 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
FaceRefiner: High-Fidelity Facial Texture Refinement with Differentiable Rendering-based Style Transfer
Jan 08, 2026Recent facial texture generation methods prefer to use deep networks to synthesize image content and then fill in the UV map, thus generating a compelling full texture from a single image. Nevertheless, the synthesized texture UV map usually comes from a space constructed by the training data or the 2D face generator, which limits the methods' generalization ability for in-the-wild input images. Consequently, their facial details, structures and identity may not be consistent with the input. In this paper, we address this issue by proposing a style transfer-based facial texture refinement method named FaceRefiner. FaceRefiner treats the 3D sampled texture as style and the output of a texture generation method as content. The photo-realistic style is then expected to be transferred from the style image to the content image. Different from current style transfer methods that only transfer high and middle level information to the result, our style transfer method integrates differentiable rendering to also transfer low level (or pixel level) information in the visible face regions. The main benefit of such multi-level information transfer is that, the details, structures and semantics in the input can thus be well preserved. The extensive experiments on Multi-PIE, CelebA and FFHQ datasets demonstrate that our refinement method can improve the texture quality and the face identity preserving ability, compared with state-of-the-arts.
SCAdapter: Content-Style Disentanglement for Diffusion Style Transfer
Dec 15, 2025Diffusion models have emerged as the leading approach for style transfer, yet they struggle with photo-realistic transfers, often producing painting-like results or missing detailed stylistic elements. Current methods inadequately address unwanted influence from original content styles and style reference content features. We introduce SCAdapter, a novel technique leveraging CLIP image space to effectively separate and integrate content and style features. Our key innovation systematically extracts pure content from content images and style elements from style references, ensuring authentic transfers. This approach is enhanced through three components: Controllable Style Adaptive Instance Normalization (CSAdaIN) for precise multi-style blending, KVS Injection for targeted style integration, and a style transfer consistency objective maintaining process coherence. Comprehensive experiments demonstrate SCAdapter significantly outperforms state-of-the-art methods in both conventional and diffusion-based baselines. By eliminating DDIM inversion and inference-stage optimization, our method achieves at least $2\times$ faster inference than other diffusion-based approaches, making it both more effective and efficient for practical applications.
Unpaired Image-to-Image Translation with Content Preserving Perspective: A Review
Feb 11, 2025Image-to-image translation (I2I) transforms an image from a source domain to a target domain while preserving source content. Most computer vision applications are in the field of image-to-image translation, such as style transfer, image segmentation, and photo enhancement. The degree of preservation of the content of the source images in the translation process can be different according to the problem and the intended application. From this point of view, in this paper, we divide the different tasks in the field of image-to-image translation into three categories: Fully Content preserving, Partially Content preserving, and Non-Content preserving. We present different tasks, datasets, methods, results of methods for these three categories in this paper. We make a categorization for I2I methods based on the architecture of different models and study each category separately. In addition, we introduce well-known evaluation criteria in the I2I translation field. Specifically, nearly 70 different I2I models were analyzed, and more than 10 quantitative evaluation metrics and 30 distinct tasks and datasets relevant to the I2I translation problem were both introduced and assessed. Translating from simulation to real images could be well viewed as an application of fully content preserving or partially content preserving unsupervised image-to-image translation methods. So, we provide a benchmark for Sim-to-Real translation, which can be used to evaluate different methods. In general, we conclude that because of the different extent of the obligation to preserving content in various applications, it is better to consider this issue in choosing a suitable I2I model for a specific application.
