over Intra-Dialogue Pairs: A Framework for Utterance-level Understandings
Mar 07, 2025

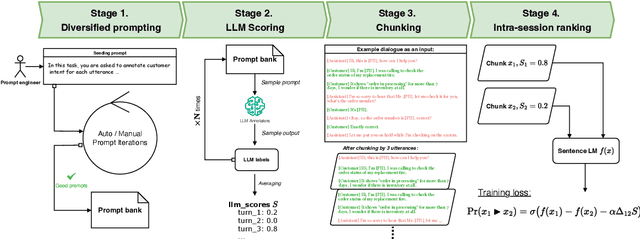

Large language models (LLMs) have demonstrated remarkable capabilities in handling complex dialogue tasks without requiring use case-specific fine-tuning. However, analyzing live dialogues in real-time necessitates low-latency processing systems, making it impractical to deploy models with billions of parameters due to latency constraints. As a result, practitioners often prefer smaller models with millions of parameters, trained on high-quality, human-annotated datasets. Yet, curating such datasets is both time-consuming and costly. Consequently, there is a growing need to combine the scalability of LLM-generated labels with the precision of human annotations, enabling fine-tuned smaller models to achieve both higher speed and accuracy comparable to larger models. In this paper, we introduce a simple yet effective framework to address this challenge. Our approach is specifically designed for per-utterance classification problems, which encompass tasks such as intent detection, dialogue state tracking, and more. To mitigate the impact of labeling errors from LLMs -- the primary source of inaccuracies in student models -- we propose a noise-reduced preference learning loss. Experimental results demonstrate that our method significantly improves accuracy across utterance-level dialogue tasks, including sentiment detection (over $2\%$), dialogue act classification (over $1.5\%$), etc.
Towards Actionable Pedagogical Feedback: A Multi-Perspective Analysis of Mathematics Teaching and Tutoring Dialogue
May 12, 2025Effective feedback is essential for refining instructional practices in mathematics education, and researchers often turn to advanced natural language processing (NLP) models to analyze classroom dialogues from multiple perspectives. However, utterance-level discourse analysis encounters two primary challenges: (1) multifunctionality, where a single utterance may serve multiple purposes that a single tag cannot capture, and (2) the exclusion of many utterances from domain-specific discourse move classifications, leading to their omission in feedback. To address these challenges, we proposed a multi-perspective discourse analysis that integrates domain-specific talk moves with dialogue act (using the flattened multi-functional SWBD-MASL schema with 43 tags) and discourse relation (applying Segmented Discourse Representation Theory with 16 relations). Our top-down analysis framework enables a comprehensive understanding of utterances that contain talk moves, as well as utterances that do not contain talk moves. This is applied to two mathematics education datasets: TalkMoves (teaching) and SAGA22 (tutoring). Through distributional unigram analysis, sequential talk move analysis, and multi-view deep dive, we discovered meaningful discourse patterns, and revealed the vital role of utterances without talk moves, demonstrating that these utterances, far from being mere fillers, serve crucial functions in guiding, acknowledging, and structuring classroom discourse. These insights underscore the importance of incorporating discourse relations and dialogue acts into AI-assisted education systems to enhance feedback and create more responsive learning environments. Our framework may prove helpful for providing human educator feedback, but also aiding in the development of AI agents that can effectively emulate the roles of both educators and students.
Task Selection and Assignment for Multi-modal Multi-task Dialogue Act Classification with Non-stationary Multi-armed Bandits
Sep 18, 2023Multi-task learning (MTL) aims to improve the performance of a primary task by jointly learning with related auxiliary tasks. Traditional MTL methods select tasks randomly during training. However, both previous studies and our results suggest that such the random selection of tasks may not be helpful, and can even be harmful to performance. Therefore, new strategies for task selection and assignment in MTL need to be explored. This paper studies the multi-modal, multi-task dialogue act classification task, and proposes a method for selecting and assigning tasks based on non-stationary multi-armed bandits (MAB) with discounted Thompson Sampling (TS) using Gaussian priors. Our experimental results show that in different training stages, different tasks have different utility. Our proposed method can effectively identify the task utility, actively avoid useless or harmful tasks, and realise the task assignment during training. Our proposed method is significantly superior in terms of UAR and F1 to the single-task and multi-task baselines with p-values < 0.05. Further analysis of experiments indicates that for the dataset with the data imbalance problem, our proposed method has significantly higher stability and can obtain consistent and decent performance for minority classes. Our proposed method is superior to the current state-of-the-art model.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 23, 2023While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.
TOD-Flow: Modeling the Structure of Task-Oriented Dialogues
Dec 07, 2023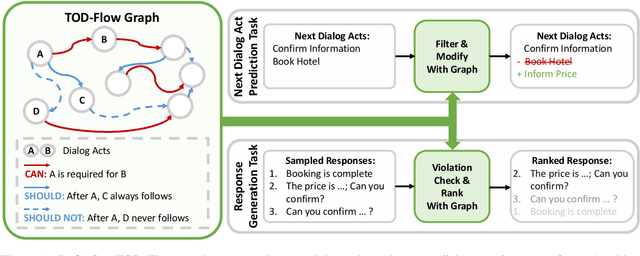
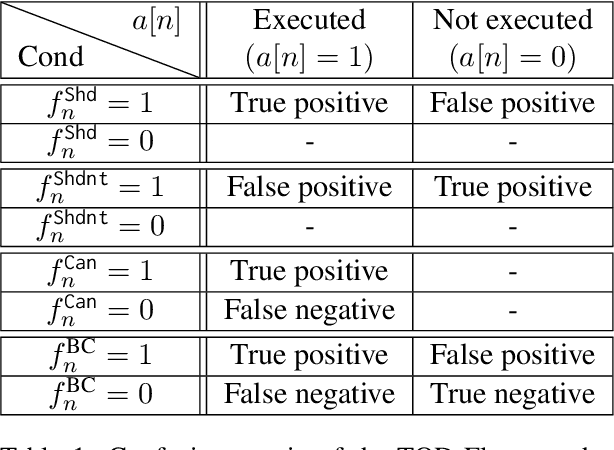
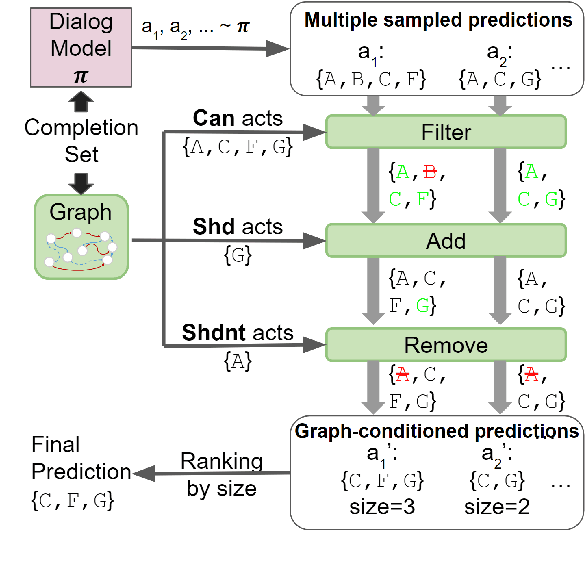

