 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV. Coco
Papers and Code
CL-HOI: Cross-Level Human-Object Interaction Distillation from Vision Large Language Models
Oct 21, 2024Human-object interaction (HOI) detection has seen advancements with Vision Language Models (VLMs), but these methods often depend on extensive manual annotations. Vision Large Language Models (VLLMs) can inherently recognize and reason about interactions at the image level but are computationally heavy and not designed for instance-level HOI detection. To overcome these limitations, we propose a Cross-Level HOI distillation (CL-HOI) framework, which distills instance-level HOIs from VLLMs image-level understanding without the need for manual annotations. Our approach involves two stages: context distillation, where a Visual Linguistic Translator (VLT) converts visual information into linguistic form, and interaction distillation, where an Interaction Cognition Network (ICN) reasons about spatial, visual, and context relations. We design contrastive distillation losses to transfer image-level context and interaction knowledge from the teacher to the student model, enabling instance-level HOI detection. Evaluations on HICO-DET and V-COCO datasets demonstrate that our CL-HOI surpasses existing weakly supervised methods and VLLM supervised methods, showing its efficacy in detecting HOIs without manual labels.
UAHOI: Uncertainty-aware Robust Interaction Learning for HOI Detection
Aug 14, 2024
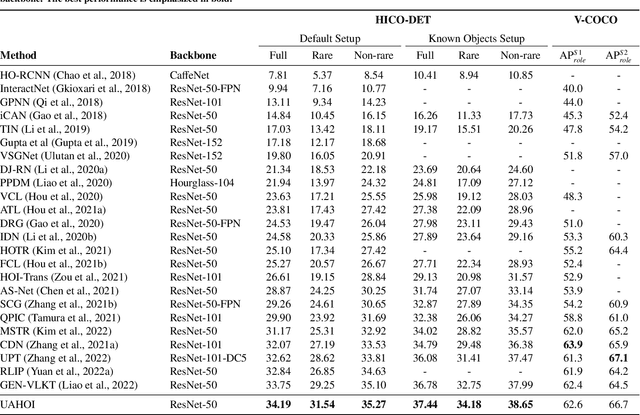
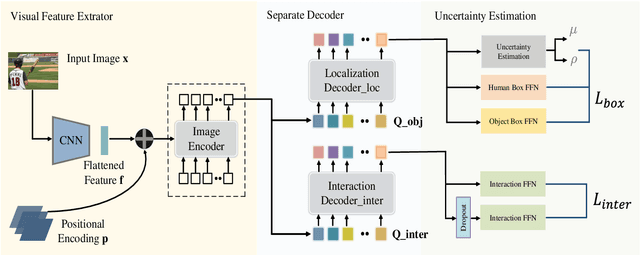
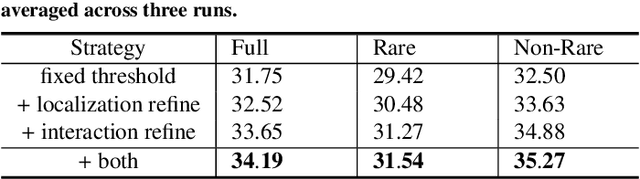
This paper focuses on Human-Object Interaction (HOI) detection, addressing the challenge of identifying and understanding the interactions between humans and objects within a given image or video frame. Spearheaded by Detection Transformer (DETR), recent developments lead to significant improvements by replacing traditional region proposals by a set of learnable queries. However, despite the powerful representation capabilities provided by Transformers, existing Human-Object Interaction (HOI) detection methods still yield low confidence levels when dealing with complex interactions and are prone to overlooking interactive actions. To address these issues, we propose a novel approach \textsc{UAHOI}, Uncertainty-aware Robust Human-Object Interaction Learning that explicitly estimates prediction uncertainty during the training process to refine both detection and interaction predictions. Our model not only predicts the HOI triplets but also quantifies the uncertainty of these predictions. Specifically, we model this uncertainty through the variance of predictions and incorporate it into the optimization objective, allowing the model to adaptively adjust its confidence threshold based on prediction variance. This integration helps in mitigating the adverse effects of incorrect or ambiguous predictions that are common in traditional methods without any hand-designed components, serving as an automatic confidence threshold. Our method is flexible to existing HOI detection methods and demonstrates improved accuracy. We evaluate \textsc{UAHOI} on two standard benchmarks in the field: V-COCO and HICO-DET, which represent challenging scenarios for HOI detection. Through extensive experiments, we demonstrate that \textsc{UAHOI} achieves significant improvements over existing state-of-the-art methods, enhancing both the accuracy and robustness of HOI detection.
