 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordArt Designer API: User-Driven Artistic Typography Synthesis with Large Language Models on ModelScope
Jan 12, 2024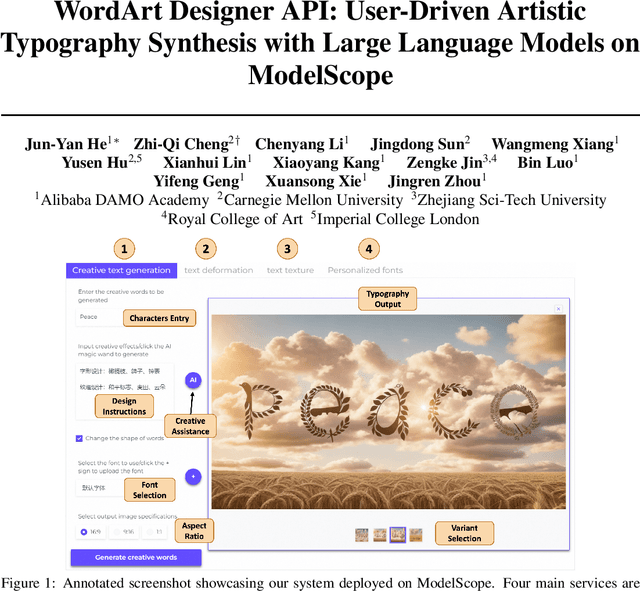
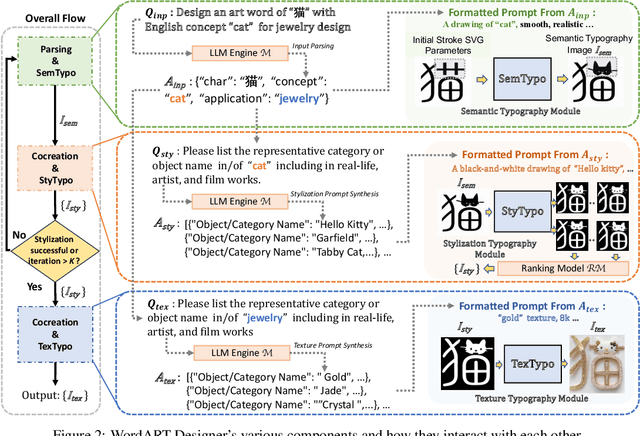


This paper introduces the WordArt Designer API, a novel framework for user-driven artistic typography synthesis utilizing Large Language Models (LLMs) on ModelScope. We address the challenge of simplifying artistic typography for non-professionals by offering a dynamic, adaptive, and computationally efficient alternative to traditional rigid templates. Our approach leverages the power of LLMs to understand and interpret user input, facilitating a more intuitive design process. We demonstrate through various case studies how users can articulate their aesthetic preferences and functional requirements, which the system then translates into unique and creative typographic designs. Our evaluations indicate significant improvements in user satisfaction, design flexibility, and creative expression over existing systems. The WordArt Designer API not only democratizes the art of typography but also opens up new possibilities for personalized digital communication and design.
