 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation for Super-Resolution without Class Labels and Pre-trained Models
Sep 18, 2025Training deep neural networks has become increasingly demanding, requiring large datasets and significant computational resources, especially as model complexity advances. Data distillation methods, which aim to improve data efficiency, have emerged as promising solutions to this challenge. In the field of single image super-resolution (SISR), the reliance on large training datasets highlights the importance of these techniques. Recently, a generative adversarial network (GAN) inversion-based data distillation framework for SR was proposed, showing potential for better data utilization. However, the current method depends heavily on pre-trained SR networks and class-specific information, limiting its generalizability and applicability. To address these issues, we introduce a new data distillation approach for image SR that does not need class labels or pre-trained SR models. In particular, we first extract high-gradient patches and categorize images based on CLIP features, then fine-tune a diffusion model on the selected patches to learn their distribution and synthesize distilled training images. Experimental results show that our method achieves state-of-the-art performance while using significantly less training data and requiring less computational time. Specifically, when we train a baseline Transformer model for SR with only 0.68\% of the original dataset, the performance drop is just 0.3 dB. In this case, diffusion model fine-tuning takes 4 hours, and SR model training completes within 1 hour, much shorter than the 11-hour training time with the full dataset.
Efficient Attention-Sharing Information Distillation Transformer for Lightweight Single Image Super-Resolution
Jan 27, 2025Transformer-based Super-Resolution (SR) methods have demonstrated superior performance compared to convolutional neural network (CNN)-based SR approaches due to their capability to capture long-range dependencies. However, their high computational complexity necessitates the development of lightweight approaches for practical use. To address this challenge, we propose the Attention-Sharing Information Distillation (ASID) network, a lightweight SR network that integrates attention-sharing and an information distillation structure specifically designed for Transformer-based SR methods. We modify the information distillation scheme, originally designed for efficient CNN operations, to reduce the computational load of stacked self-attention layers, effectively addressing the efficiency bottleneck. Additionally, we introduce attention-sharing across blocks to further minimize the computational cost of self-attention operations. By combining these strategies, ASID achieves competitive performance with existing SR methods while requiring only around 300K parameters - significantly fewer than existing CNN-based and Transformer-based SR models. Furthermore, ASID outperforms state-of-the-art SR methods when the number of parameters is matched, demonstrating its efficiency and effectiveness. The code and supplementary material are available on the project page.
Training Patch Analysis and Mining Skills for Image Restoration Deep Neural Networks
Jul 03, 2022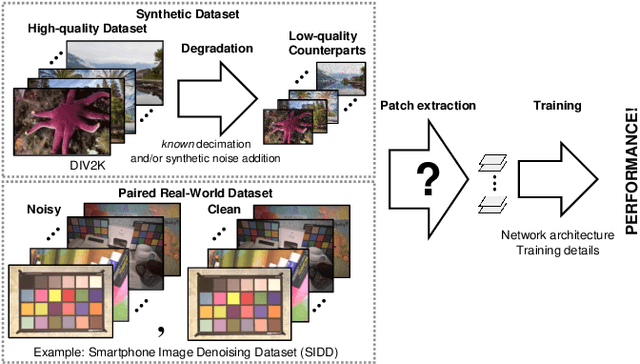


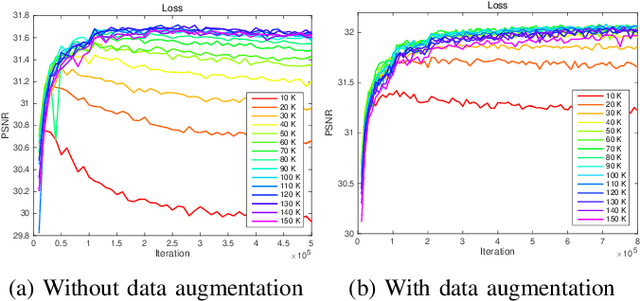
There have been numerous image restoration methods based on deep convolutional neural networks (CNNs). However, most of the literature on this topic focused on the network architecture and loss functions, while less detailed on the training methods. Hence, some of the works are not easily reproducible because it is required to know the hidden training skills to obtain the same results. To be specific with the training dataset, few works discussed how to prepare and order the training image patches. Moreover, it requires a high cost to capture new datasets to train a restoration network for the real-world scene. Hence, we believe it is necessary to study the preparation and selection of training data. In this regard, we present an analysis of the training patches and explore the consequences of different patch extraction methods. Eventually, we propose a guideline for the patch extraction from given training images.
