 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-view Clustering by Squeezing Hybrid Knowledge from Cross View and Each View
Aug 23, 2020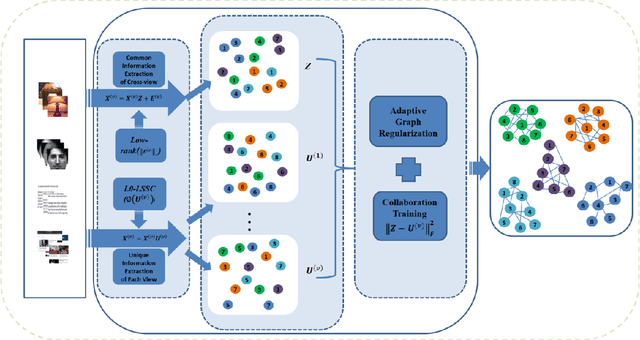
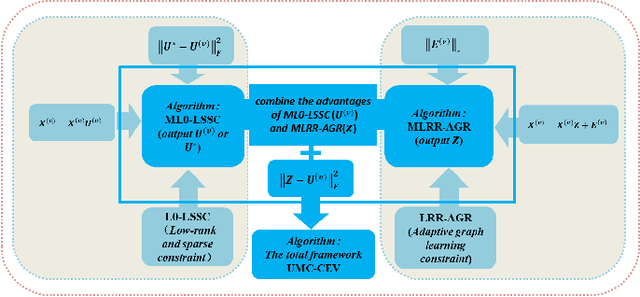
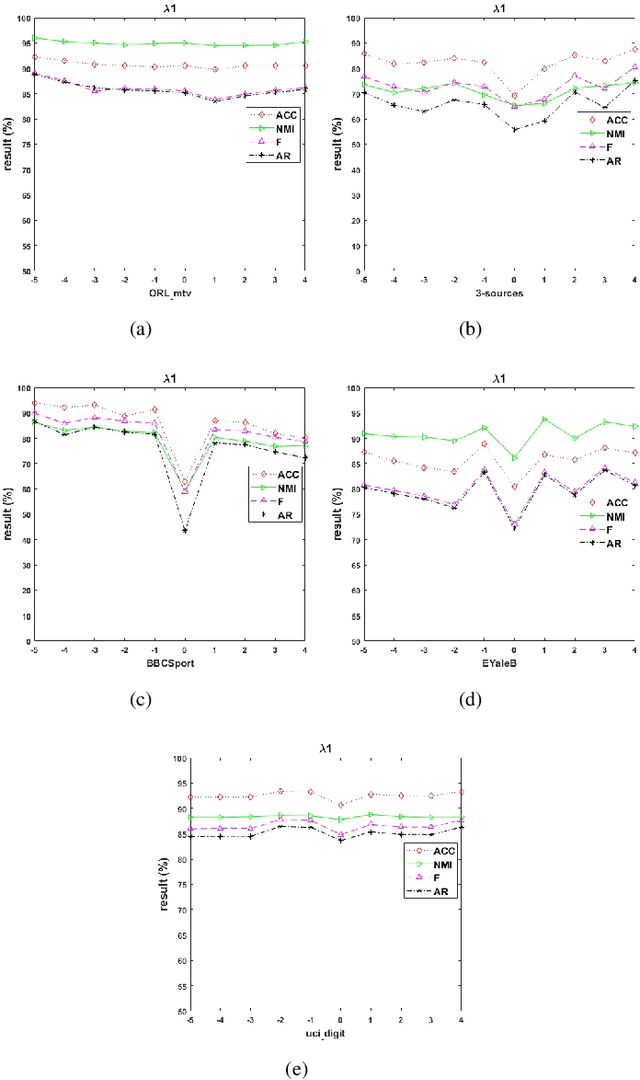
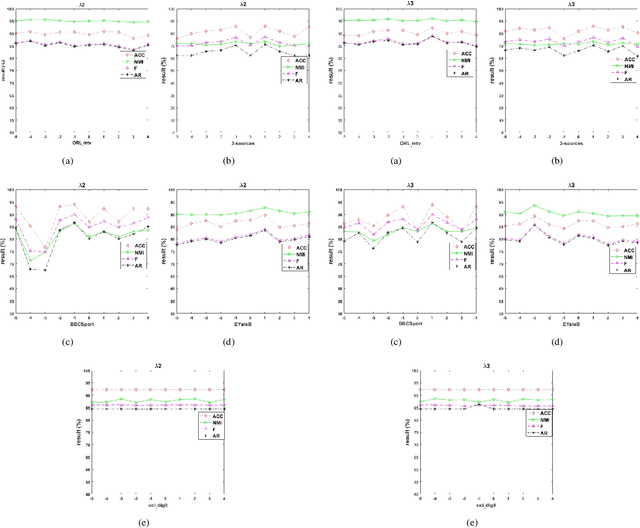
Multi-view clustering methods have been a focus in recent years because of their superiority in clustering performance. However, typical traditional multi-view clustering algorithms still have shortcomings in some aspects, such as removal of redundant information, utilization of various views and fusion of multi-view features. In view of these problems, this paper proposes a new multi-view clustering method, low-rank subspace multi-view clustering based on adaptive graph regularization. We construct two new data matrix decomposition models into a unified optimization model. In this framework, we address the significance of the common knowledge shared by the cross view and the unique knowledge of each view by presenting new low-rank and sparse constraints on the sparse subspace matrix. To ensure that we achieve effective sparse representation and clustering performance on the original data matrix, adaptive graph regularization and unsupervised clustering constraints are also incorporated in the proposed model to preserve the internal structural features of the data. Finally, the proposed method is compared with several state-of-the-art algorithms. Experimental results for five widely used multi-view benchmarks show that our proposed algorithm surpasses other state-of-the-art methods by a clear margin.
Component Divide-and-Conquer for Real-World Image Super-Resolution
Aug 05, 2020In this paper, we present a large-scale Diverse Real-world image Super-Resolution dataset, i.e., DRealSR, as well as a divide-and-conquer Super-Resolution (SR) network, exploring the utility of guiding SR model with low-level image components. DRealSR establishes a new SR benchmark with diverse real-world degradation processes, mitigating the limitations of conventional simulated image degradation. In general, the targets of SR vary with image regions with different low-level image components, e.g., smoothness preserving for flat regions, sharpening for edges, and detail enhancing for textures. Learning an