 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLamb Optimizer
Papers and Code
Exploring Landscapes for Better Minima along Valleys
Oct 31, 2025Finding lower and better-generalizing minima is crucial for deep learning. However, most existing optimizers stop searching the parameter space once they reach a local minimum. Given the complex geometric properties of the loss landscape, it is difficult to guarantee that such a point is the lowest or provides the best generalization. To address this, we propose an adaptor "E" for gradient-based optimizers. The adapted optimizer tends to continue exploring along landscape valleys (areas with low and nearly identical losses) in order to search for potentially better local minima even after reaching a local minimum. This approach increases the likelihood of finding a lower and flatter local minimum, which is often associated with better generalization. We also provide a proof of convergence for the adapted optimizers in both convex and non-convex scenarios for completeness. Finally, we demonstrate their effectiveness in an important but notoriously difficult training scenario, large-batch training, where Lamb is the benchmark optimizer. Our testing results show that the adapted Lamb, ALTO, increases the test accuracy (generalization) of the current state-of-the-art optimizer by an average of 2.5% across a variety of large-batch training tasks. This work potentially opens a new research direction in the design of optimization algorithms.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024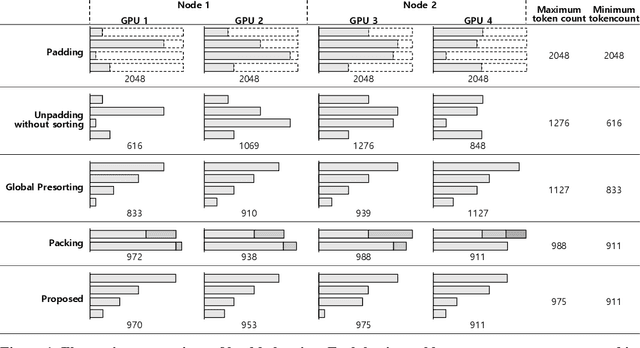
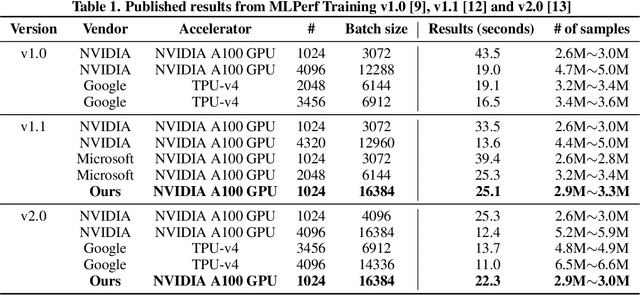
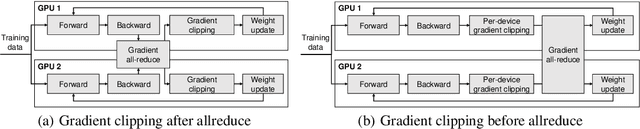
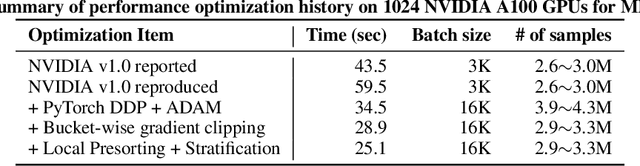
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.
Revisiting LARS for Large Batch Training Generalization of Neural Networks
Sep 25, 2023



LARS and LAMB have emerged as prominent techniques in Large Batch Learning (LBL), ensuring the stability of AI training. One of the primary challenges in LBL is convergence stability, where the AI agent usually gets trapped into the sharp minimizer. Addressing this challenge, a relatively recent technique, known as warm-up, has been employed. However, warm-up lacks a strong theoretical foundation, leaving the door open for further exploration of more efficacious algorithms. In light of this situation, we conduct empirical experiments to analyze the behaviors of the two most popular optimizers in the LARS family: LARS and LAMB, with and without a warm-up strategy. Our analyses give us a comprehension of the novel LARS, LAMB, and the necessity of a warm-up technique in LBL. Building upon these insights, we propose a novel algorithm called Time Varying LARS (TVLARS), which facilitates robust training in the initial phase without the need for warm-up. Experimental evaluation demonstrates that TVLARS achieves competitive results with LARS and LAMB when warm-up is utilized while surpassing their performance without the warm-up technique.