Variational Deep Image Restoration
Jul 03, 2022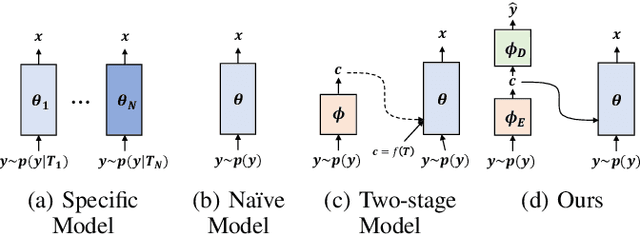
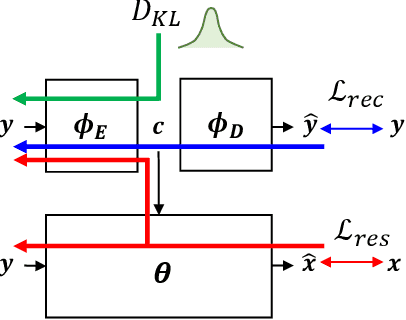
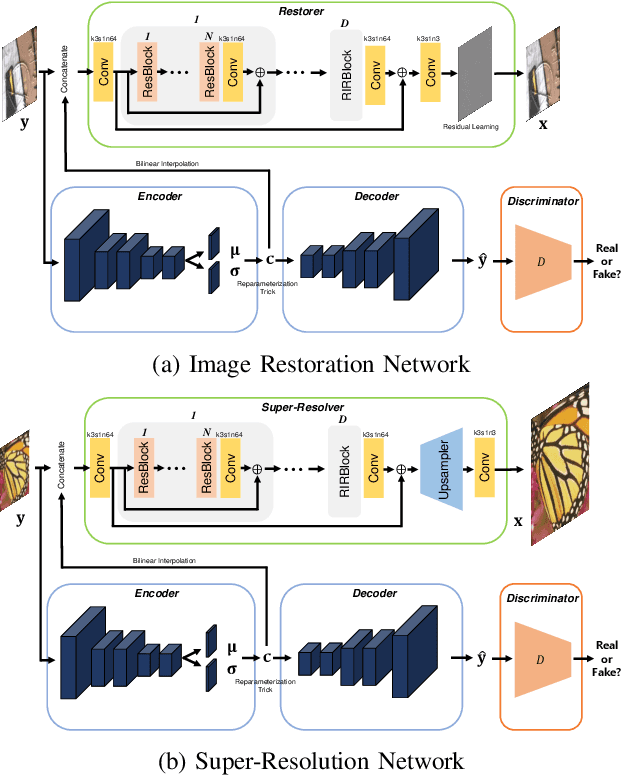

This paper presents a new variational inference framework for image restoration and a convolutional neural network (CNN) structure that can solve the restoration problems described by the proposed framework. Earlier CNN-based image restoration methods primarily focused on network architecture design or training strategy with non-blind scenarios where the degradation models are known or assumed. For a step closer to real-world applications, CNNs are also blindly trained with the whole dataset, including diverse degradations. However, the conditional distribution of a high-quality image given a diversely degraded one is too complicated to be learned by a single CNN. Therefore, there have also been some methods that provide additional prior information to train a CNN. Unlike previous approaches, we focus more on the objective of restoration based on the Bayesian perspective and how to reformulate the objective. Specifically, our method relaxes the original posterior inference problem to better manageable sub-problems and thus behaves like a divide-and-conquer scheme. As a result, the proposed framework boosts the performance of several restoration problems compared to the previous ones. Specifically, our method delivers state-of-the-art performance on Gaussian denoising, real-world noise reduction, blind image super-resolution, and JPEG compression artifacts reduction.