SR model with conventional pixel-wise loss usually is easily dominated by flat regions and edges, and fails to infer realistic details of complex textures. We propose a Component Divide-and-Conquer (CDC) model and a Gradient-Weighted (GW) loss for SR. Our CDC parses an image with three components, employs three Component-Attentive Blocks (CABs) to learn attentive masks and intermediate SR predictions with an intermediate supervision learning strategy, and trains an SR model following a divide-and-conquer learning principle. Our GW loss also provides a feasible way to balance the difficulties of image components for SR. Extensive experiments validate the superior performance of our CDC and the challenging aspects of our DRealSR dataset related to diverse real-world scenarios. Our dataset and codes are publicly available at https://github.com/xiezw5/Component-Divide-and-Conquer-for-Real-World-Image-Super-Resolution
Adversarial Graph Representation Adaptation for Cross-Domain Facial Expression Recognition
Aug 04, 2020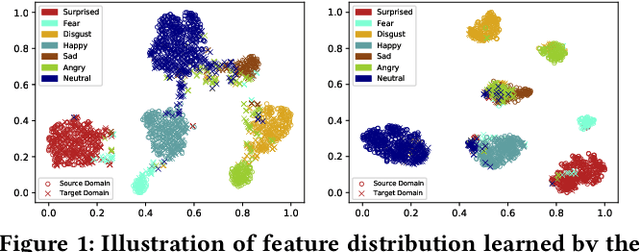
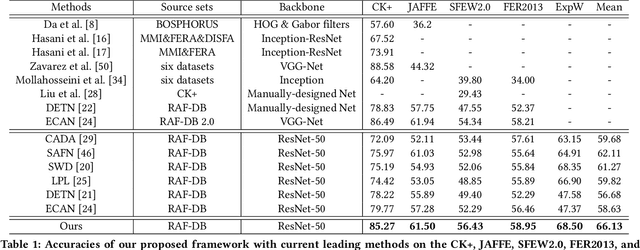
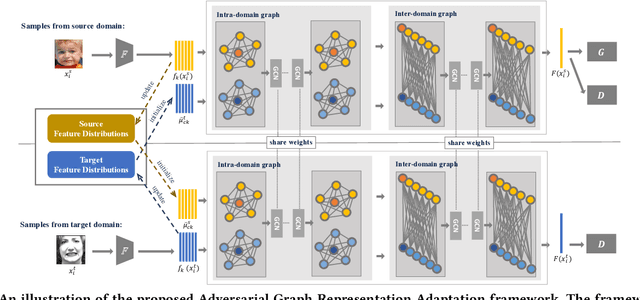
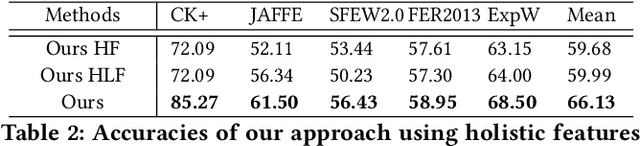
Data inconsistency and bias are inevitable among different facial expression recognition (FER) datasets due to subjective annotating process and different collecting conditions. Recent works resort to adversarial mechanisms that learn domain-invariant features to mitigate domain shift. However, most of these works focus on holistic feature adaptation, and they ignore local features that are more transferable across different datasets. Moreover, local features carry more detailed and discriminative content for expression recognition, and thus integrating local features may enable fine-grained adaptation. In this work, we propose a novel Adversarial Graph Representation Adaptation (AGRA) framework that unifies graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation. To achieve this, we first build a graph to correlate holistic and local regions within each domain and another graph to correlate these regions across different domains. Then, we learn the per-class statistical distribution of each domain and extract holistic-local features from the input image to initialize the corresponding graph nodes. Finally, we