Unifying Graph Contrastive Learning via Graph Message Augmentation
Jan 08, 2024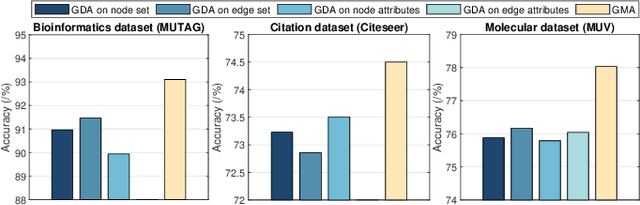
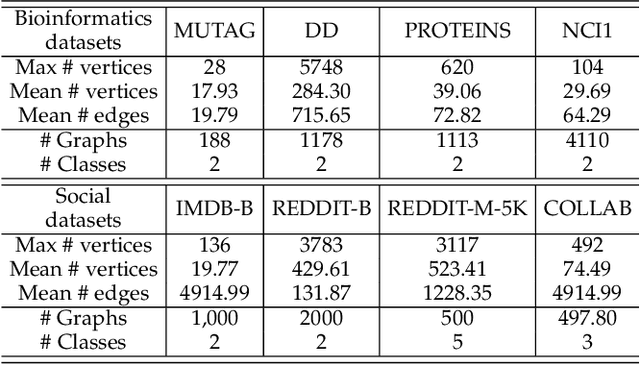
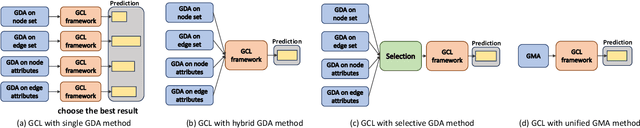
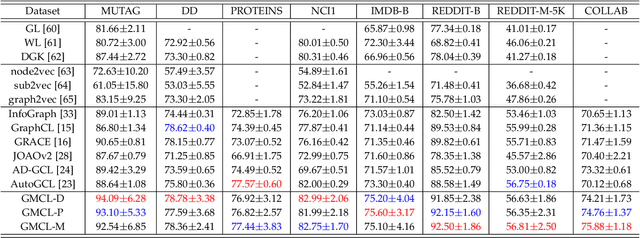
Graph contrastive learning is usually performed by first conducting Graph Data Augmentation (GDA) and then employing a contrastive learning pipeline to train GNNs. As we know that GDA is an important issue for graph contrastive learning. Various GDAs have been developed recently which mainly involve dropping or perturbing edges, nodes, node attributes and edge attributes. However, to our knowledge, it still lacks a universal and effective augmentor that is suitable for different types of graph data. To address this issue, in this paper, we first introduce the graph message representation of graph data. Based on it, we then propose a novel Graph Message Augmentation (GMA), a universal scheme for reformulating many existing GDAs. The proposed unified GMA not only gives a new perspective to understand many existing GDAs but also provides a universal and more effective graph data augmentation for graph self-supervised learning tasks. Moreover, GMA introduces an easy way to implement the mixup augmentor which is natural for images but usually challengeable for graphs. Based on the proposed GMA, we then propose a unified graph contrastive learning, termed Graph Message Contrastive Learning (GMCL), that employs attribution-guided universal GMA for graph contrastive learning. Experiments on many graph learning tasks demonstrate the effectiveness and benefits of the proposed GMA and GMCL approaches.
Transformer RGBT Tracking with Spatio-Temporal Multimodal Tokens
Jan 03, 2024



Many RGBT tracking researches primarily focus on modal fusion design, while overlooking the effective handling of target appearance changes. While some approaches have introduced historical frames or fuse and replace initial templates to incorporate temporal information, they have the risk of disrupting the original target appearance and accumulating errors over time. To alleviate these limitations, we propose a novel Transformer RGBT tracking approach, which mixes spatio-temporal multimodal tokens from the static multimodal templates and multimodal search regions in Transformer to handle target appearance changes, for robust RGBT tracking. We introduce independent dynamic template tokens to interact with the search region, embedding temporal information to address appearance changes, while also retaining the involvement of the initial static template tokens in the joint feature extraction process to ensure the preservation of the original reliable target appearance information that prevent deviations from the target appearance caused by traditional temporal updates. We also use attention mechanisms to enhance the target features of multimodal template tokens by incorporating supplementary modal cues, and make the multimodal search region tokens interact with multimodal dynamic template tokens via attention mechanisms, which facilitates the conveyance of multimodal-enhanced target change information. Our module is inserted into the transformer backbone network and inherits joint feature extraction, search-template matching, and cross-modal interaction. Extensive experiments on three RGBT benchmark datasets show that the proposed approach maintains competitive performance compared to other state-of-the-art tracking algorithms while running at 39.1 FPS.
