 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Super Resolution
Audio super resolution is the process of enhancing the quality of audio signals by increasing the sampling rate or frequency.
Papers and Code
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
FastWave: Optimized Diffusion Model for Audio Super-Resolution
Mar 04, 2026Audio Super-Resolution is a set of techniques aimed at high-quality estimation of the given signal as if it would be sampled with higher sample rate. Among suggested methods there are diffusion and flow models (which are considered slower), generative adversarial networks (which are considered faster), however both approaches are currently presented by high-parametric networks, requiring high computational costs both for training and inference. We propose a solution to both these problems by re-considering the recent advances in the training of diffusion models and applying them to super-resolution from any to 48 kHz sample rate. Our approach shows better results than NU-Wave 2 and is comparable to state-of-the-art models. Our model called FastWave has around 50 GFLOPs of computational complexity and 1.3 M parameters and can be trained with less resources and significantly faster than the majority of recently proposed diffusion- and flow-based solutions. The code has been made publicly available.
SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
Discriminating real and synthetic super-resolved audio samples using embedding-based classifiers
Jan 06, 2026Generative adversarial networks (GANs) and diffusion models have recently achieved state-of-the-art performance in audio super-resolution (ADSR), producing perceptually convincing wideband audio from narrowband inputs. However, existing evaluations primarily rely on signal-level or perceptual metrics, leaving open the question of how closely the distributions of synthetic super-resolved and real wideband audio match. Here we address this problem by analyzing the separability of real and super-resolved audio in various embedding spaces. We consider both middle-band ($4\to 16$~kHz) and full-band ($16\to 48$~kHz) upsampling tasks for speech and music, training linear classifiers to distinguish real from synthetic samples based on multiple types of audio embeddings. Comparisons with objective metrics and subjective listening tests reveal that embedding-based classifiers achieve near-perfect separation, even when the generated audio attains high perceptual quality and state-of-the-art metric scores. This behavior is consistent across datasets and models, including recent diffusion-based approaches, highlighting a persistent gap between perceptual quality and true distributional fidelity in ADSR models.
HQ-SVC: Towards High-Quality Zero-Shot Singing Voice Conversion in Low-Resource Scenarios
Nov 15, 2025Zero-shot singing voice conversion (SVC) transforms a source singer's timbre to an unseen target speaker's voice while preserving melodic content without fine-tuning. Existing methods model speaker timbre and vocal content separately, losing essential acoustic information that degrades output quality while requiring significant computational resources. To overcome these limitations, we propose HQ-SVC, an efficient framework for high-quality zero-shot SVC. HQ-SVC first extracts jointly content and speaker features using a decoupled codec. It then enhances fidelity through pitch and volume modeling, preserving critical acoustic information typically lost in separate modeling approaches, and progressively refines outputs via differentiable signal processing and diffusion techniques. Evaluations confirm HQ-SVC significantly outperforms state-of-the-art zero-shot SVC methods in conversion quality and efficiency. Beyond voice conversion, HQ-SVC achieves superior voice naturalness compared to specialized audio super-resolution methods while natively supporting voice super-resolution tasks.
UniverSR: Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching
Oct 01, 2025In this paper, we present a vocoder-free framework for audio super-resolution that employs a flow matching generative model to capture the conditional distribution of complex-valued spectral coefficients. Unlike conventional two-stage diffusion-based approaches that predict a mel-spectrogram and then rely on a pre-trained neural vocoder to synthesize waveforms, our method directly reconstructs waveforms via the inverse Short-Time Fourier Transform (iSTFT), thereby eliminating the dependence on a separate vocoder. This design not only simplifies end-to-end optimization but also overcomes a critical bottleneck of two-stage pipelines, where the final audio quality is fundamentally constrained by vocoder performance. Experiments show that our model consistently produces high-fidelity 48 kHz audio across diverse upsampling factors, achieving state-of-the-art performance on both speech and general audio datasets.
Towards General Modality Translation with Contrastive and Predictive Latent Diffusion Bridge
Oct 23, 2025

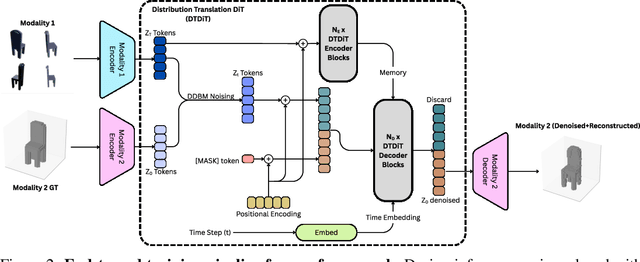

Recent advances in generative modeling have positioned diffusion models as state-of-the-art tools for sampling from complex data distributions. While these models have shown remarkable success across single-modality domains such as images and audio, extending their capabilities to Modality Translation (MT), translating information across different sensory modalities, remains an open challenge. Existing approaches often rely on restrictive assumptions, including shared dimensionality, Gaussian source priors, and modality-specific architectures, which limit their generality and theoretical grounding. In this work, we propose the Latent Denoising Diffusion Bridge Model (LDDBM), a general-purpose framework for modality translation based on a latent-variable extension of Denoising Diffusion Bridge Models. By operating in a shared latent space, our method learns a bridge between arbitrary modalities without requiring aligned dimensions. We introduce a contrastive alignment loss to enforce semantic consistency between paired samples and design a domain-agnostic encoder-decoder architecture tailored for noise prediction in latent space. Additionally, we propose a predictive loss to guide training toward accurate cross-domain translation and explore several training strategies to improve stability. Our approach supports arbitrary modality pairs and performs strongly on diverse MT tasks, including multi-view to 3D shape generation, image super-resolution, and multi-view scene synthesis. Comprehensive experiments and ablations validate the effectiveness of our framework, establishing a new strong baseline in general modality translation. For more information, see our project page: https://sites.google.com/view/lddbm/home.