CycleHOI: Improving Human-Object Interaction Detection with Cycle Consistency of Detection and Generation
Jul 16, 2024Recognition and generation are two fundamental tasks in computer vision, which are often investigated separately in the exiting literature. However, these two tasks are highly correlated in essence as they both require understanding the underline semantics of visual concepts. In this paper, we propose a new learning framework, coined as CycleHOI, to boost the performance of human-object interaction (HOI) detection by bridging the DETR-based detection pipeline and the pre-trained text-to-image diffusion model. Our key design is to introduce a novel cycle consistency loss for the training of HOI detector, which is able to explicitly leverage the knowledge captured in the powerful diffusion model to guide the HOI detector training. Specifically, we build an extra generation task on top of the decoded instance representations from HOI detector to enforce a detection-generation cycle consistency. Moreover, we perform feature distillation from diffusion model to detector encoder to enhance its representation power. In addition, we further utilize the generation power of diffusion model to augment the training set in both aspects of label correction and sample generation. We perform extensive experiments to verify the effectiveness and generalization power of our CycleHOI with three HOI detection frameworks on two public datasets: HICO-DET and V-COCO. The experimental results demonstrate our CycleHOI can significantly improve the performance of the state-of-the-art HOI detectors.
Visual Counter Turing Test (VCT^2): Discovering the Challenges for AI-Generated Image Detection and Introducing Visual AI Index (V_AI)
Nov 24, 2024



The proliferation of AI techniques for image generation, coupled with their increasing accessibility, has raised significant concerns about the potential misuse of these images to spread misinformation. Recent AI-generated image detection (AGID) methods include CNNDetection, NPR, DM Image Detection, Fake Image Detection, DIRE, LASTED, GAN Image Detection, AIDE, SSP, DRCT, RINE, OCC-CLIP, De-Fake, and Deep Fake Detection. However, we argue that the current state-of-the-art AGID techniques are inadequate for effectively detecting contemporary AI-generated images and advocate for a comprehensive reevaluation of these methods. We introduce the Visual Counter Turing Test (VCT^2), a benchmark comprising ~130K images generated by contemporary text-to-image models (Stable Diffusion 2.1, Stable Diffusion XL, Stable Diffusion 3, DALL-E 3, and Midjourney 6). VCT^2 includes two sets of prompts sourced from tweets by the New York Times Twitter account and captions from the MS COCO dataset. We also evaluate the performance of the aforementioned AGID techniques on the VCT$^2$ benchmark, highlighting their ineffectiveness in detecting AI-generated images. As image-generative AI models continue to evolve, the need for a quantifiable framework to evaluate these models becomes increasingly critical. To meet this need, we propose the Visual AI Index (V_AI), which assesses generated images from various visual perspectives, including texture complexity and object coherence, setting a new standard for evaluating image-generative AI models. To foster research in this domain, we make our https://huggingface.co/datasets/anonymous1233/COCO_AI and https://huggingface.co/datasets/anonymous1233/twitter_AI datasets publicly available.
Geometric Features Enhanced Human-Object Interaction Detection
Jun 26, 2024


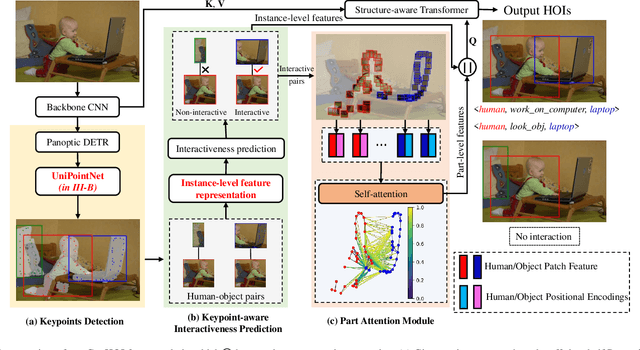
Cameras are essential vision instruments to capture images for pattern detection and measurement. Human-object interaction (HOI) detection is one of the most popular pattern detection approaches for captured human-centric visual scenes. Recently, Transformer-based models have become the dominant approach for HOI detection due to their advanced network architectures and thus promising results. However, most of them follow the one-stage design of vanilla Transformer, leaving rich geometric priors under-exploited and leading to compromised performance especially when occlusion occurs. Given that geometric features tend to outperform visual ones in occluded scenarios and offer information that complements visual cues, we propose a novel end-to-end Transformer-style HOI detection model, i.e., geometric features enhanced HOI detector (GeoHOI). One key part of the model is a new unified self-supervised keypoint learning method named UniPointNet that bridges the gap of consistent keypoint representation across diverse object categories, including humans. GeoHOI effectively upgrades a Transformer-based HOI detector benefiting from the keypoints similarities measuring the likelihood of human-object interactions as well as local keypoint patches to enhance interaction query representation, so as to boost HOI predictions. Extensive experiments show that the proposed method outperforms the state-of-the-art models on V-COCO and achieves competitive performance on HICO-DET. Case study results on the post-disaster rescue with vision-based instruments showcase the applicability of the proposed GeoHOI in real-world applications.