introduce two stacked graph convolution networks to propagate holistic-local feature within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. In this way, the AGRA framework can adaptively learn fine-grained domain-invariant features and thus facilitate cross-domain expression recognition. We conduct extensive and fair experiments on several popular benchmarks and show that the proposed AGRA framework achieves superior performance over previous state-of-the-art methods.
Fine-Grained Image Captioning with Global-Local Discriminative Objective
Jul 21, 2020

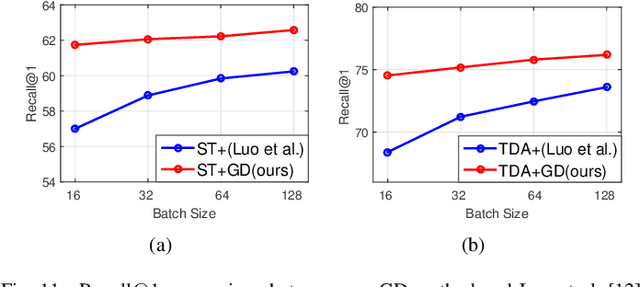
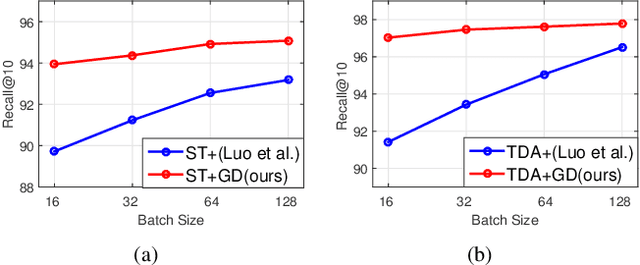
Significant progress has been made in recent years in image captioning, an active topic in the fields of vision and language. However, existing methods tend to yield overly general captions and consist of some of the most frequent words/phrases, resulting in inaccurate and indistinguishable descriptions (see Figure 1). This is primarily due to (i) the conservative characteristic of traditional training objectives that drives the model to generate correct but hardly discriminative captions for similar images and (ii) the uneven word distribution of the ground-truth captions, which encourages generating highly frequent words/phrases while suppressing the less frequent but more concrete ones. In this work, we propose a novel global-local discriminative objective that is formulated on top of a reference model to facilitate generating fine-grained descriptive captions. Specifically, from a global perspective, we design a novel global discriminative constraint that pulls the generated sentence to better discern the corresponding image from all others in the entire dataset. From the local perspective, a local discriminative constraint is proposed to increase attention such that it emphasizes the less frequent but more concrete words/phrases, thus facilitating the generation of captions that better describe the visual details of the given images. We evaluate the proposed method on the widely used MS-COCO dataset, where it outperforms the baseline methods by a sizable margin and achieves competitive performance over existing leading approaches. We also conduct self-retrieval experiments to demonstrate the discriminability of the proposed method.
EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
Jul 06, 2020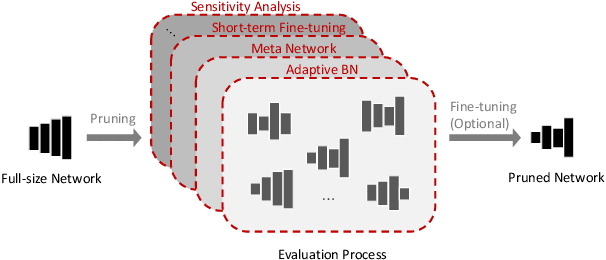
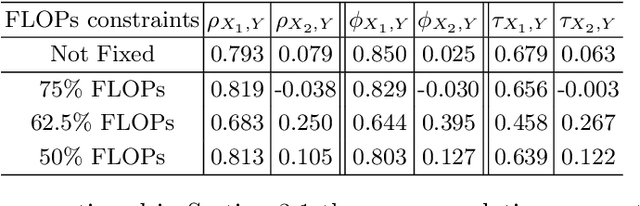
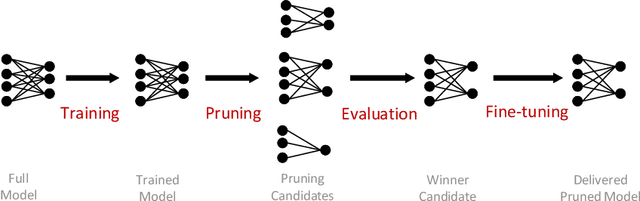
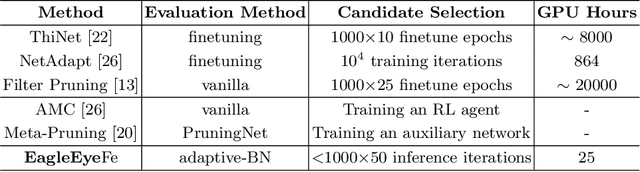
Finding out the computational redundant part of a trained Deep Neural Network (DNN) is the key question that pruning algorithms target on. Many algorithms try to predict model performance of the pruned sub-nets by introducing various evaluation methods. But they are either inaccurate or very complicated for general application. In this work, we present a pruning method called EagleEye, in which a simple yet efficient evaluation component based on adaptive batch normalization is applied to unveil a strong correlation between different pruned DNN structures and their final settled accuracy. This strong correlation allows us to fast spot the pruned candidates with highest potential accuracy without actually fine-tuning them. This module is also general to plug-in and improve some existing pruning algorithms. EagleEye achieves better pruning performance than all of the studied pruning algorithms in our experiments. Concretely, to prune MobileNet V1 and ResNet-50, EagleEye outperforms all compared methods by up to 3.8%. Even in the more challenging experiments of pruning the compact model of MobileNet V1, EagleEye achieves the highest accuracy of 70.9% with an overall 50% operations (FLOPs) pruned. All accuracy results are Top-1 ImageNet classification accuracy. Source code and models are accessible to open-source community https://github.com/anonymous47823493/EagleEye .
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
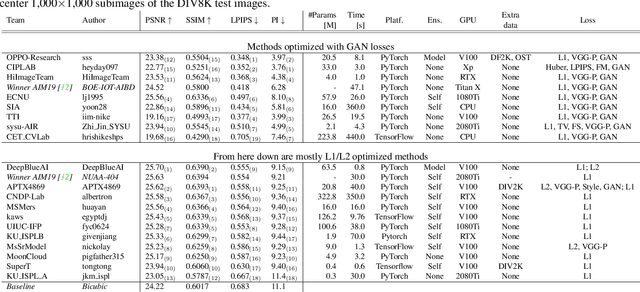

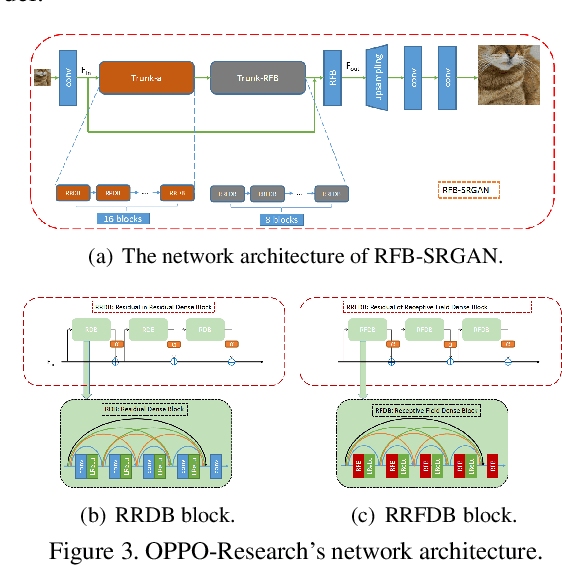
