 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Temporal Encoding Network for Video Instance-level Human Parsing
Paper and Code

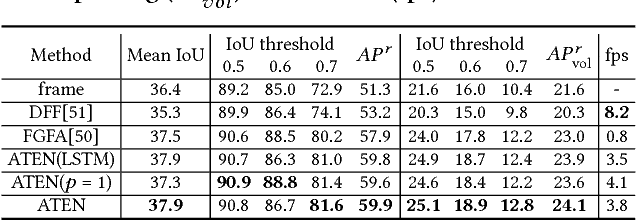
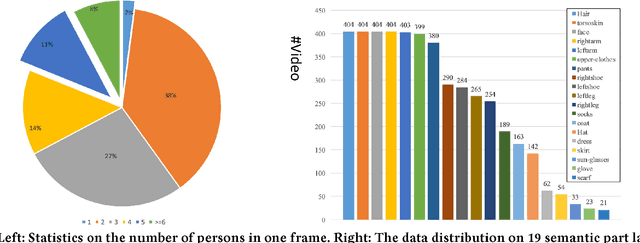
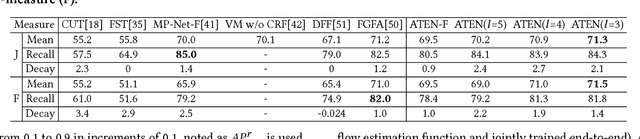
Beyond the existing single-person and multiple-person human parsing tasks in static images, this paper makes the first attempt to investigate a more realistic video instance-level human parsing that simultaneously segments out each person instance and parses each instance into more fine-grained parts (e.g., head, leg, dress). We introduce a novel Adaptive Temporal Encoding Network (ATEN) that alternatively performs temporal encoding among key frames and flow-guided feature propagation from other consecutive frames between two key frames. Specifically, ATEN first incorporates a Parsing-RCNN to produce the instance-level parsing result for each key frame, which integrates both the global human parsing and instance-level human segmentation into a unified model. To balance between accuracy and efficiency, the flow-guided feature propagation is used to directly parse consecutive frames according to their identified temporal consistency with key frames. On the other hand, ATEN leverages the convolution gated recurrent units (convGRU) to exploit temporal changes over a series of key frames, which are further used to facilitate the frame-level instance-level parsing. By alternatively performing direct feature propagation between consistent frames and temporal encoding network among key frames, our ATEN achieves a good balance between frame-level accuracy and time efficiency, which is a common crucial problem in video object segmentation research. To demonstrate the superiority of our ATEN, extensive experiments are conducted on the most popular video segmentation benchmark (DAVIS) and a newly collected Video Instance-level Parsing (VIP) dataset, which is the first video instance-level human parsing dataset comprised of 404 sequences and over 20k frames with instance-level and pixel-wise annotations.