A Dynamic Residual Self-Attention Network for Lightweight Single Image Super-Resolution
Dec 08, 2021



Deep learning methods have shown outstanding performance in many applications, including single-image super-resolution (SISR). With residual connection architecture, deeply stacked convolutional neural networks provide a substantial performance boost for SISR, but their huge parameters and computational loads are impractical for real-world applications. Thus, designing lightweight models with acceptable performance is one of the major tasks in current SISR research. The objective of lightweight network design is to balance a computational load and reconstruction performance. Most of the previous methods have manually designed complex and predefined fixed structures, which generally required a large number of experiments and lacked flexibility in the diversity of input image statistics. In this paper, we propose a dynamic residual self-attention network (DRSAN) for lightweight SISR, while focusing on the automated design of residual connections between building blocks. The proposed DRSAN has dynamic residual connections based on dynamic residual attention (DRA), which adaptively changes its structure according to input statistics. Specifically, we propose a dynamic residual module that explicitly models the DRA by finding the interrelation between residual paths and input image statistics, as well as assigning proper weights to each residual path. We also propose a residual self-attention (RSA) module to further boost the performance, which produces 3-dimensional attention maps without additional parameters by cooperating with residual structures. The proposed dynamic scheme, exploiting the combination of DRA and RSA, shows an efficient trade-off between computational complexity and network performance. Experimental results show that the DRSAN performs better than or comparable to existing state-of-the-art lightweight models for SISR.
Variational Deep Image Denoising
Apr 02, 2021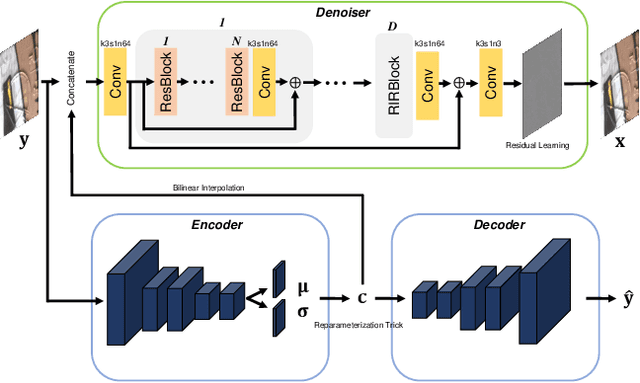


Convolutional neural networks (CNNs) have shown outstanding performance on image denoising with the help of large-scale datasets. Earlier methods naively trained a single CNN with many pairs of clean-noisy images. However, the conditional distribution of the clean image given a noisy one is too complicated and diverse, so that a single CNN cannot well learn such distributions. Therefore, there have also been some methods that exploit additional noise level parameters or train a separate CNN for a specific noise level parameter. These methods separate the original problem into easier sub-problems and thus have shown improved performance than the naively trained CNN. In this step, we raise two questions. The first one is whether it is an optimal approach to relate the conditional distribution only to noise level parameters. The second is what if we do not have noise level information, such as in a real-world scenario. To answer the questions and provide a better solution, we propose a novel Bayesian framework based on the variational approximation of objective functions. This enables us to separate the complicated target distribution into simpler sub-distributions. Eventually, the denoising CNN can conquer noise from each sub-distribution, which is generally an easier problem than the original. Experiments show that the proposed method provides remarkable performance on additive white Gaussian noise (AWGN) and real-noise denoising while requiring fewer parameters than recent state-of-the-art denoisers.
Deep Universal Blind Image Denoising
Jan 18, 2021



Image denoising is an essential part of many image processing and computer vision tasks due to inevitable noise corruption during image acquisition. Traditionally, many researchers have investigated image priors for the denoising, within the Bayesian perspective based on image properties and statistics. Recently, deep convolutional neural networks (CNNs) have shown great success in image denoising by incorporating large-scale synthetic datasets. However, they both have pros and cons. While the deep CNNs are powerful for removing the noise with known statistics, they tend to lack flexibility and practicality for the blind and real-world noise. Moreover, they cannot easily employ explicit priors. On the other hand, traditional non-learning methods can involve explicit image priors, but they require considerable computation time and cannot exploit large-scale external datasets. In this paper, we present a CNN-based method that leverages the advantages of both methods based on the Bayesian perspective. Concretely, we divide the blind image denoising problem into sub-problems and conquer each inference problem separately. As the CNN is a powerful tool for inference, our method is rooted in CNNs and propose a novel design of network for efficient inference. With our proposed method, we can successfully remove blind and real-world noise, with a moderate number of parameters of universal CNN.