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Efficient Crowd Counting via Structured Knowledge Transfer
Apr 26, 2020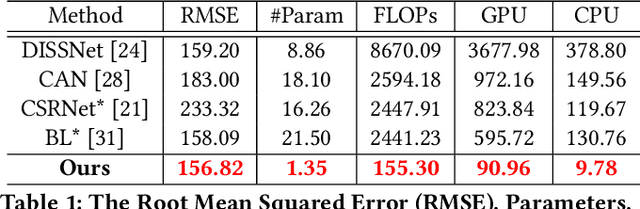
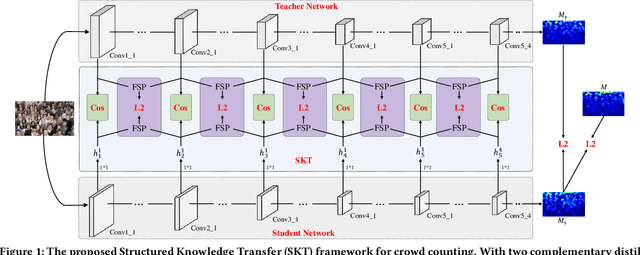

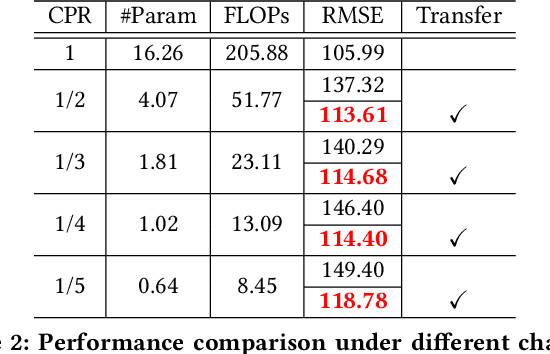
Crowd counting is an application-oriented task and its inference efficiency is crucial for real-world applications. However, most previous works relied on heavy backbone networks and required prohibitive run-time consumption, which would seriously restrict their deployment scopes and cause poor scalability. To liberate these crowd counting models, we propose a novel Structured Knowledge Transfer (SKT) framework, which fully exploits the structured knowledge of a well-trained teacher network to generate a lightweight but still highly effective student network. Specifically, it is integrated with two complementary transfer modules, including an Intra-Layer Pattern Transfer which sequentially distills the knowledge embedded in layer-wise features of the teacher network to guide feature learning of the student network and an Inter-Layer Relation Transfer which densely distills the cross-layer correlation knowledge of the teacher to regularize the student's feature evolution. In this way, our student network can derive the layer-wise and cross-layer knowledge from the teacher network to learn compact yet effective features. Extensive evaluations on three benchmarks well demonstrate the effectiveness of our SKT for extensive crowd counting models. In particular, only using around $6\%$ of the parameters and computation cost of original models, our distilled VGG-based models obtain at least 6.5$\times$ speed-up on an Nvidia 1080 GPU and even achieve state-of-the-art performance.