Exploring Interactive Semantic Alignment for Efficient HOI Detection with Vision-language Model
Apr 19, 2024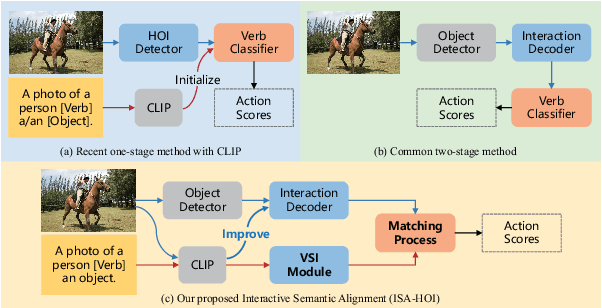
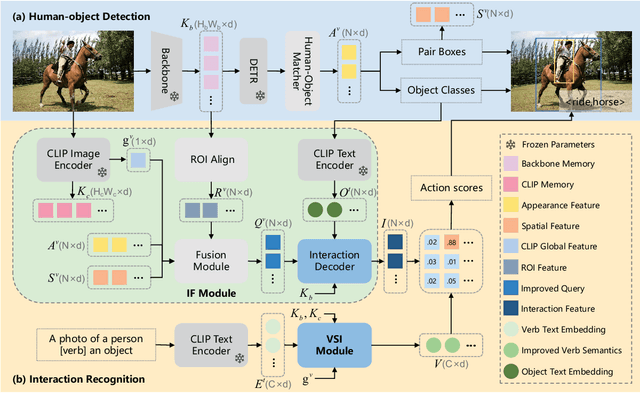
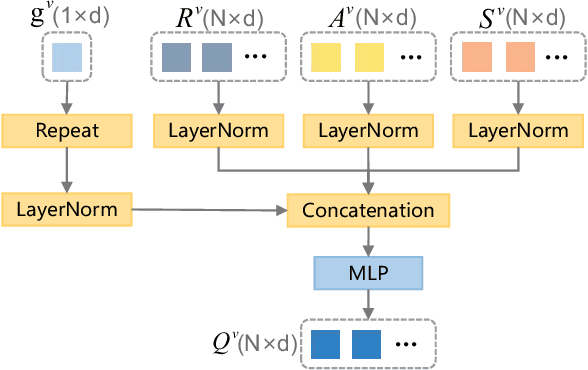

Human-Object Interaction (HOI) detection aims to localize human-object pairs and comprehend their interactions. Recently, two-stage transformer-based methods have demonstrated competitive performance. However, these methods frequently focus on object appearance features and ignore global contextual information. Besides, vision-language model CLIP which effectively aligns visual and text embeddings has shown great potential in zero-shot HOI detection. Based on the former facts, We introduce a novel HOI detector named ISA-HOI, which extensively leverages knowledge from CLIP, aligning interactive semantics between visual and textual features. We first extract global context of image and local features of object to Improve interaction Features in images (IF). On the other hand, we propose a Verb Semantic Improvement (VSI) module to enhance textual features of verb labels via cross-modal fusion. Ultimately, our method achieves competitive results on the HICO-DET and V-COCO benchmarks with much fewer training epochs, and outperforms the state-of-the-art under zero-shot settings.
Towards Zero-shot Human-Object Interaction Detection via Vision-Language Integration
Mar 12, 2024



Human-object interaction (HOI) detection aims to locate human-object pairs and identify their interaction categories in images. Most existing methods primarily focus on supervised learning, which relies on extensive manual HOI annotations. In this paper, we propose a novel framework, termed Knowledge Integration to HOI (KI2HOI), that effectively integrates the knowledge of visual-language model to improve zero-shot HOI detection. Specifically, the verb feature learning module is designed based on visual semantics, by employing the verb extraction decoder to convert corresponding verb queries into interaction-specific category representations. We develop an effective additive self-attention mechanism to generate more comprehensive visual representations. Moreover, the innovative interaction representation decoder effectively extracts informative regions by integrating spatial and visual feature information through a cross-attention mechanism. To deal with zero-shot learning in low-data, we leverage a priori knowledge from the CLIP text encoder to initialize the linear classifier for enhanced interaction understanding. Extensive experiments conducted on the mainstream HICO-DET and V-COCO datasets demonstrate that our model outperforms the previous methods in various zero-shot and full-supervised settings.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024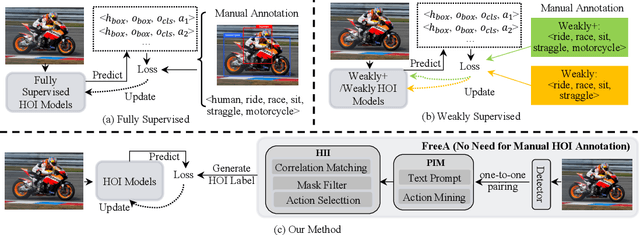