Transfer Learning from Synthetic to Real-Noise Denoising with Adaptive Instance Normalization
Mar 16, 2020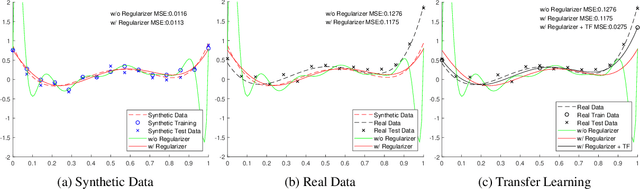
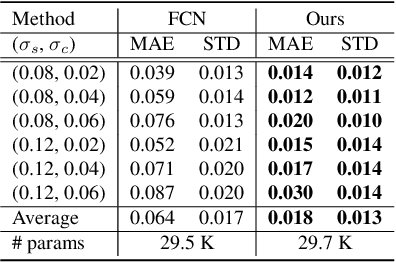
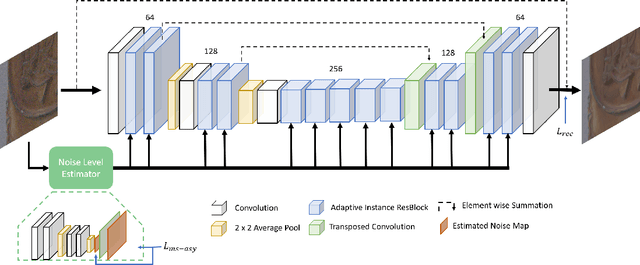
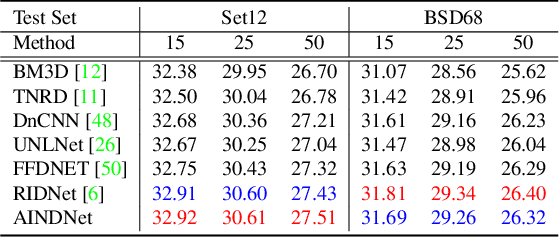
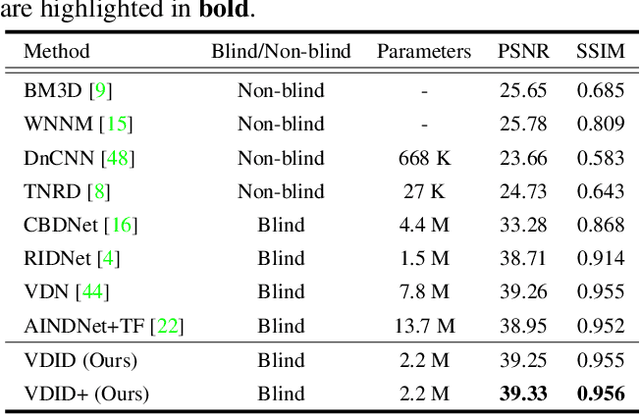
Real-noise denoising is a challenging task because the statistics of real-noise do not follow the normal distribution, and they are also spatially and temporally changing. In order to cope with various and complex real-noise, we propose a well-generalized denoising architecture and a transfer learning scheme. Specifically, we adopt an adaptive instance normalization to build a denoiser, which can regularize the feature map and prevent the network from overfitting to the training set. We also introduce a transfer learning scheme that transfers knowledge learned from synthetic-noise data to the real-noise denoiser. From the proposed transfer learning, the synthetic-noise denoiser can learn general features from various synthetic-noise data, and the real-noise denoiser can learn the real-noise characteristics from real data. From the experiments, we find that the proposed denoising method has great generalization ability, such that our network trained with synthetic-noise achieves the best performance for Darmstadt Noise Dataset (DND) among the methods from published papers. We can also see that the proposed transfer learning scheme robustly works for real-noise images through the learning with a very small number of labeled data.