Bidirectional Graph Reasoning Network for Panoptic Segmentation
Apr 14, 2020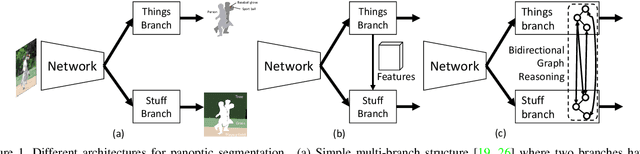
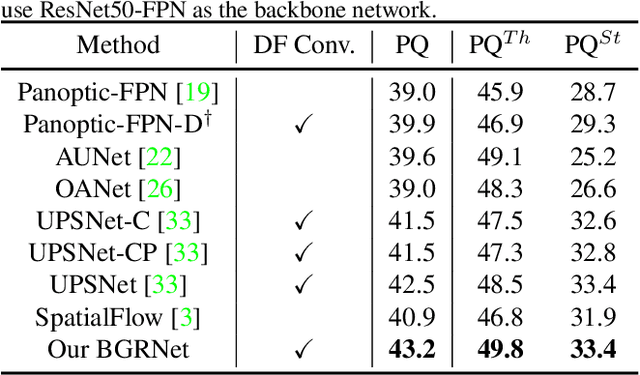
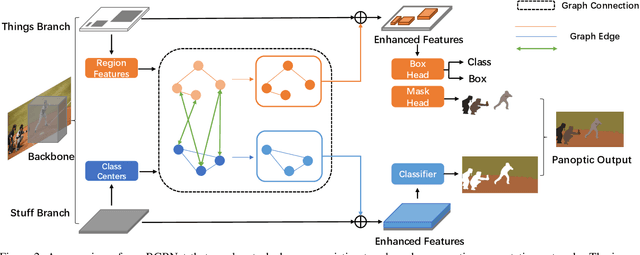

Recent researches on panoptic segmentation resort to a single end-to-end network to combine the tasks of instance segmentation and semantic segmentation. However, prior models only unified the two related tasks at the architectural level via a multi-branch scheme or revealed the underlying correlation between them by unidirectional feature fusion, which disregards the explicit semantic and co-occurrence relations among objects and background. Inspired by the fact that context information is critical to recognize and localize the objects, and inclusive object details are significant to parse the background scene, we thus investigate on explicitly modeling the correlations between object and background to achieve a holistic understanding of an image in the panoptic segmentation task. We introduce a Bidirectional Graph Reasoning Network (BGRNet), which incorporates graph structure into the conventional panoptic segmentation network to mine the intra-modular and intermodular relations within and between foreground things and background stuff classes. In particular, BGRNet first constructs image-specific graphs in both instance and semantic segmentation branches that enable flexible reasoning at the proposal level and class level, respectively. To establish the correlations between separate branches and fully leverage the complementary relations between things and stuff, we propose a Bidirectional Graph Connection Module to diffuse information across branches in a learnable fashion. Experimental results demonstrate the superiority of our BGRNet that achieves the new state-of-the-art performance on challenging COCO and ADE20K panoptic segmentation benchmarks.
Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person Re-identification With Deep Mis-Ranking
Apr 08, 2020
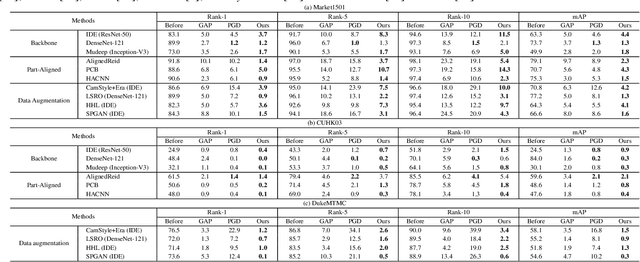
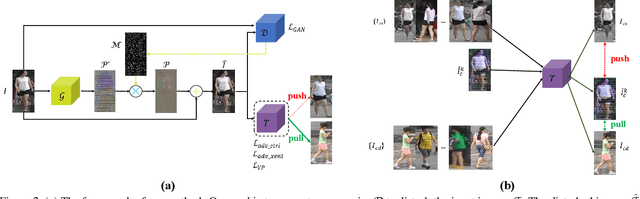
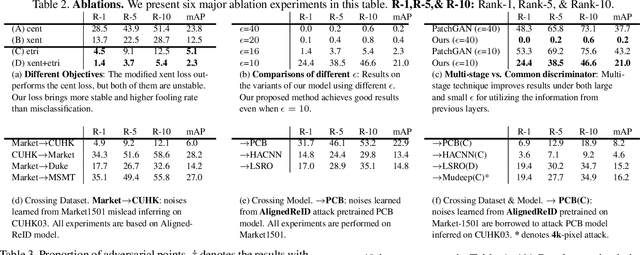
The success of DNNs has driven the extensive applications of person re-identification (ReID) into a new era. However, whether ReID inherits the vulnerability of DNNs remains unexplored. To examine the robustness of ReID systems is rather important because the insecurity of ReID systems may cause severe losses, e.g., the criminals may use the adversarial perturbations to cheat the CCTV systems. In this work, we examine the insecurity of current best-performing ReID models by proposing a learning-to-mis-rank formulation to perturb the ranking of the system output. As the cross-dataset transferability is crucial in the ReID domain, we also perform a back-box attack by developing a novel multi-stage network architecture that pyramids the features of different levels to extract general and transferable features for the adversarial perturbations. Our method can control the number of malicious pixels by using differentiable multi-shot sampling. To guarantee the inconspicuousness of the attack, we also propose a new perception loss to achieve better visual quality. Extensive experiments on four of the largest ReID benchmarks (i.e., Market1501 [45], CUHK03 [18], DukeMTMC [33], and MSMT17 [40]) not only show the effectiveness of our method, but also provides directions of the future improvement in the robustness of ReID systems. For example, the accuracy of one of the best-performing ReID systems drops sharply from 91.8% to 1.4% after being attacked by our method. Some attack results are shown in Fig. 1. The code is available at https://github.com/whj363636/Adversarial-attack-on-Person-ReID-With-Deep-Mis-Ranking.
