 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Blurred And Defocused Dataset
Papers and Code
About an Automating Annotation Method for Robot Markers
Jan 30, 2026Factory automation has become increasingly important due to labor shortages, leading to the introduction of autonomous mobile robots for tasks such as material transportation. Markers are commonly used for robot self-localization and object identification. In the RoboCup Logistics League (RCLL), ArUco markers are employed both for robot localization and for identifying processing modules. Conventional recognition relies on OpenCV-based image processing, which detects black-and-white marker patterns. However, these methods often fail under noise, motion blur, defocus, or varying illumination conditions. Deep-learning-based recognition offers improved robustness under such conditions, but requires large amounts of annotated data. Annotation must typically be done manually, as the type and position of objects cannot be detected automatically, making dataset preparation a major bottleneck. In contrast, ArUco markers include built-in recognition modules that provide both ID and positional information, enabling automatic annotation. This paper proposes an automated annotation method for training deep-learning models on ArUco marker images. By leveraging marker detection results obtained from the ArUco module, the proposed approach eliminates the need for manual labeling. A YOLO-based model is trained using the automatically annotated dataset, and its performance is evaluated under various conditions. Experimental results demonstrate that the proposed method improves recognition performance compared with conventional image-processing techniques, particularly for images affected by blur or defocus. Automatic annotation also reduces human effort and ensures consistent labeling quality. Future work will investigate the relationship between confidence thresholds and recognition performance.
From Code to Field: Evaluating the Robustness of Convolutional Neural Networks for Disease Diagnosis in Mango Leaves
Dec 15, 2025The validation and verification of artificial intelligence (AI) models through robustness assessment are essential to guarantee the reliable performance of intelligent systems facing real-world challenges, such as image corruptions including noise, blurring, and weather variations. Despite the global importance of mango (Mangifera indica L.), there is a lack of studies on the robustness of models for the diagnosis of disease in its leaves. This paper proposes a methodology to evaluate convolutional neural networks (CNNs) under adverse conditions. We adapted the MangoLeafDB dataset, generating MangoLeafDB-C with 19 types of artificial corruptions at five severity levels. We conducted a benchmark comparing five architectures: ResNet-50, ResNet-101, VGG-16, Xception, and LCNN (the latter being a lightweight architecture designed specifically for mango leaf diagnosis). The metrics include the F1 score, the corruption error (CE) and the relative mean corruption error (relative mCE). The results show that LCNN outperformed complex models in corruptions that can be present in real-world scenarios such as Defocus Blur, Motion Blur, while also achieving the lowest mCE. Modern architectures (e.g., ResNet-101) exhibited significant performance degradation in corrupted scenarios, despite their high accuracy under ideal conditions. These findings suggest that lightweight and specialized models may be more suitable for real-world applications in edge devices, where robustness and efficiency are critical. The study highlights the need to incorporate robustness assessments in the development of intelligent systems for agriculture, particularly in regions with technological limitations.
Exploiting Deblurring Networks for Radiance Fields
Feb 20, 2025



In this paper, we propose DeepDeblurRF, a novel radiance field deblurring approach that can synthesize high-quality novel views from blurred training views with significantly reduced training time. DeepDeblurRF leverages deep neural network (DNN)-based deblurring modules to enjoy their deblurring performance and computational efficiency. To effectively combine DNN-based deblurring and radiance field construction, we propose a novel radiance field (RF)-guided deblurring and an iterative framework that performs RF-guided deblurring and radiance field construction in an alternating manner. Moreover, DeepDeblurRF is compatible with various scene representations, such as voxel grids and 3D Gaussians, expanding its applicability. We also present BlurRF-Synth, the first large-scale synthetic dataset for training radiance field deblurring frameworks. We conduct extensive experiments on both camera motion blur and defocus blur, demonstrating that DeepDeblurRF achieves state-of-the-art novel-view synthesis quality with significantly reduced training time.
