 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAdapter: Content-Style Disentanglement for Diffusion Style Transfer
Dec 15, 2025Diffusion models have emerged as the leading approach for style transfer, yet they struggle with photo-realistic transfers, often producing painting-like results or missing detailed stylistic elements. Current methods inadequately address unwanted influence from original content styles and style reference content features. We introduce SCAdapter, a novel technique leveraging CLIP image space to effectively separate and integrate content and style features. Our key innovation systematically extracts pure content from content images and style elements from style references, ensuring authentic transfers. This approach is enhanced through three components: Controllable Style Adaptive Instance Normalization (CSAdaIN) for precise multi-style blending, KVS Injection for targeted style integration, and a style transfer consistency objective maintaining process coherence. Comprehensive experiments demonstrate SCAdapter significantly outperforms state-of-the-art methods in both conventional and diffusion-based baselines. By eliminating DDIM inversion and inference-stage optimization, our method achieves at least $2\times$ faster inference than other diffusion-based approaches, making it both more effective and efficient for practical applications.
Constant Rate Schedule: Constant-Rate Distributional Change for Efficient Training and Sampling in Diffusion Models
Nov 19, 2024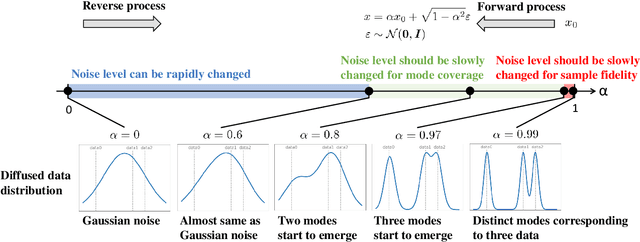



We propose a noise schedule that ensures a constant rate of change in the probability distribution of diffused data throughout the diffusion process. To obtain this noise schedule, we measure the rate of change in the probability distribution of the forward process and use it to determine the noise schedule before training diffusion models. The functional form of the noise schedule is automatically determined and tailored to each dataset and type of diffusion model. We evaluate the effectiveness of our noise schedule on unconditional and class-conditional image generation tasks using the LSUN (bedroom/church/cat/horse), ImageNet, and FFHQ datasets. Through extensive experiments, we confirmed that our noise schedule broadly improves the performance of the diffusion models regardless of the dataset, sampler, number of function evaluations, or type of diffusion model.
Attention as Annotation: Generating Images and Pseudo-masks for Weakly Supervised Semantic Segmentation with Diffusion
Sep 04, 2023Although recent advancements in diffusion models enabled high-fidelity and diverse image generation, training of discriminative models largely depends on collections of massive real images and their manual annotation. Here, we present a training method for semantic segmentation that neither relies on real images nor manual annotation. The proposed method {\it attn2mask} utilizes images generated by a text-to-image diffusion model in combination with its internal text-to-image cross-attention as supervisory pseudo-masks. Since the text-to-image generator is trained with image-caption pairs but without pixel-wise labels, attn2mask can be regarded as a weakly supervised segmentation method overall. Experiments show that attn2mask achieves promising results in PASCAL VOC for not using real training data for segmentation at all, and it is also useful to scale up segmentation to a more-class scenario, i.e., ImageNet segmentation. It also shows adaptation ability with LoRA-based fine-tuning, which enables the transfer to a distant domain i.e., Cityscapes.
Context-Free TextSpotter for Real-Time and Mobile End-to-End Text Detection and Recognition
Jun 10, 2021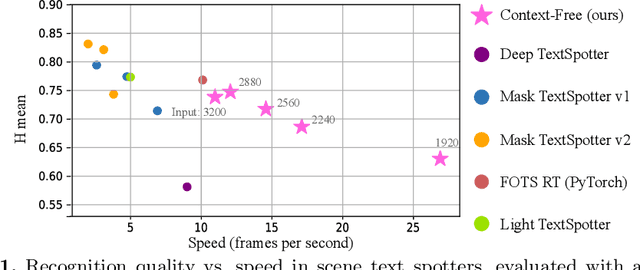

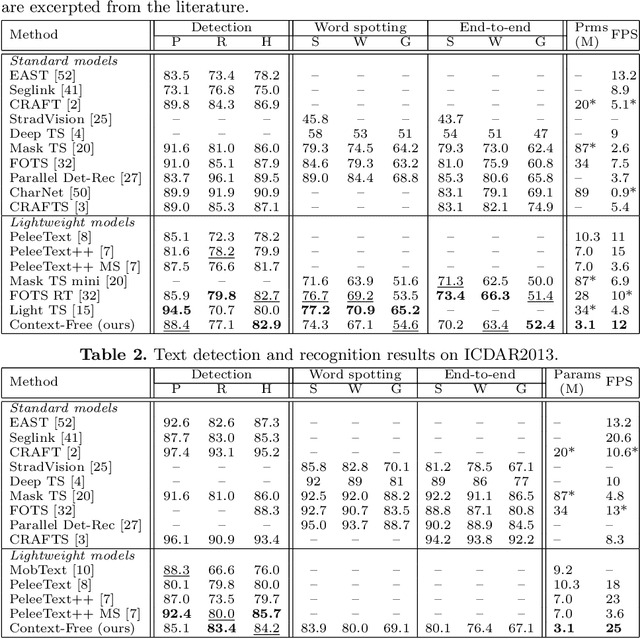
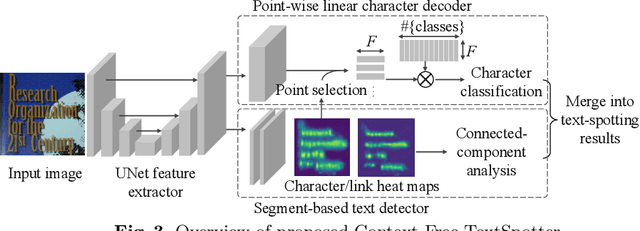
In the deployment of scene-text spotting systems on mobile platforms, lightweight models with low computation are preferable. In concept, end-to-end (E2E) text spotting is suitable for such purposes because it performs text detection and recognition in a single model. However, current state-of-the-art E2E methods rely on heavy feature extractors, recurrent sequence modellings, and complex shape aligners to pursue accuracy, which means their computations are still heavy. We explore the opposite direction: How far can we go without bells and whistles in E2E text spotting? To this end, we propose a text-spotting method that consists of simple convolutions and a few post-processes, named Context-Free TextSpotter. Experiments using standard benchmarks show that Context-Free TextSpotter achieves real-time text spotting on a GPU with only three million parameters, which is the smallest and fastest among existing deep text spotters, with an acceptable transcription quality degradation compared to heavier ones. Further, we demonstrate that our text spotter can run on a smartphone with affordable latency, which is valuable for building stand-alone OCR applications.