Tracking with Human-Intent Reasoning
Dec 29, 2023Advances in perception modeling have significantly improved the performance of object tracking. However, the current methods for specifying the target object in the initial frame are either by 1) using a box or mask template, or by 2) providing an explicit language description. These manners are cumbersome and do not allow the tracker to have self-reasoning ability. Therefore, this work proposes a new tracking task -- Instruction Tracking, which involves providing implicit tracking instructions that require the trackers to perform tracking automatically in video frames. To achieve this, we investigate the integration of knowledge and reasoning capabilities from a Large Vision-Language Model (LVLM) for object tracking. Specifically, we propose a tracker called TrackGPT, which is capable of performing complex reasoning-based tracking. TrackGPT first uses LVLM to understand tracking instructions and condense the cues of what target to track into referring embeddings. The perception component then generates the tracking results based on the embeddings. To evaluate the performance of TrackGPT, we construct an instruction tracking benchmark called InsTrack, which contains over one thousand instruction-video pairs for instruction tuning and evaluation. Experiments show that TrackGPT achieves competitive performance on referring video object segmentation benchmarks, such as getting a new state-of the-art performance of 66.5 $\mathcal{J}\&\mathcal{F}$ on Refer-DAVIS. It also demonstrates a superior performance of instruction tracking under new evaluation protocols. The code and models are available at \href{https://github.com/jiawen-zhu/TrackGPT}{https://github.com/jiawen-zhu/TrackGPT}.
Nighttime Person Re-Identification via Collaborative Enhancement Network with Multi-domain Learning
Dec 25, 2023



Prevalent nighttime ReID methods typically combine relighting networks and ReID networks in a sequential manner, which not only restricts the ReID performance by the quality of relighting images, but also neglects the effective collaborative modeling between image relighting and person ReID tasks. To handle these problems, we propose a novel Collaborative Enhancement Network called CENet, which performs the multilevel feature interactions in a parallel framework, for nighttime person ReID. In particular, CENet is a parallel Transformer network, in which the designed parallel structure can avoid the impact of the quality of relighting images on ReID performance. To perform effective collaborative modeling between image relighting and person ReID tasks, we integrate the multilevel feature interactions in CENet. Specifically, we share the Transformer encoder to build the low-level feature interaction, and then perform the feature distillation to transfer the high-level features from image relighting to ReID. In addition, the sizes of existing real-world nighttime person ReID datasets are small, and large-scale synthetic ones exhibit substantial domain gaps with real-world data. To leverage both small-scale real-world and large-scale synthetic training data, we develop a multi-domain learning algorithm, which alternately utilizes both kinds of data to reduce the inter-domain difference in the training of CENet. Extensive experiments on two real nighttime datasets, \textit{Night600} and \textit{RGBNT201$_{rgb}$}, and a synthetic nighttime ReID dataset are conducted to validate the effectiveness of CENet. We will release the code and synthetic dataset.
Modality-missing RGBT Tracking via Invertible Prompt Learning and A High-quality Data Simulation Method
Dec 25, 2023



Current RGBT tracking researches mainly focus on the modality-complete scenarios, overlooking the modality-missing challenge in real-world scenes. In this work, we comprehensively investigate the impact of modality-missing challenge in RGBT tracking and propose a novel invertible prompt learning approach, which integrates the content-preserving prompts into a well-trained tracking model to adapt to various modality-missing scenarios, for modality-missing RGBT tracking. In particular, given one modality-missing scenario, we propose to utilize the available modality to generate the prompt of the missing modality to adapt to RGBT tracking model. However, the cross-modality gap between available and missing modalities usually causes semantic distortion and information loss in prompt generation. To handle this issue, we propose the invertible prompt learning scheme by incorporating the full reconstruction of the input available modality from the prompt in prompt generation model. Considering that there lacks a modality-missing RGBT tracking dataset and many modality-missing scenarios are difficult to capture, we design a high-quality data simulation method based on hierarchical combination schemes to generate real-world modality-missing data. Extensive experiments on three modality-missing datasets show that our method achieves significant performance improvements compared with state-of-the-art methods. We will release the code and simulation dataset.