MKOR: Momentum-Enabled Kronecker-Factor-Based Optimizer Using Rank-1 Updates
Jun 02, 2023



This work proposes a Momentum-Enabled Kronecker-Factor-Based Optimizer Using Rank-1 updates, called MKOR, that improves the training time and convergence properties of deep neural networks (DNNs). Second-order techniques, while enjoying higher convergence rates vs first-order counterparts, have cubic complexity with respect to either the model size and/or the training batch size. Hence they exhibit poor scalability and performance in transformer models, e.g. large language models (LLMs), because the batch sizes in these models scale by the attention mechanism sequence length, leading to large model size and batch sizes. MKOR's complexity is quadratic with respect to the model size, alleviating the computation bottlenecks in second-order methods. Because of their high computation complexity, state-of-the-art implementations of second-order methods can only afford to update the second order information infrequently, and thus do not fully exploit the promise of better convergence from these updates. By reducing the communication complexity of the second-order updates as well as achieving a linear communication complexity, MKOR increases the frequency of second order updates. We also propose a hybrid version of MKOR (called MKOR-H) that mid-training falls backs to a first order optimizer if the second order updates no longer accelerate convergence. Our experiments show that MKOR outperforms state -of-the-art first order methods, e.g. the LAMB optimizer, and best implementations of second-order methods, i.e. KAISA/KFAC, up to 2.57x and 1.85x respectively on BERT-Large-Uncased on 64 GPUs.
CAME: Confidence-guided Adaptive Memory Efficient Optimization
Jul 05, 2023



Adaptive gradient methods, such as Adam and LAMB, have demonstrated excellent performance in the training of large language models. Nevertheless, the need for adaptivity requires maintaining second-moment estimates of the per-parameter gradients, which entails a high cost of extra memory overheads. To solve this problem, several memory-efficient optimizers (e.g., Adafactor) have been proposed to obtain a drastic reduction in auxiliary memory usage, but with a performance penalty. In this paper, we first study a confidence-guided strategy to reduce the instability of existing memory efficient optimizers. Based on this strategy, we propose CAME to simultaneously achieve two goals: fast convergence as in traditional adaptive methods, and low memory usage as in memory-efficient methods. Extensive experiments demonstrate the training stability and superior performance of CAME across various NLP tasks such as BERT and GPT-2 training. Notably, for BERT pre-training on the large batch size of 32,768, our proposed optimizer attains faster convergence and higher accuracy compared with the Adam optimizer. The implementation of CAME is publicly available.
Clinical BioBERT Hyperparameter Optimization using Genetic Algorithm
Feb 13, 2023



Clinical factors account only for a small portion, about 10-30%, of the controllable factors that affect an individual's health outcomes. The remaining factors include where a person was born and raised, where he/she pursued their education, what their work and family environment is like, etc. These factors are collectively referred to as Social Determinants of Health (SDoH). The majority of SDoH data is recorded in unstructured clinical notes by physicians and practitioners. Recording SDoH data in a structured manner (in an EHR) could greatly benefit from a dedicated ontology of SDoH terms. Our research focuses on extracting sentences from clinical notes, making use of such an SDoH ontology (called SOHO) to provide appropriate concepts. We utilize recent advancements in Deep Learning to optimize the hyperparameters of a Clinical BioBERT model for SDoH text. A genetic algorithm-based hyperparameter tuning regimen was implemented to identify optimal parameter settings. To implement a complete classifier, we pipelined Clinical BioBERT with two subsequent linear layers and two dropout layers. The output predicts whether a text fragment describes an SDoH issue of the patient. We compared the AdamW, Adafactor, and LAMB optimizers. In our experiments, AdamW outperformed the others in terms of accuracy.