CodePhys: Robust Video-based Remote Physiological Measurement through Latent Codebook Querying
Feb 11, 2025Remote photoplethysmography (rPPG) aims to measure non-contact physiological signals from facial videos, which has shown great potential in many applications. Most existing methods directly extract video-based rPPG features by designing neural networks for heart rate estimation. Although they can achieve acceptable results, the recovery of rPPG signal faces intractable challenges when interference from real-world scenarios takes place on facial video. Specifically, facial videos are inevitably affected by non-physiological factors (e.g., camera device noise, defocus, and motion blur), leading to the distortion of extracted rPPG signals. Recent rPPG extraction methods are easily affected by interference and degradation, resulting in noisy rPPG signals. In this paper, we propose a novel method named CodePhys, which innovatively treats rPPG measurement as a code query task in a noise-free proxy space (i.e., codebook) constructed by ground-truth PPG signals. We consider noisy rPPG features as queries and generate high-fidelity rPPG features by matching them with noise-free PPG features from the codebook. Our approach also incorporates a spatial-aware encoder network with a spatial attention mechanism to highlight physiologically active areas and uses a distillation loss to reduce the influence of non-periodic visual interference. Experimental results on four benchmark datasets demonstrate that CodePhys outperforms state-of-the-art methods in both intra-dataset and cross-dataset settings.
A New Dataset and Framework for Real-World Blurred Images Super-Resolution
Jul 20, 2024



Recent Blind Image Super-Resolution (BSR) methods have shown proficiency in general images. However, we find that the efficacy of recent methods obviously diminishes when employed on image data with blur, while image data with intentional blur constitute a substantial proportion of general data. To further investigate and address this issue, we developed a new super-resolution dataset specifically tailored for blur images, named the Real-world Blur-kept Super-Resolution (ReBlurSR) dataset, which consists of nearly 3000 defocus and motion blur image samples with diverse blur sizes and varying blur intensities. Furthermore, we propose a new BSR framework for blur images called Perceptual-Blur-adaptive Super-Resolution (PBaSR), which comprises two main modules: the Cross Disentanglement Module (CDM) and the Cross Fusion Module (CFM). The CDM utilizes a dual-branch parallelism to isolate conflicting blur and general data during optimization. The CFM fuses the well-optimized prior from these distinct domains cost-effectively and efficiently based on model interpolation. By integrating these two modules, PBaSR achieves commendable performance on both general and blur data without any additional inference and deployment cost and is generalizable across multiple model architectures. Rich experiments show that PBaSR achieves state-of-the-art performance across various metrics without incurring extra inference costs. Within the widely adopted LPIPS metrics, PBaSR achieves an improvement range of approximately 0.02-0.10 with diverse anchor methods and blur types, across both the ReBlurSR and multiple common general BSR benchmarks. Code here: https://github.com/Imalne/PBaSR.
GAURA: Generalizable Approach for Unified Restoration and Rendering of Arbitrary Views
Jul 11, 2024Neural rendering methods can achieve near-photorealistic image synthesis of scenes from posed input images. However, when the images are imperfect, e.g., captured in very low-light conditions, state-of-the-art methods fail to reconstruct high-quality 3D scenes. Recent approaches have tried to address this limitation by modeling various degradation processes in the image formation model; however, this limits them to specific image degradations. In this paper, we propose a generalizable neural rendering method that can perform high-fidelity novel view synthesis under several degradations. Our method, GAURA, is learning-based and does not require any test-time scene-specific optimization. It is trained on a synthetic dataset that includes several degradation types. GAURA outperforms state-of-the-art methods on several benchmarks for low-light enhancement, dehazing, deraining, and on-par for motion deblurring. Further, our model can be efficiently fine-tuned to any new incoming degradation using minimal data. We thus demonstrate adaptation results on two unseen degradations, desnowing and removing defocus blur. Code and video results are available at vinayak-vg.github.io/GAURA.
Robust Gaussian Splatting
Apr 05, 2024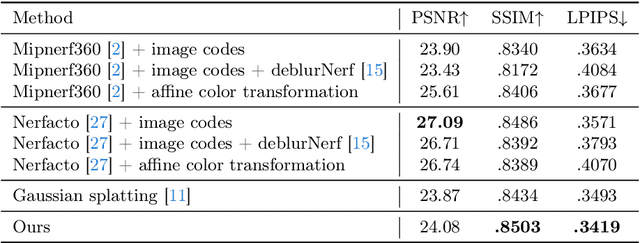

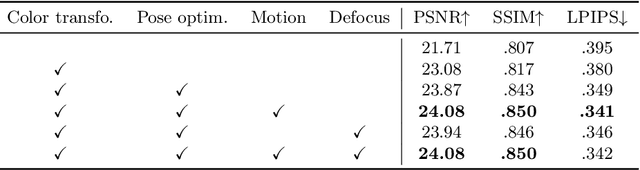

In this paper, we address common error sources for 3D Gaussian Splatting (3DGS) including blur, imperfect camera poses, and color inconsistencies, with the goal of improving its robustness for practical applications like reconstructions from handheld phone captures. Our main contribution involves modeling motion blur as a Gaussian distribution over camera poses, allowing us to address both camera pose refinement and motion blur correction in a unified way. Additionally, we propose mechanisms for defocus blur compensation and for addressing color in-consistencies caused by ambient light, shadows, or due to camera-related factors like varying white balancing settings. Our proposed solutions integrate in a seamless way with the 3DGS formulation while maintaining its benefits in terms of training efficiency and rendering speed. We experimentally validate our contributions on relevant benchmark datasets including Scannet++ and Deblur-NeRF, obtaining state-of-the-art results and thus consistent improvements over relevant baselines.
