 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJpeg Compression Artifact Reduction
Papers and Code
Double Deep Learning-based Event Data Coding and Classification
Jul 22, 2024Event cameras have the ability to capture asynchronous per-pixel brightness changes, called "events", offering advantages over traditional frame-based cameras for computer vision applications. Efficiently coding event data is critical for transmission and storage, given the significant volume of events. This paper proposes a novel double deep learning-based architecture for both event data coding and classification, using a point cloud-based representation for events. In this context, the conversions from events to point clouds and back to events are key steps in the proposed solution, and therefore its impact is evaluated in terms of compression and classification performance. Experimental results show that it is possible to achieve a classification performance of compressed events which is similar to one of the original events, even after applying a lossy point cloud codec, notably the recent learning-based JPEG Pleno Point Cloud Coding standard, with a clear rate reduction. Experimental results also demonstrate that events coded using JPEG PCC achieve better classification performance than those coded using the conventional lossy MPEG Geometry-based Point Cloud Coding standard. Furthermore, the adoption of learning-based coding offers high potential for performing computer vision tasks in the compressed domain, which allows skipping the decoding stage while mitigating the impact of coding artifacts.
Multi-Modality Deep Network for JPEG Artifacts Reduction
May 04, 2023In recent years, many convolutional neural network-based models are designed for JPEG artifacts reduction, and have achieved notable progress. However, few methods are suitable for extreme low-bitrate image compression artifacts reduction. The main challenge is that the highly compressed image loses too much information, resulting in reconstructing high-quality image difficultly. To address this issue, we propose a multimodal fusion learning method for text-guided JPEG artifacts reduction, in which the corresponding text description not only provides the potential prior information of the highly compressed image, but also serves as supplementary information to assist in image deblocking. We fuse image features and text semantic features from the global and local perspectives respectively, and design a contrastive loss built upon contrastive learning to produce visually pleasing results. Extensive experiments, including a user study, prove that our method can obtain better deblocking results compared to the state-of-the-art methods.
Accurate Image Restoration with Attention Retractable Transformer
Oct 04, 2022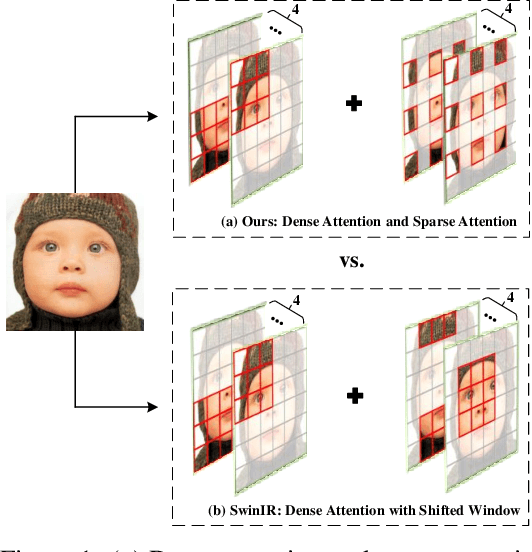