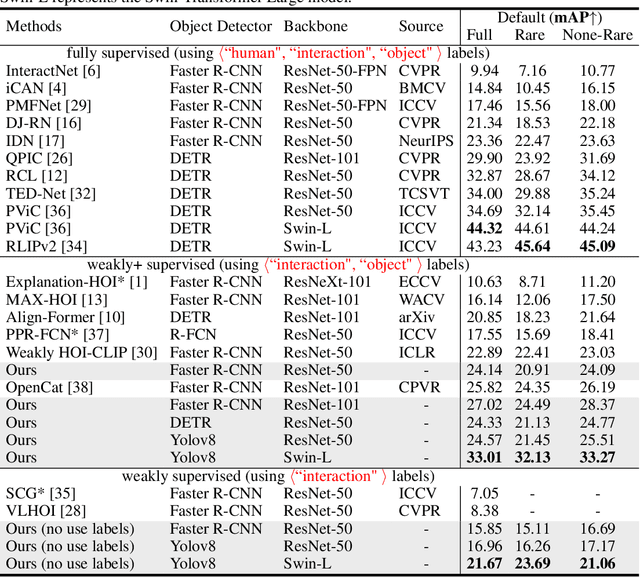
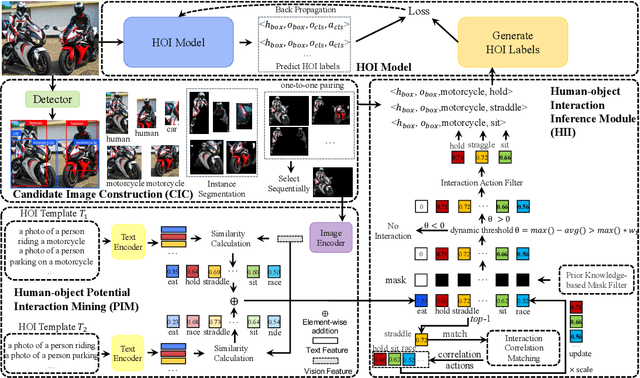
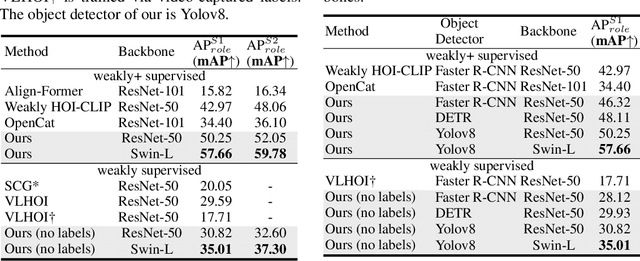
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.
Exploring Self- and Cross-Triplet Correlations for Human-Object Interaction Detection
Jan 11, 2024



Human-Object Interaction (HOI) detection plays a vital role in scene understanding, which aims to predict the HOI triplet in the form of <human, object, action>. Existing methods mainly extract multi-modal features (e.g., appearance, object semantics, human pose) and then fuse them together to directly predict HOI triplets. However, most of these methods focus on seeking for self-triplet aggregation, but ignore the potential cross-triplet dependencies, resulting in ambiguity of action prediction. In this work, we propose to explore Self- and Cross-Triplet Correlations (SCTC) for HOI detection. Specifically, we regard each triplet proposal as a graph where Human, Object represent nodes and Action indicates edge, to aggregate self-triplet correlation. Also, we try to explore cross-triplet dependencies by jointly considering instance-level, semantic-level, and layout-level relations. Besides, we leverage the CLIP model to assist our SCTC obtain interaction-aware feature by knowledge distillation, which provides useful action clues for HOI detection. Extensive experiments on HICO-DET and V-COCO datasets verify the effectiveness of our proposed SCTC.
UnionDet: Union-Level Detector Towards Real-Time Human-Object Interaction Detection
Dec 19, 2023Recent advances in deep neural networks have achieved significant progress in detecting individual objects from an image. However, object detection is not sufficient to fully understand a visual scene. Towards a deeper visual understanding, the interactions between objects, especially humans and objects are essential. Most prior works have obtained this information with a bottom-up approach, where the objects are first detected and the interactions are predicted sequentially by pairing the objects. This is a major bottleneck in HOI detection inference time. To tackle this problem, we propose UnionDet, a one-stage meta-architecture for HOI detection powered by a novel union-level detector that eliminates this additional inference stage by directly capturing the region of interaction. Our one-stage detector for human-object interaction shows a significant reduction in interaction prediction time 4x~14x while outperforming state-of-the-art methods on two public datasets: V-COCO and HICO-DET.