PhotoDoodle: Learning Artistic Image Editing from Few-Shot Pairwise Data
Feb 23, 2025We introduce PhotoDoodle, a novel image editing framework designed to facilitate photo doodling by enabling artists to overlay decorative elements onto photographs. Photo doodling is challenging because the inserted elements must appear seamlessly integrated with the background, requiring realistic blending, perspective alignment, and contextual coherence. Additionally, the background must be preserved without distortion, and the artist's unique style must be captured efficiently from limited training data. These requirements are not addressed by previous methods that primarily focus on global style transfer or regional inpainting. The proposed method, PhotoDoodle, employs a two-stage training strategy. Initially, we train a general-purpose image editing model, OmniEditor, using large-scale data. Subsequently, we fine-tune this model with EditLoRA using a small, artist-curated dataset of before-and-after image pairs to capture distinct editing styles and techniques. To enhance consistency in the generated results, we introduce a positional encoding reuse mechanism. Additionally, we release a PhotoDoodle dataset featuring six high-quality styles. Extensive experiments demonstrate the advanced performance and robustness of our method in customized image editing, opening new possibilities for artistic creation.
Protégé: Learn and Generate Basic Makeup Styles with Generative Adversarial Networks (GANs)
Dec 29, 2024



Makeup is no longer confined to physical application; people now use mobile apps to digitally apply makeup to their photos, which they then share on social media. However, while this shift has made makeup more accessible, designing diverse makeup styles tailored to individual faces remains a challenge. This challenge currently must still be done manually by humans. Existing systems, such as makeup recommendation engines and makeup transfer techniques, offer limitations in creating innovative makeups for different individuals "intuitively" -- significant user effort and knowledge needed and limited makeup options available in app. Our motivation is to address this challenge by proposing Prot\'eg\'e, a new makeup application, leveraging recent generative model -- GANs to learn and automatically generate makeup styles. This is a task that existing makeup applications (i.e., makeup recommendation systems using expert system and makeup transfer methods) are unable to perform. Extensive experiments has been conducted to demonstrate the capability of Prot\'eg\'e in learning and creating diverse makeups, providing a convenient and intuitive way, marking a significant leap in digital makeup technology!
INRetouch: Context Aware Implicit Neural Representation for Photography Retouching
Dec 05, 2024



Professional photo editing remains challenging, requiring extensive knowledge of imaging pipelines and significant expertise. With the ubiquity of smartphone photography, there is an increasing demand for accessible yet sophisticated image editing solutions. While recent deep learning approaches, particularly style transfer methods, have attempted to automate this process, they often struggle with output fidelity, editing control, and complex retouching capabilities. We propose a novel retouch transfer approach that learns from professional edits through before-after image pairs, enabling precise replication of complex editing operations. To facilitate this research direction, we introduce a comprehensive Photo Retouching Dataset comprising 100,000 high-quality images edited using over 170 professional Adobe Lightroom presets. We develop a context-aware Implicit Neural Representation that learns to apply edits adaptively based on image content and context, requiring no pretraining and capable of learning from a single example. Our method extracts implicit transformations from reference edits and adaptively applies them to new images. Through extensive evaluation, we demonstrate that our approach not only surpasses existing methods in photo retouching but also enhances performance in related image reconstruction tasks like Gamut Mapping and Raw Reconstruction. By bridging the gap between professional editing capabilities and automated solutions, our work presents a significant step toward making sophisticated photo editing more accessible while maintaining high-fidelity results. Check the $\href{https://omaralezaby.github.io/inretouch}{Project\ Page}$ for more Results and information about Code and Dataset availability.