DeepFormableTag: End-to-end Generation and Recognition of Deformable Fiducial Markers
Jun 16, 2022
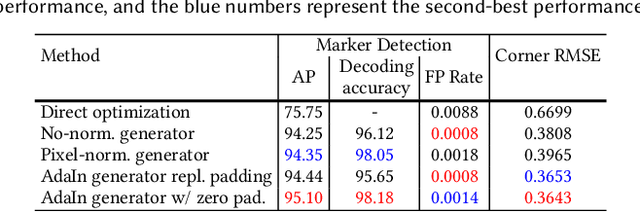
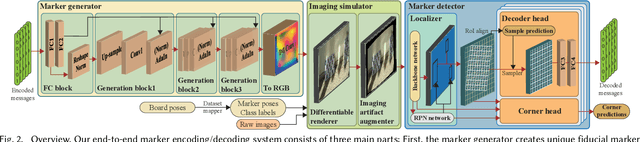

Fiducial markers have been broadly used to identify objects or embed messages that can be detected by a camera. Primarily, existing detection methods assume that markers are printed on ideally planar surfaces. Markers often fail to be recognized due to various imaging artifacts of optical/perspective distortion and motion blur. To overcome these limitations, we propose a novel deformable fiducial marker system that consists of three main parts: First, a fiducial marker generator creates a set of free-form color patterns to encode significantly large-scale information in unique visual codes. Second, a differentiable image simulator creates a training dataset of photorealistic scene images with the deformed markers, being rendered during optimization in a differentiable manner. The rendered images include realistic shading with specular reflection, optical distortion, defocus and motion blur, color alteration, imaging noise, and shape deformation of markers. Lastly, a trained marker detector seeks the regions of interest and recognizes multiple marker patterns simultaneously via inverse deformation transformation. The deformable marker creator and detector networks are jointly optimized via the differentiable photorealistic renderer in an end-to-end manner, allowing us to robustly recognize a wide range of deformable markers with high accuracy. Our deformable marker system is capable of decoding 36-bit messages successfully at ~29 fps with severe shape deformation. Results validate that our system significantly outperforms the traditional and data-driven marker methods. Our learning-based marker system opens up new interesting applications of fiducial markers, including cost-effective motion capture of the human body, active 3D scanning using our fiducial markers' array as structured light patterns, and robust augmented reality rendering of virtual objects on dynamic surfaces.
Benchmarking Deep Deblurring Algorithms: A Large-Scale Multi-Cause Dataset and A New Baseline Model
Dec 01, 2021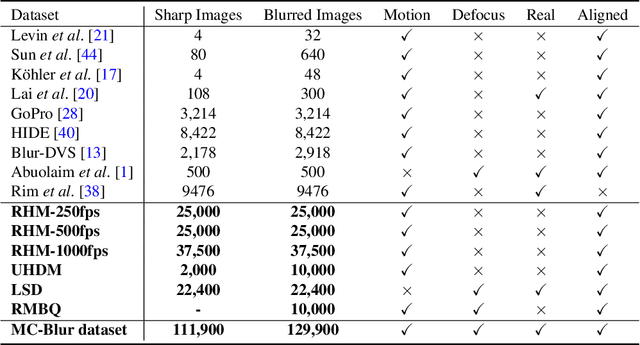
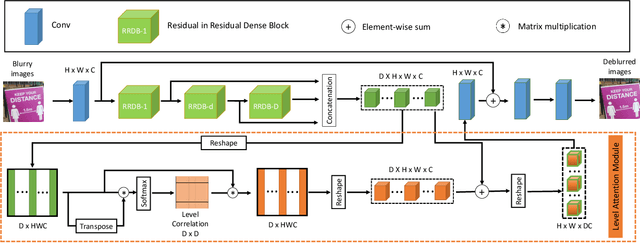

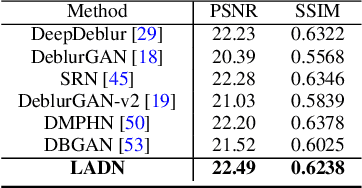