Automatic Clipping: Differentially Private Deep Learning Made Easier and Stronger
Jun 14, 2022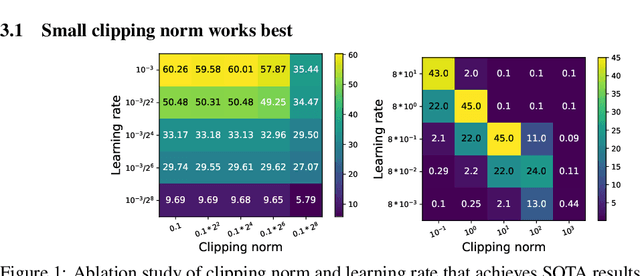



Per-example gradient clipping is a key algorithmic step that enables practical differential private (DP) training for deep learning models. The choice of clipping norm $R$, however, is shown to be vital for achieving high accuracy under DP. We propose an easy-to-use replacement, called AutoClipping, that eliminates the need to tune $R$ for any DP optimizers, including DP-SGD, DP-Adam, DP-LAMB and many others. The automatic variants are as private and computationally efficient as existing DP optimizers, but require no DP-specific hyperparameters and thus make DP training as amenable as the standard non-private training. We give a rigorous convergence analysis of automatic DP-SGD in the non-convex setting, which shows that it enjoys an asymptotic convergence rate that matches the standard SGD. We also demonstrate on various language and vision tasks that automatic clipping outperforms or matches the state-of-the-art, and can be easily employed with minimal changes to existing codebases.
Fed-LAMB: Layerwise and Dimensionwise Locally Adaptive Optimization Algorithm
Oct 01, 2021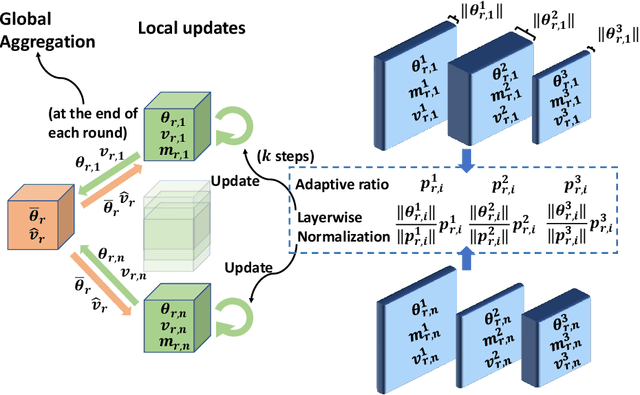

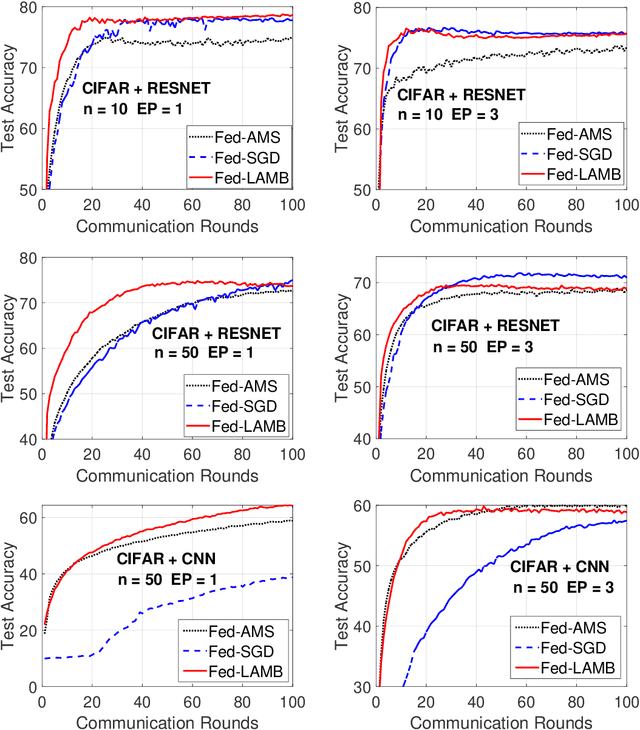
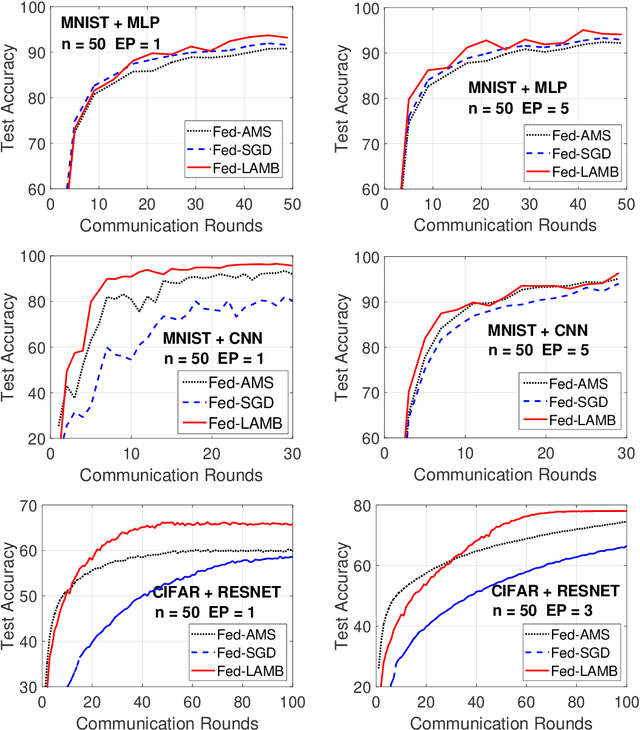
In the emerging paradigm of federated learning (FL), large amount of clients, such as mobile devices, are used to train possibly high-dimensional models on their respective data. Due to the low bandwidth of mobile devices, decentralized optimization methods need to shift the computation burden from those clients to the computation server while preserving privacy and reasonable communication cost. In this paper, we focus on the training of deep, as in multilayered, neural networks, under the FL settings. We present Fed-LAMB, a novel federated learning method based on a layerwise and dimensionwise updates of the local models, alleviating the nonconvexity and the multilayered nature of the optimization task at hand. We provide a thorough finite-time convergence analysis for Fed-LAMB characterizing how fast its gradient decreases. We provide experimental results under iid and non-iid settings to corroborate not only our theory, but also exhibit the faster convergence of our method, compared to the state-of-the-art.