A Comprehensive Evaluation of Parameter-Efficient Fine-Tuning on Software Engineering Tasks
Dec 25, 2023Pre-trained models (PTMs) have achieved great success in various Software Engineering (SE) downstream tasks following the ``pre-train then fine-tune'' paradigm. As fully fine-tuning all parameters of PTMs can be computationally expensive, a widely used solution is parameter-efficient fine-tuning (PEFT), which freezes PTMs while introducing extra parameters. Though work has been done to test PEFT methods in the SE field, a comprehensive evaluation is still lacking. This paper aims to fill in this gap by evaluating the effectiveness of five PEFT methods on eight PTMs and four SE downstream tasks. For different tasks and PEFT methods, we seek answers to the following research questions: 1) Is it more effective to use PTMs trained specifically on source code, or is it sufficient to use PTMs trained on natural language text? 2) What is the impact of varying model sizes? 3) How does the model architecture affect the performance? Besides effectiveness, we also discuss the efficiency of PEFT methods, concerning the costs of required training time and GPU resource consumption. We hope that our findings can provide a deeper understanding of PEFT methods on various PTMs and SE downstream tasks. All the codes and data are available at \url{https://github.com/zwtnju/PEFT.git}.
Semantic-Aware Frame-Event Fusion based Pattern Recognition via Large Vision-Language Models
Nov 30, 2023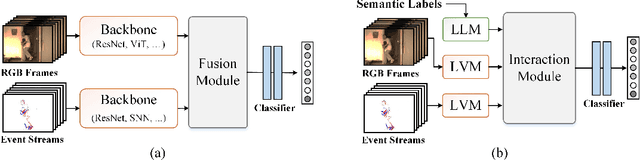

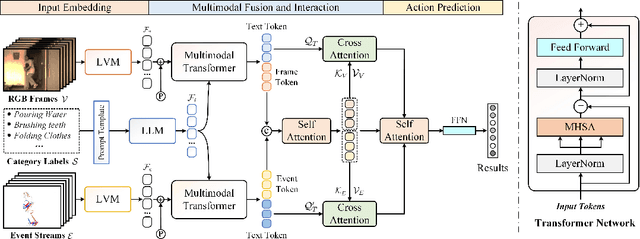
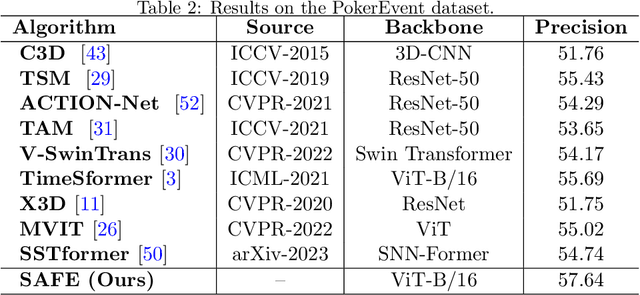
Pattern recognition through the fusion of RGB frames and Event streams has emerged as a novel research area in recent years. Current methods typically employ backbone networks to individually extract the features of RGB frames and event streams, and subsequently fuse these features for pattern recognition. However, we posit that these methods may suffer from key issues like sematic gaps and small-scale backbone networks. In this study, we introduce a novel pattern recognition framework that consolidates the semantic labels, RGB frames, and event streams, leveraging pre-trained large-scale vision-language models. Specifically, given the input RGB frames, event streams, and all the predefined semantic labels, we employ a pre-trained large-scale vision model (CLIP vision encoder) to extract the RGB and event features. To handle the semantic labels, we initially convert them into language descriptions through prompt engineering, and then obtain the semantic features using the pre-trained large-scale language model (CLIP text encoder). Subsequently, we integrate the RGB/Event features and semantic features using multimodal Transformer networks. The resulting frame and event tokens are further amplified using self-attention layers. Concurrently, we propose to enhance the interactions between text tokens and RGB/Event tokens via cross-attention. Finally, we consolidate all three modalities using self-attention and feed-forward layers for recognition. Comprehensive experiments on the HARDVS and PokerEvent datasets fully substantiate the efficacy of our proposed SAFE model. The source code will be made available at https://github.com/Event-AHU/SAFE_LargeVLM.