Blur artifacts can seriously degrade the visual quality of images, and numerous deblurring methods have been proposed for specific scenarios. However, in most real-world images, blur is caused by different factors, e.g., motion and defocus. In this paper, we address how different deblurring methods perform on general types of blur. For in-depth performance evaluation, we construct a new large-scale multi-cause image deblurring dataset called (MC-Blur) including real-world and synthesized blurry images with mixed factors of blurs. The images in the proposed MC-Blur dataset are collected using different techniques: convolving Ultra-High-Definition (UHD) sharp images with large kernels, averaging sharp images captured by a 1000 fps high-speed camera, adding defocus to images, and real-world blurred images captured by various camera models. These results provide a comprehensive overview of the advantages and limitations of current deblurring methods. Further, we propose a new baseline model, level-attention deblurring network, to adapt to multiple causes of blurs. By including different weights of attention to the different levels of features, the proposed network derives more powerful features with larger weights assigned to more important levels, thereby enhancing the feature representation. Extensive experimental results on the new dataset demonstrate the effectiveness of the proposed model for the multi-cause blur scenarios.
Deblur-NeRF: Neural Radiance Fields from Blurry Images
Nov 29, 2021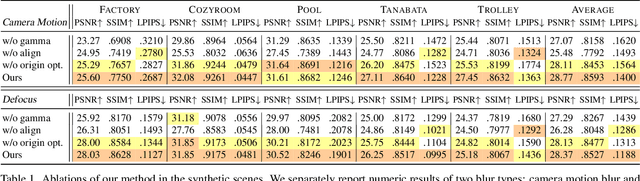
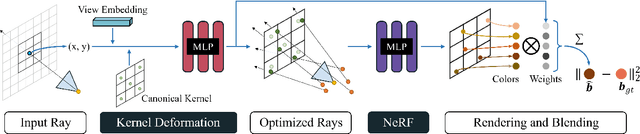
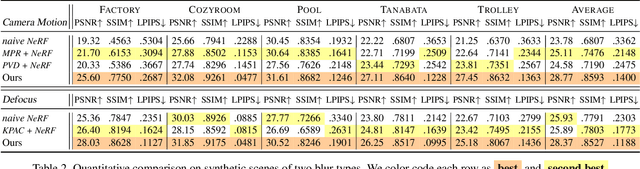
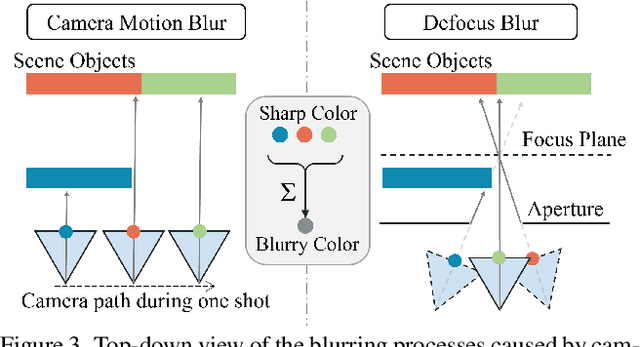
Neural Radiance Field (NeRF) has gained considerable attention recently for 3D scene reconstruction and novel view synthesis due to its remarkable synthesis quality. However, image blurriness caused by defocus or motion, which often occurs when capturing scenes in the wild, significantly degrades its reconstruction quality. To address this problem, We propose Deblur-NeRF, the first method that can recover a sharp NeRF from blurry input. We adopt an analysis-by-synthesis approach that reconstructs blurry views by simulating the blurring process, thus making NeRF robust to blurry inputs. The core of this simulation is a novel Deformable Sparse Kernel (DSK) module that models spatially-varying blur kernels by deforming a canonical sparse kernel at each spatial location. The ray origin of each kernel point is jointly optimized, inspired by the physical blurring process. This module is parameterized as an MLP that has the ability to be generalized to various blur types. Jointly optimizing the NeRF and the DSK module allows us to restore a sharp NeRF. We demonstrate that our method can be used on both camera motion blur and defocus blur: the two most common types of blur in real scenes. Evaluation results on both synthetic and real-world data show that our method outperforms several baselines. The synthetic and real datasets along with the source code will be made publicly available to facilitate future research.