Task-Oriented Dialogue (TOD) systems have become crucial components in interactive artificial intelligence applications. While recent advances have capitalized on pre-trained language models (PLMs), they exhibit limitations regarding transparency and controllability. To address these challenges, we propose a novel approach focusing on inferring the TOD-Flow graph from dialogue data annotated with dialog acts, uncovering the underlying task structure in the form of a graph. The inferred TOD-Flow graph can be easily integrated with any dialogue model to improve its prediction performance, transparency, and controllability. Our TOD-Flow graph learns what a model can, should, and should not predict, effectively reducing the search space and providing a rationale for the model's prediction. We show that the proposed TOD-Flow graph better resembles human-annotated graphs compared to prior approaches. Furthermore, when combined with several dialogue policies and end-to-end dialogue models, we demonstrate that our approach significantly improves dialog act classification and end-to-end response generation performance in the MultiWOZ and SGD benchmarks. Code available at: https://github.com/srsohn/TOD-Flow
Does Informativeness Matter? Active Learning for Educational Dialogue Act Classification
Apr 12, 2023
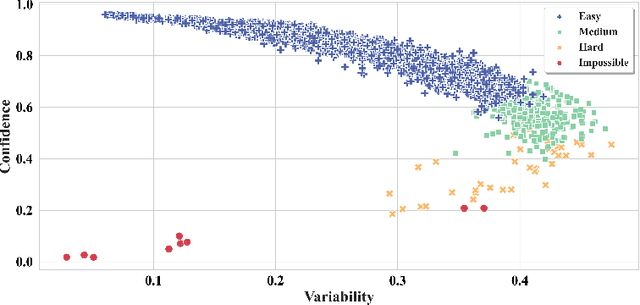
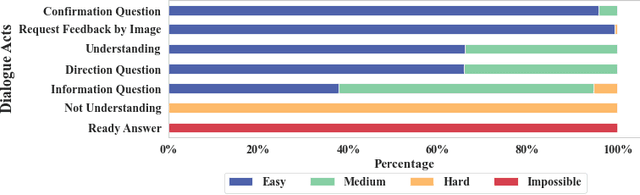