SenCLIP: Enhancing zero-shot land-use mapping for Sentinel-2 with ground-level prompting
Dec 11, 2024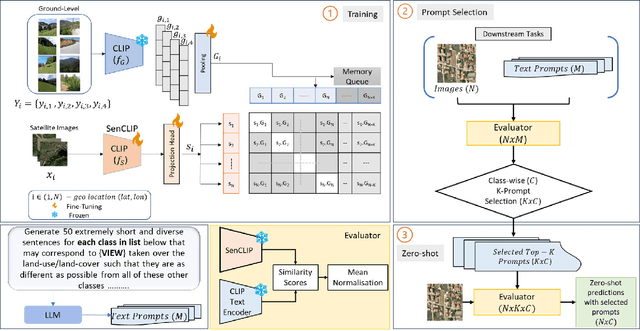
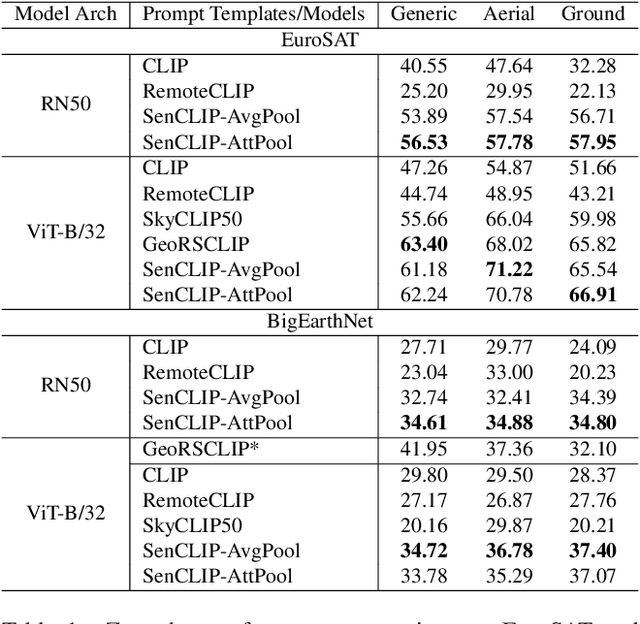
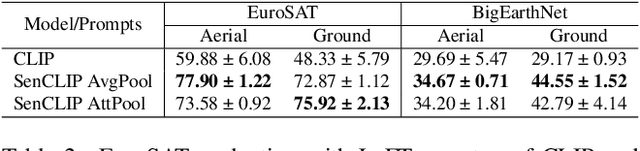
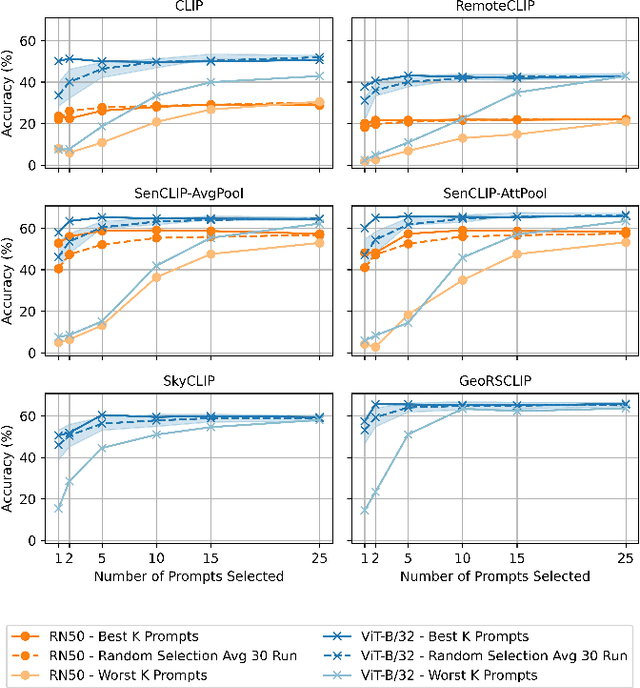
Pre-trained vision-language models (VLMs), such as CLIP, demonstrate impressive zero-shot classification capabilities with free-form prompts and even show some generalization in specialized domains. However, their performance on satellite imagery is limited due to the underrepresentation of such data in their training sets, which predominantly consist of ground-level images. Existing prompting techniques for satellite imagery are often restricted to generic phrases like a satellite image of ..., limiting their effectiveness for zero-shot land-use and land-cover (LULC) mapping. To address these challenges, we introduce SenCLIP, which transfers CLIPs representation to Sentinel-2 imagery by leveraging a large dataset of Sentinel-2 images paired with geotagged ground-level photos from across Europe. We evaluate SenCLIP alongside other SOTA remote sensing VLMs on zero-shot LULC mapping tasks using the EuroSAT and BigEarthNet datasets with both aerial and ground-level prompting styles. Our approach, which aligns ground-level representations with satellite imagery, demonstrates significant improvements in classification accuracy across both prompt styles, opening new possibilities for applying free-form textual descriptions in zero-shot LULC mapping.