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Nov 29, 2023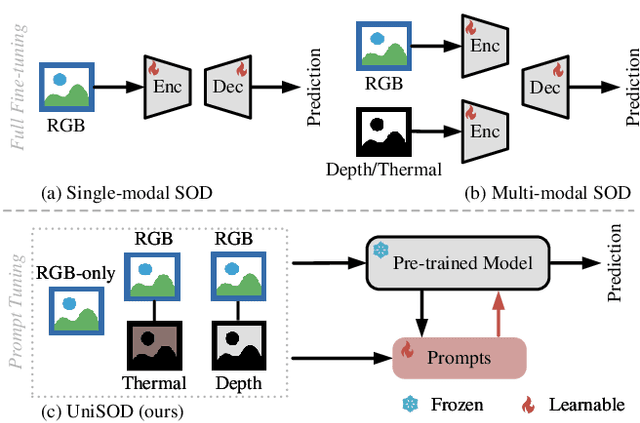
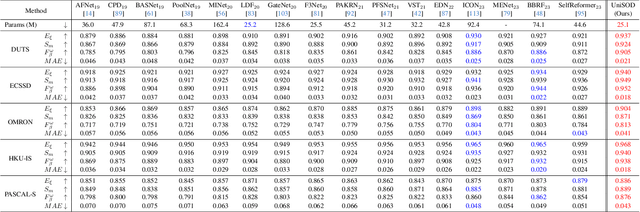
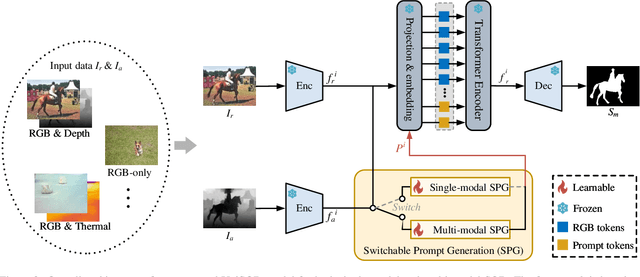
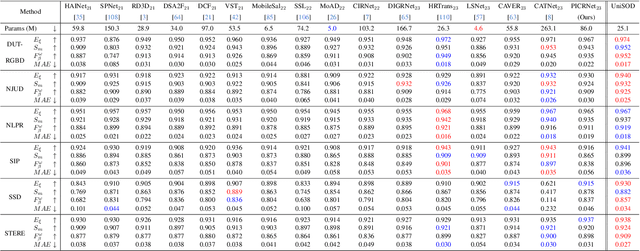
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we make the first attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which performs structural switching solely relied on single-modal and multi-modal inputs. UniSOD achieves consistent performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.