Ambisonics Super-Resolution Using A Waveform-Domain Neural Network
Aug 01, 2025Ambisonics is a spatial audio format describing a sound field. First-order Ambisonics (FOA) is a popular format comprising only four channels. This limited channel count comes at the expense of spatial accuracy. Ideally one would be able to take the efficiency of a FOA format without its limitations. We have devised a data-driven spatial audio solution that retains the efficiency of the FOA format but achieves quality that surpasses conventional renderers. Utilizing a fully convolutional time-domain audio neural network (Conv-TasNet), we created a solution that takes a FOA input and provides a higher order Ambisonics (HOA) output. This data driven approach is novel when compared to typical physics and psychoacoustic based renderers. Quantitative evaluations showed a 0.6dB average positional mean squared error difference between predicted and actual 3rd order HOA. The median qualitative rating showed an 80% improvement in perceived quality over the traditional rendering approach.
Audio-Assisted Face Video Restoration with Temporal and Identity Complementary Learning
Aug 06, 2025
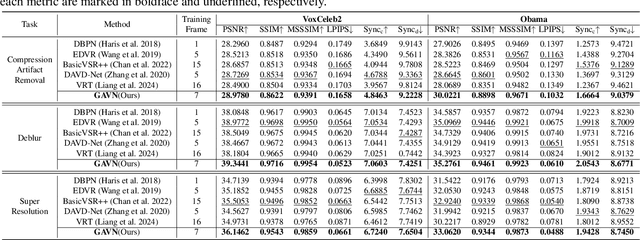
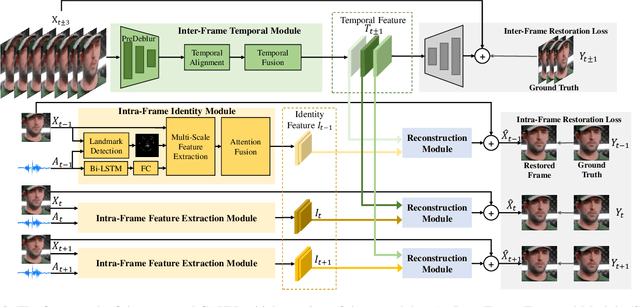
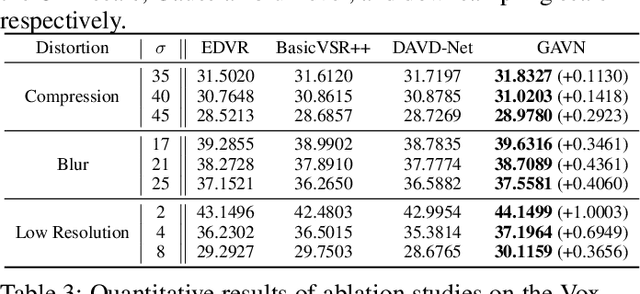
Face videos accompanied by audio have become integral to our daily lives, while they often suffer from complex degradations. Most face video restoration methods neglect the intrinsic correlations between the visual and audio features, especially in mouth regions. A few audio-aided face video restoration methods have been proposed, but they only focus on compression artifact removal. In this paper, we propose a General Audio-assisted face Video restoration Network (GAVN) to address various types of streaming video distortions via identity and temporal complementary learning. Specifically, GAVN first captures inter-frame temporal features in the low-resolution space to restore frames coarsely and save computational cost. Then, GAVN extracts intra-frame identity features in the high-resolution space with the assistance of audio signals and face landmarks to restore more facial details. Finally, the reconstruction module integrates temporal features and identity features to generate high-quality face videos. Experimental results demonstrate that GAVN outperforms the existing state-of-the-art methods on face video compression artifact removal, deblurring, and super-resolution. Codes will be released upon publication.
ClearerVoice-Studio: Bridging Advanced Speech Processing Research and Practical Deployment
Jun 24, 2025This paper introduces ClearerVoice-Studio, an open-source, AI-powered speech processing toolkit designed to bridge cutting-edge research and practical application. Unlike broad platforms like SpeechBrain and ESPnet, ClearerVoice-Studio focuses on interconnected speech tasks of speech enhancement, separation, super-resolution, and multimodal target speaker extraction. A key advantage is its state-of-the-art pretrained models, including FRCRN with 3 million uses and MossFormer with 2.5 million uses, optimized for real-world scenarios. It also offers model optimization tools, multi-format audio support, the SpeechScore evaluation toolkit, and user-friendly interfaces, catering to researchers, developers, and end-users. Its rapid adoption attracting 3000 GitHub stars and 239 forks highlights its academic and industrial impact. This paper details ClearerVoice-Studio's capabilities, architectures, training strategies, benchmarks, community impact, and future plan. Source code is available at https://github.com/modelscope/ClearerVoice-Studio.