Meta-Transfer Learning for Zero-Shot Super-Resolution
Feb 27, 2020

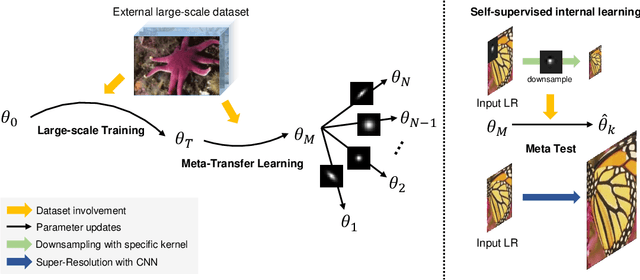
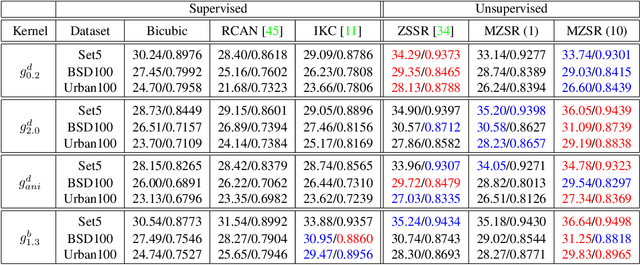
Convolutional neural networks (CNNs) have shown dramatic improvements in single image super-resolution (SISR) by using large-scale external samples. Despite their remarkable performance based on the external dataset, they cannot exploit internal information within a specific image. Another problem is that they are applicable only to the specific condition of data that they are supervised. For instance, the low-resolution (LR) image should be a "bicubic" downsampled noise-free image from a high-resolution (HR) one. To address both issues, zero-shot super-resolution (ZSSR) has been proposed for flexible internal learning. However, they require thousands of gradient updates, i.e., long inference time. In this paper, we present Meta-Transfer Learning for Zero-Shot Super-Resolution (MZSR), which leverages ZSSR. Precisely, it is based on finding a generic initial parameter that is suitable for internal learning. Thus, we can exploit both external and internal information, where one single gradient update can yield quite considerable results. (See Figure 1). With our method, the network can quickly adapt to a given image condition. In this respect, our method can be applied to a large spectrum of image conditions within a fast adaptation process.
Natural and Realistic Single Image Super-Resolution with Explicit Natural Manifold Discrimination
Nov 09, 2019
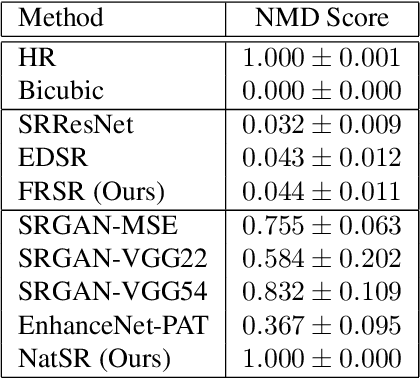
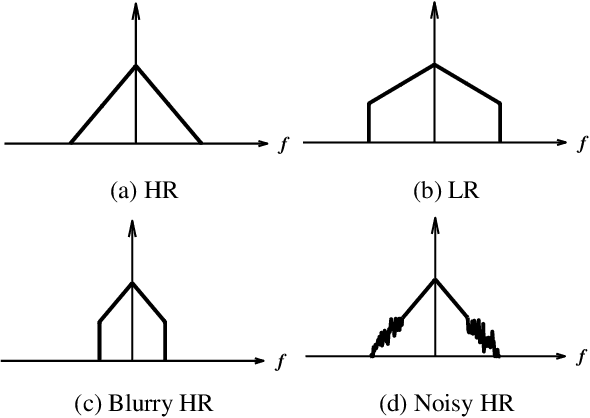
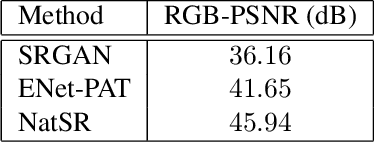
Recently, many convolutional neural networks for single image super-resolution (SISR) have been proposed, which focus on reconstructing the high-resolution images in terms of objective distortion measures. However, the networks trained with objective loss functions generally fail to reconstruct the realistic fine textures and details that are essential for better perceptual quality. Recovering the realistic details remains a challenging problem, and only a few works have been proposed which aim at increasing the perceptual quality by generating enhanced textures. However, the generated fake details often make undesirable artifacts and the overall image looks somewhat unnatural. Therefore, in this paper, we present a new approach to reconstructing realistic super-resolved images with high perceptual quality, while maintaining the naturalness of the result. In particular, we focus on the domain prior properties of SISR problem. Specifically, we define the naturalness prior in the low-level domain and constrain the output image in the natural manifold, which eventually generates more natural and realistic images. Our results show better naturalness compared to the recent super-resolution algorithms including perception-oriented ones.