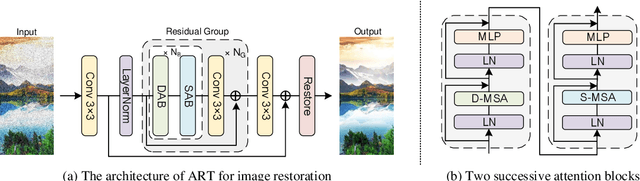

Recently, Transformer-based image restoration networks have achieved promising improvements over convolutional neural networks due to parameter-independent global interactions. To lower computational cost, existing works generally limit self-attention computation within non-overlapping windows. However, each group of tokens are always from a dense area of the image. This is considered as a dense attention strategy since the interactions of tokens are restrained in dense regions. Obviously, this strategy could result in restricted receptive fields. To address this issue, we propose Attention Retractable Transformer (ART) for image restoration, which presents both dense and sparse attention modules in the network. The sparse attention module allows tokens from sparse areas to interact and thus provides a wider receptive field. Furthermore, the alternating application of dense and sparse attention modules greatly enhances representation ability of Transformer while providing retractable attention on the input image.We conduct extensive experiments on image super-resolution, denoising, and JPEG compression artifact reduction tasks. Experimental results validate that our proposed ART outperforms state-of-the-art methods on various benchmark datasets both quantitatively and visually. We also provide code and models at the website https://github.com/gladzhang/ART.
JPEG Quantized Coefficient Recovery via DCT Domain Spatial-Frequential Transformer
Aug 17, 2023JPEG compression adopts the quantization of Discrete Cosine Transform (DCT) coefficients for effective bit-rate reduction, whilst the quantization could lead to a significant loss of important image details. Recovering compressed JPEG images in the frequency domain has attracted more and more attention recently, in addition to numerous restoration approaches developed in the pixel domain. However, the current DCT domain methods typically suffer from limited effectiveness in handling a wide range of compression quality factors, or fall short in recovering sparse quantized coefficients and the components across different colorspace. To address these challenges, we propose a DCT domain spatial-frequential Transformer, named as DCTransformer. Specifically, a dual-branch architecture is designed to capture both spatial and frequential correlations within the collocated DCT coefficients. Moreover, we incorporate the operation of quantization matrix embedding, which effectively allows our single model to handle a wide range of quality factors, and a luminance-chrominance alignment head that produces a unified feature map to align different-sized luminance and chrominance components. Our proposed DCTransformer outperforms the current state-of-the-art JPEG artifact removal techniques, as demonstrated by our extensive experiments.
Variational Deep Image Restoration
Jul 03, 2022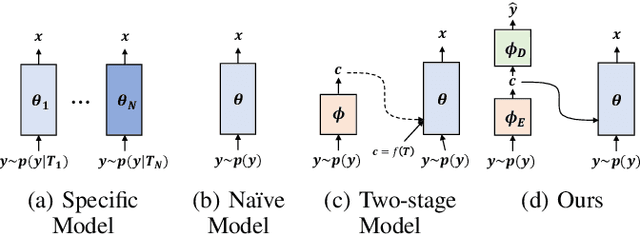
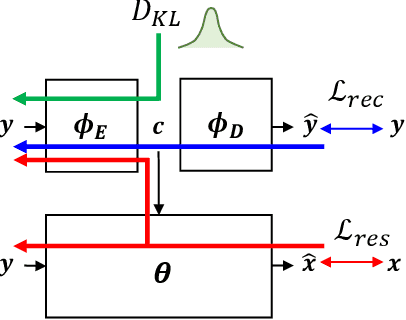
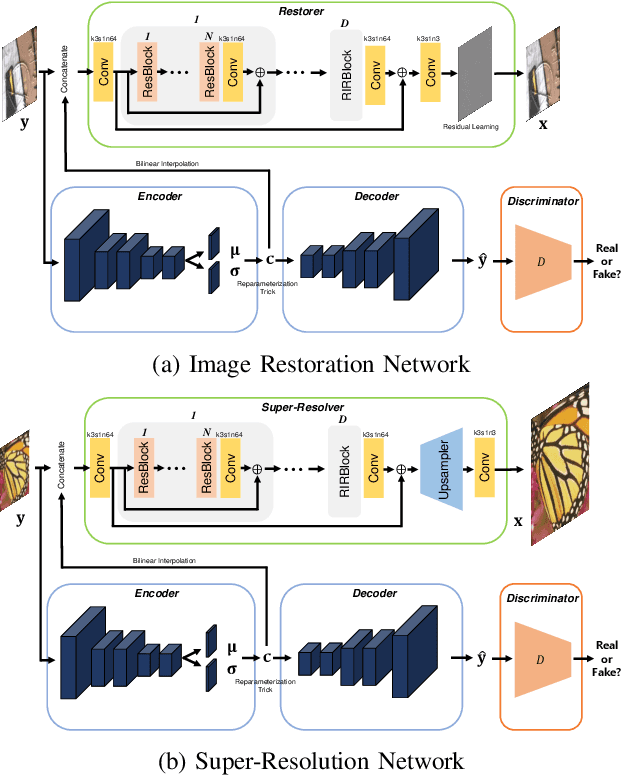

This paper presents a new variational inference framework for image restoration and a convolutional neural network (CNN) structure that can solve the restoration problems described by the proposed framework. Earlier CNN-based image restoration methods primarily focused on network architecture design or training strategy with non-blind scenarios where the degradation models are known or assumed. For a step closer to real-world applications, CNNs are also blindly trained with the whole dataset, including diverse degradations. However, the conditional distribution of a high-quality image given a diversely degraded one is too complicated to be learned by a single CNN. Therefore, there have also been some methods that provide additional prior information to train a CNN. Unlike previous approaches, we focus more on the objective of restoration based on the Bayesian perspective and how to reformulate the objective. Specifically, our method relaxes the original posterior inference problem to better manageable sub-problems and thus behaves like a divide-and-conquer scheme. As a result, the proposed framework boosts the performance of several restoration problems compared to the previous ones. Specifically, our method delivers state-of-the-art performance on Gaussian denoising, real-world noise reduction, blind image super-resolution, and JPEG compression artifacts reduction.
SwinIR: Image Restoration Using Swin Transformer
Aug 23, 2021