Robust Transductive Few-shot Learning via Joint Message Passing and Prototype-based Soft-label Propagation
Nov 28, 2023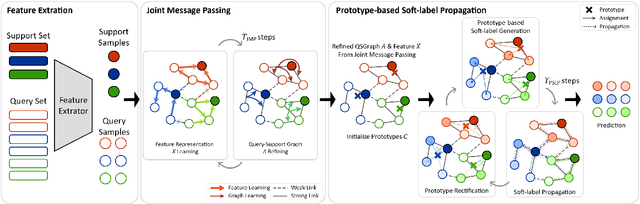
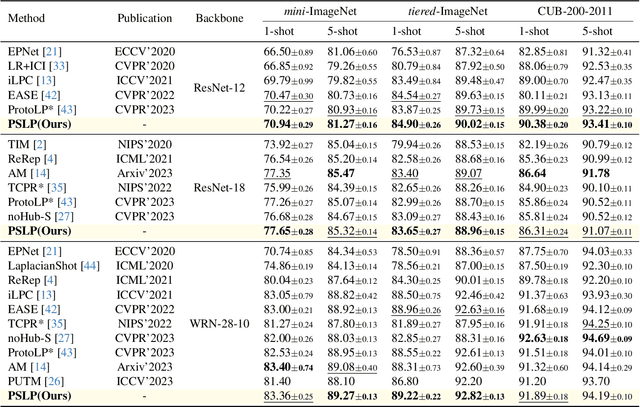
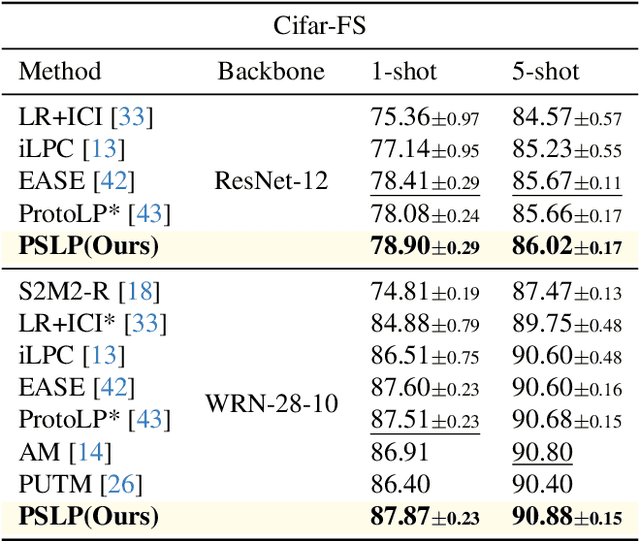
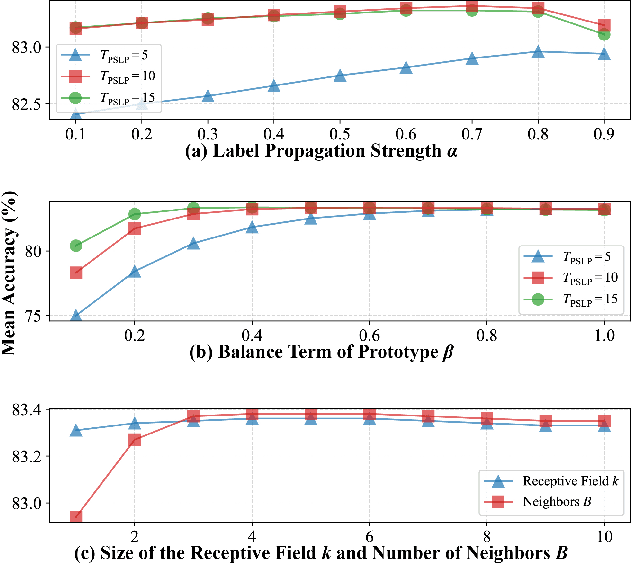
Few-shot learning (FSL) aims to develop a learning model with the ability to generalize to new classes using a few support samples. For transductive FSL tasks, prototype learning and label propagation methods are commonly employed. Prototype methods generally first learn the representative prototypes from the support set and then determine the labels of queries based on the metric between query samples and prototypes. Label propagation methods try to propagate the labels of support samples on the constructed graph encoding the relationships between both support and query samples. This paper aims to integrate these two principles together and develop an efficient and robust transductive FSL approach, termed Prototype-based Soft-label Propagation (PSLP). Specifically, we first estimate the soft-label presentation for each query sample by leveraging prototypes. Then, we conduct soft-label propagation on our learned query-support graph. Both steps are conducted progressively to boost their respective performance. Moreover, to learn effective prototypes for soft-label estimation as well as the desirable query-support graph for soft-label propagation, we design a new joint message passing scheme to learn sample presentation and relational graph jointly. Our PSLP method is parameter-free and can be implemented very efficiently. On four popular datasets, our method achieves competitive results on both balanced and imbalanced settings compared to the state-of-the-art methods. The code will be released upon acceptance.