Self-learning locally-optimal hypertuning using maximum entropy, and comparison of machine learning approaches for estimating fatigue life in composite materials
Oct 19, 2022

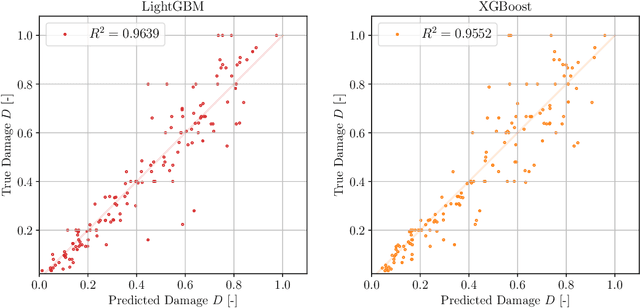
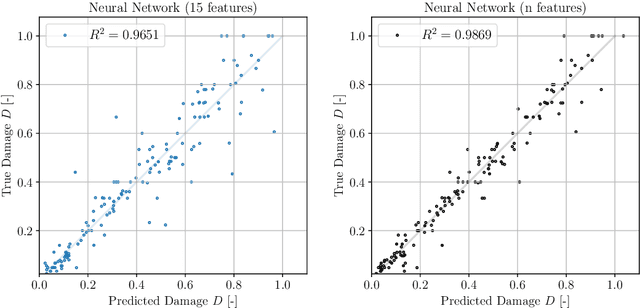
Applications of Structural Health Monitoring (SHM) combined with Machine Learning (ML) techniques enhance real-time performance tracking and increase structural integrity awareness of civil, aerospace and automotive infrastructures. This SHM-ML synergy has gained popularity in the last years thanks to the anticipation of maintenance provided by arising ML algorithms and their ability of handling large quantities of data and considering their influence in the problem. In this paper we develop a novel ML nearest-neighbors-alike algorithm based on the principle of maximum entropy to predict fatigue damage (Palmgren-Miner index) in composite materials by processing the signals of Lamb Waves -- a non-destructive SHM technique -- with other meaningful features such as layup parameters and stiffness matrices calculated from the Classical Laminate Theory (CLT). The full data analysis cycle is applied to a dataset of delamination experiments in composites. The predictions achieve a good level of accuracy, similar to other ML algorithms, e.g. Neural Networks or Gradient-Boosted Trees, and computation times are of the same order of magnitude. The key advantages of our proposal are: (1) The automatic determination of all the parameters involved in the prediction, so no hyperparameters have to be set beforehand, which saves time devoted to hypertuning the model and also represents an advantage for autonomous, self-supervised SHM. (2) No training is required, which, in an \textit{online learning} context where streams of data are fed continuously to the model, avoids repeated training -- essential for reliable real-time, continuous monitoring.