Linguistically Driven Graph Capsule Network for Visual Question Reasoning
Mar 23, 2020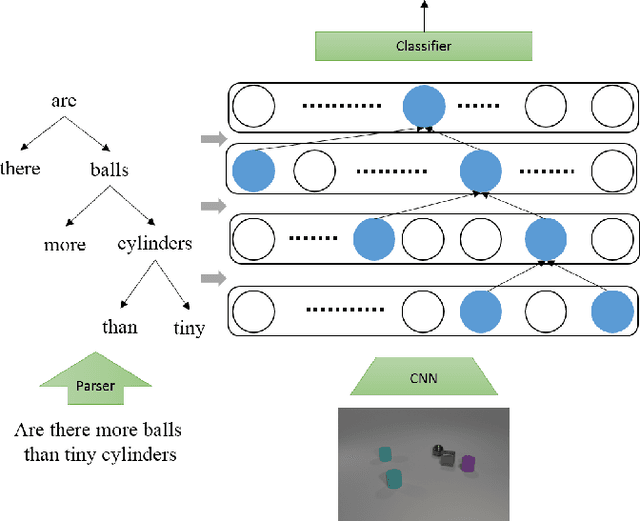
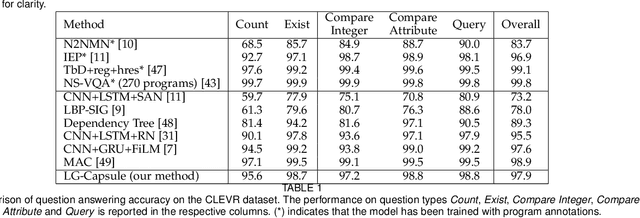
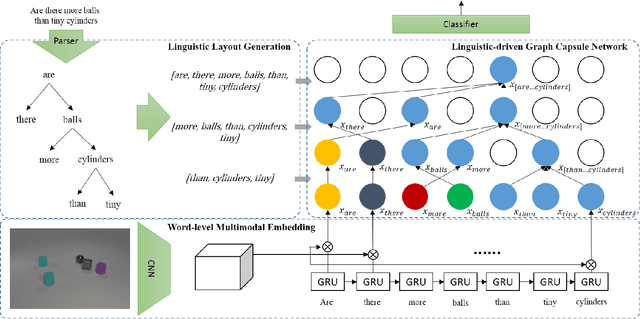

Recently, studies of visual question answering have explored various architectures of end-to-end networks and achieved promising results on both natural and synthetic datasets, which require explicitly compositional reasoning. However, it has been argued that these black-box approaches lack interpretability of results, and thus cannot perform well on generalization tasks due to overfitting the dataset bias. In this work, we aim to combine the benefits of both sides and overcome their limitations to achieve an end-to-end interpretable structural reasoning for general images without the requirement of layout annotations. Inspired by the property of a capsule network that can carve a tree structure inside a regular convolutional neural network (CNN), we propose a hierarchical compositional reasoning model called the "Linguistically driven Graph Capsule Network", where the compositional process is guided by the linguistic parse tree. Specifically, we bind each capsule in the lowest layer to bridge the linguistic embedding of a single word in the original question with visual evidence and then route them to the same capsule if they are siblings in the parse tree. This compositional process is achieved by performing inference on a linguistically driven conditional random field (CRF) and is performed across multiple graph capsule layers, which results in a compositional reasoning process inside a CNN. Experiments on the CLEVR dataset, CLEVR compositional generation test, and FigureQA dataset demonstrate the effectiveness and composition generalization ability of our end-to-end model.