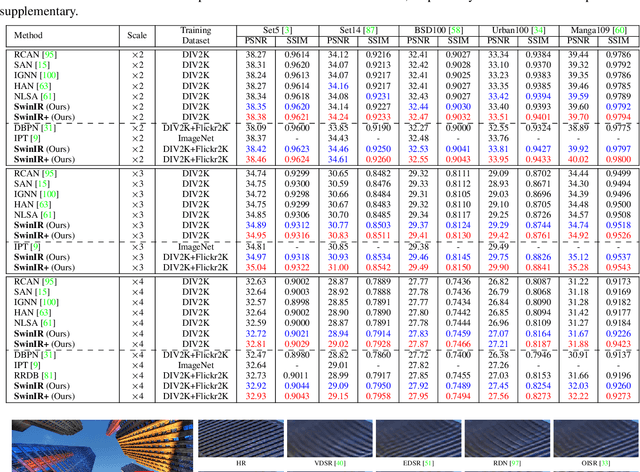
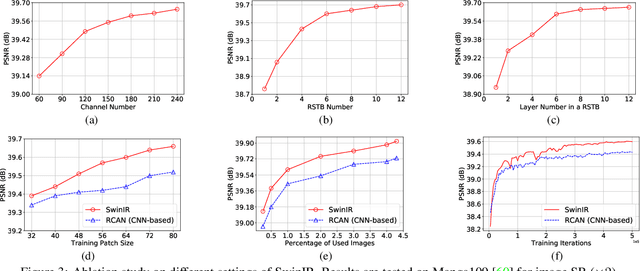
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by $\textbf{up to 0.14$\sim$0.45dB}$, while the total number of parameters can be reduced by $\textbf{up to 67%}$.
S-Net: A Scalable Convolutional Neural Network for JPEG Compression Artifact Reduction
Oct 18, 2018Recent studies have used deep residual convolutional neural networks (CNNs) for JPEG compression artifact reduction. This study proposes a scalable CNN called S-Net. Our approach effectively adjusts the network scale dynamically in a multitask system for real-time operation with little performance loss. It offers a simple and direct technique to evaluate the performance gains obtained with increasing network depth, and it is helpful for removing redundant network layers to maximize the network efficiency. We implement our architecture using the Keras framework with the TensorFlow backend on an NVIDIA K80 GPU server. We train our models on the DIV2K dataset and evaluate their performance on public benchmark datasets. To validate the generality and universality of the proposed method, we created and utilized a new dataset, called WIN143, for over-processed images evaluation. Experimental results indicate that our proposed approach outperforms other CNN-based methods and achieves state-of-the-art performance.
Quantization Guided JPEG Artifact Correction
Apr 17, 2020



The JPEG image compression algorithm is the most popular method of image compression because of its ability for large compression ratios. However, to achieve such high compression, information is lost. For aggressive quantization settings, this leads to a noticeable reduction in image quality. Artifact correction has been studied in the context of deep neural networks for some time, but the current state-of-the-art methods require a different model to be trained for each quality setting, greatly limiting their practical application. We solve this problem by creating a novel architecture which is parameterized by the JPEG files quantization matrix. This allows our single model to achieve state-of-the-art performance over models trained for specific quality settings.
Super-resolving Compressed Images via Parallel and Series Integration of Artifact Reduction and Resolution Enhancement
Mar 04, 2021



In this paper, we propose a novel compressed image super resolution (CISR) framework based on parallel and series integration of artifact removal and resolution enhancement. Based on maximum a posterior inference for estimating a clean low-resolution (LR) input image and a clean high resolution (HR) output image from down-sampled and compressed observations, we have designed a CISR architecture consisting of two deep neural network modules: the artifact reduction module (ARM) and resolution enhancement module (REM). ARM and REM work in parallel with both taking the compressed LR image as their inputs, while they also work in series with REM taking the output of ARM as one of its inputs and ARM taking the output of REM as its other input. A unique property of our CSIR system is that a single trained model is able to super-resolve LR images compressed by different methods to various qualities. This is achieved by exploiting deep neural net-works capacity for handling image degradations, and the parallel and series connections between ARM and REM to reduce the dependency on specific degradations. ARM and REM are trained simultaneously by the deep unfolding technique. Experiments are conducted on a mixture of JPEG and WebP compressed images without a priori knowledge of the compression type and com-pression factor. Visual and quantitative comparisons demonstrate the superiority of our method over state-of-the-art super resolu-tion methods.Code link: https://github.com/luohongming/CISR_PSI
JNCD-Based Perceptual Compression of RGB 4:4:4 Image Data
May 16, 2020



In contemporary lossy image coding applications, a desired aim is to decrease, as much as possible, bits per pixel without inducing perceptually conspicuous distortions in RGB image data. In this paper, we propose a novel color-based perceptual compression technique, named RGB-PAQ. RGB-PAQ is based on CIELAB Just Noticeable Color Difference (JNCD) and Human Visual System (HVS) spectral sensitivity. We utilize CIELAB JNCD and HVS spectral sensitivity modeling to separately adjust quantization levels at the Coding Block (CB) level. In essence, our method is designed to capitalize on the inability of the HVS to perceptually differentiate photons in very similar wavelength bands. In terms of application, the proposed technique can be used with RGB (4:4:4) image data of various bit depths and spatial resolutions including, for example, true color and deep color images in HD and Ultra HD resolutions. In the evaluations, we compare RGB-PAQ with a set of anchor methods; namely, HEVC, JPEG, JPEG 2000 and Google WebP. Compared with HEVC HM RExt, RGB-PAQ achieves up to 77.8% bits reductions. The subjective evaluations confirm that the compression artifacts induced by RGB-PAQ proved to be either imperceptible (MOS = 5) or near-imperceptible (MOS = 4) in the vast majority of cases.