Dialogue Acts (DAs) can be used to explain what expert tutors do and what students know during the tutoring process. Most empirical studies adopt the random sampling method to obtain sentence samples for manual annotation of DAs, which are then used to train DA classifiers. However, these studies have paid little attention to sample informativeness, which can reflect the information quantity of the selected samples and inform the extent to which a classifier can learn patterns. Notably, the informativeness level may vary among the samples and the classifier might only need a small amount of low informative samples to learn the patterns. Random sampling may overlook sample informativeness, which consumes human labelling costs and contributes less to training the classifiers. As an alternative, researchers suggest employing statistical sampling methods of Active Learning (AL) to identify the informative samples for training the classifiers. However, the use of AL methods in educational DA classification tasks is under-explored. In this paper, we examine the informativeness of annotated sentence samples. Then, the study investigates how the AL methods can select informative samples to support DA classifiers in the AL sampling process. The results reveal that most annotated sentences present low informativeness in the training dataset and the patterns of these sentences can be easily captured by the DA classifier. We also demonstrate how AL methods can reduce the cost of manual annotation in the AL sampling process.
Conversational Feedback in Scripted versus Spontaneous Dialogues: A Comparative Analysis
Sep 27, 2023Scripted dialogues such as movie and TV subtitles constitute a widespread source of training data for conversational NLP models. However, the linguistic characteristics of those dialogues are notably different from those observed in corpora of spontaneous interactions. This difference is particularly marked for communicative feedback and grounding phenomena such as backchannels, acknowledgments, or clarification requests. Such signals are known to constitute a key part of the conversation flow and are used by the dialogue participants to provide feedback to one another on their perception of the ongoing interaction. This paper presents a quantitative analysis of such communicative feedback phenomena in both subtitles and spontaneous conversations. Based on dialogue data in English, French, German, Hungarian, Italian, Japanese, Norwegian and Chinese, we extract both lexical statistics and classification outputs obtained with a neural dialogue act tagger. Two main findings of this empirical study are that (1) conversational feedback is markedly less frequent in subtitles than in spontaneous dialogues and (2) subtitles contain a higher proportion of negative feedback. Furthermore, we show that dialogue responses generated by large language models also follow the same underlying trends and include comparatively few occurrences of communicative feedback, except when those models are explicitly fine-tuned on spontaneous dialogues.
Hierarchical Dialogue Understanding with Special Tokens and Turn-level Attention
Apr 29, 2023



Compared with standard text, understanding dialogue is more challenging for machines as the dynamic and unexpected semantic changes in each turn. To model such inconsistent semantics, we propose a simple but effective Hierarchical Dialogue Understanding model, HiDialog. Specifically, we first insert multiple special tokens into a dialogue and propose the turn-level attention to learn turn embeddings hierarchically. Then, a heterogeneous graph module is leveraged to polish the learned embeddings. We evaluate our model on various dialogue understanding tasks including dialogue relation extraction, dialogue emotion recognition, and dialogue act classification. Results show that our simple approach achieves state-of-the-art performance on all three tasks above. All our source code is publicly available at https://github.com/ShawX825/HiDialog.
End-to-end spoken language understanding using joint CTC loss and self-supervised, pretrained acoustic encoders
May 04, 2023



It is challenging to extract semantic meanings directly from audio signals in spoken language understanding (SLU), due to the lack of textual information. Popular end-to-end (E2E) SLU models utilize sequence-to-sequence automatic speech recognition (ASR) models to extract textual embeddings as input to infer semantics, which, however, require computationally expensive auto-regressive decoding. In this work, we leverage self-supervised acoustic encoders fine-tuned with Connectionist Temporal Classification (CTC) to extract textual embeddings and use joint CTC and SLU losses for utterance-level SLU tasks. Experiments show that our model achieves 4% absolute improvement over the the state-of-the-art (SOTA) dialogue act classification model on the DSTC2 dataset and 1.3% absolute improvement over the SOTA SLU model on the SLURP dataset.