Large Scale Transfer Learning for Differentially Private Image Classification
May 06, 2022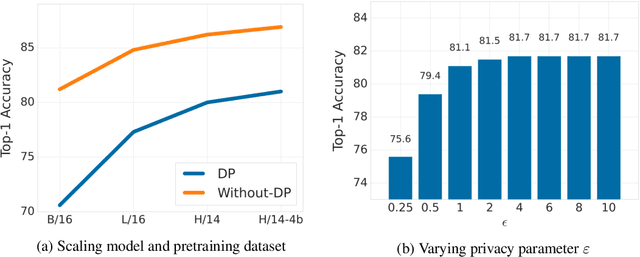
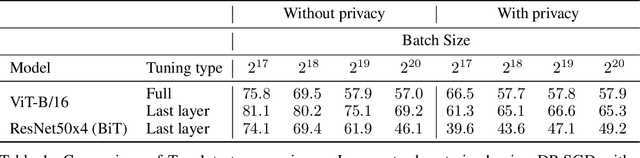
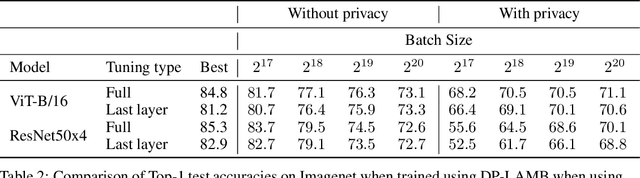
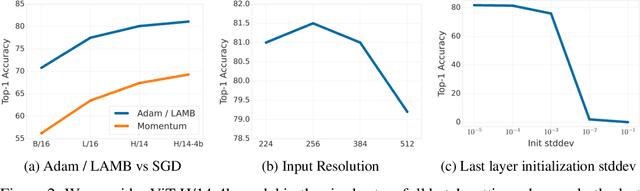
Differential Privacy (DP) provides a formal framework for training machine learning models with individual example level privacy. Training models with DP protects the model against leakage of sensitive data in a potentially adversarial setting. In the field of deep learning, Differentially Private Stochastic Gradient Descent (DP-SGD) has emerged as a popular private training algorithm. Private training using DP-SGD protects against leakage by injecting noise into individual example gradients, such that the trained model weights become nearly independent of the use any particular training example. While this result is quite appealing, the computational cost of training large-scale models with DP-SGD is substantially higher than non-private training. This is further exacerbated by the fact that increasing the number of parameters leads to larger degradation in utility with DP. In this work, we zoom in on the ImageNet dataset and demonstrate that similar to the non-private case, pre-training over-parameterized models on a large public dataset can lead to substantial gains when the model is finetuned privately. Moreover, by systematically comparing private and non-private models across a range of huge batch sizes, we find that similar to non-private setting, choice of optimizer can further improve performance substantially with DP. By switching from DP-SGD to DP-LAMB we saw improvement of up to 20$\%$ points (absolute). Finally, we show that finetuning just the last layer for a \emph{single step} in the full batch setting leads to both SOTA results of 81.7 $\%$ under a wide privacy budget range of $\epsilon \in [4, 10]$ and $\delta$ = $10^{-6}$ while minimizing the computational overhead substantially.