DRDM: A Disentangled Representations Diffusion Model for Synthesizing Realistic Person Images
Dec 25, 2024Person image synthesis with controllable body poses and appearances is an essential task owing to the practical needs in the context of virtual try-on, image editing and video production. However, existing methods face significant challenges with details missing, limbs distortion and the garment style deviation. To address these issues, we propose a Disentangled Representations Diffusion Model (DRDM) to generate photo-realistic images from source portraits in specific desired poses and appearances. First, a pose encoder is responsible for encoding pose features into a high-dimensional space to guide the generation of person images. Second, a body-part subspace decoupling block (BSDB) disentangles features from the different body parts of a source figure and feeds them to the various layers of the noise prediction block, thereby supplying the network with rich disentangled features for generating a realistic target image. Moreover, during inference, we develop a parsing map-based disentangled classifier-free guided sampling method, which amplifies the conditional signals of texture and pose. Extensive experimental results on the Deepfashion dataset demonstrate the effectiveness of our approach in achieving pose transfer and appearance control.
IDEA-Bench: How Far are Generative Models from Professional Designing?
Dec 16, 2024



Real-world design tasks - such as picture book creation, film storyboard development using character sets, photo retouching, visual effects, and font transfer - are highly diverse and complex, requiring deep interpretation and extraction of various elements from instructions, descriptions, and reference images. The resulting images often implicitly capture key features from references or user inputs, making it challenging to develop models that can effectively address such varied tasks. While existing visual generative models can produce high-quality images based on prompts, they face significant limitations in professional design scenarios that involve varied forms and multiple inputs and outputs, even when enhanced with adapters like ControlNets and LoRAs. To address this, we introduce IDEA-Bench, a comprehensive benchmark encompassing 100 real-world design tasks, including rendering, visual effects, storyboarding, picture books, fonts, style-based, and identity-preserving generation, with 275 test cases to thoroughly evaluate a model's general-purpose generation capabilities. Notably, even the best-performing model only achieves 22.48 on IDEA-Bench, while the best general-purpose model only achieves 6.81. We provide a detailed analysis of these results, highlighting the inherent challenges and providing actionable directions for improvement. Additionally, we provide a subset of 18 representative tasks equipped with multimodal large language model (MLLM)-based auto-evaluation techniques to facilitate rapid model development and comparison. We releases the benchmark data, evaluation toolkits, and an online leaderboard at https://github.com/ali-vilab/IDEA-Bench, aiming to drive the advancement of generative models toward more versatile and applicable intelligent design systems.
PS-StyleGAN: Illustrative Portrait Sketching using Attention-Based Style Adaptation
Aug 31, 2024Portrait sketching involves capturing identity specific attributes of a real face with abstract lines and shades. Unlike photo-realistic images, a good portrait sketch generation method needs selective attention to detail, making the problem challenging. This paper introduces \textbf{Portrait Sketching StyleGAN (PS-StyleGAN)}, a style transfer approach tailored for portrait sketch synthesis. We leverage the semantic $W+$ latent space of StyleGAN to generate portrait sketches, allowing us to make meaningful edits, like pose and expression alterations, without compromising identity. To achieve this, we propose the use of Attentive Affine transform blocks in our architecture, and a training strategy that allows us to change StyleGAN's output without finetuning it. These blocks learn to modify style latent code by paying attention to both content and style latent features, allowing us to adapt the outputs of StyleGAN in an inversion-consistent manner. Our approach uses only a few paired examples ($\sim 100$) to model a style and has a short training time. We demonstrate PS-StyleGAN's superiority over the current state-of-the-art methods on various datasets, qualitatively and quantitatively.