 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFed-LAMB: Layerwise and Dimensionwise Locally Adaptive Optimization Algorithm
Paper and Code
Oct 01, 2021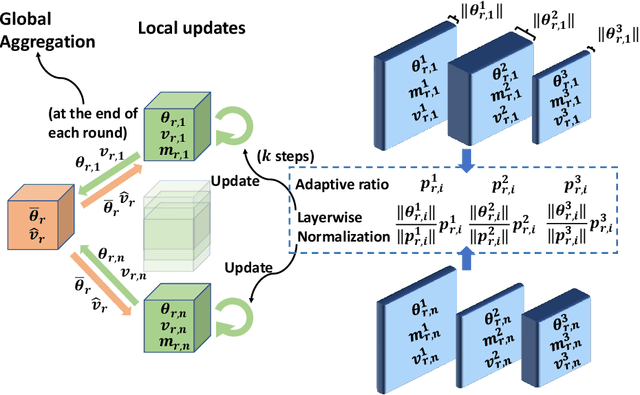

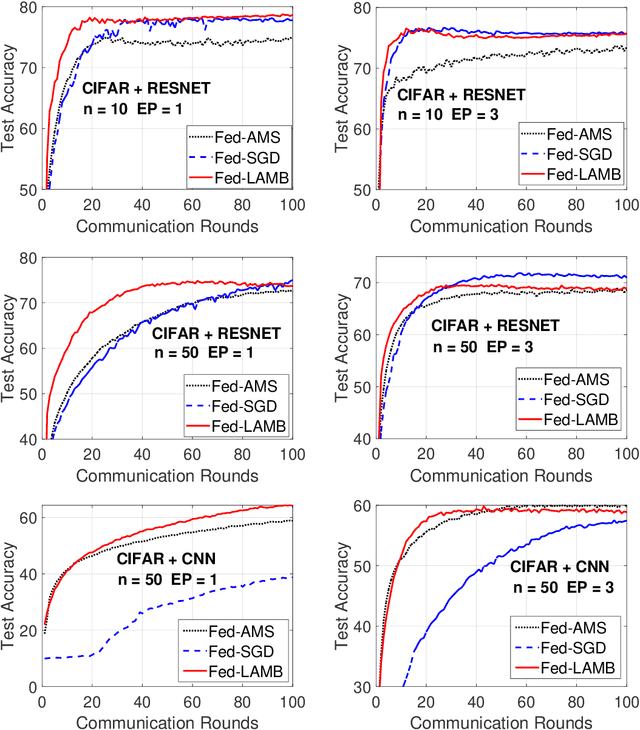
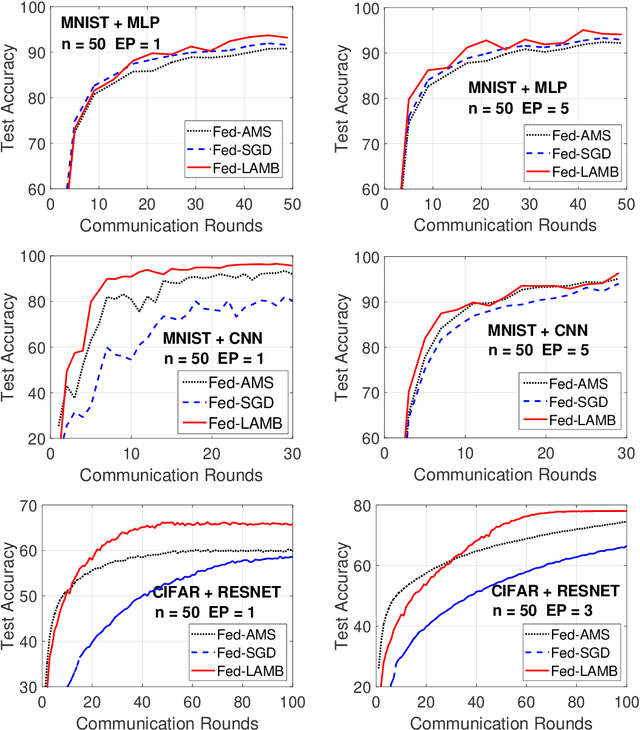
In the emerging paradigm of federated learning (FL), large amount of clients, such as mobile devices, are used to train possibly high-dimensional models on their respective data. Due to the low bandwidth of mobile devices, decentralized optimization methods need to shift the computation burden from those clients to the computation server while preserving privacy and reasonable communication cost. In this paper, we focus on the training of deep, as in multilayered, neural networks, under the FL settings. We present Fed-LAMB, a novel federated learning method based on a layerwise and dimensionwise updates of the local models, alleviating the nonconvexity and the multilayered nature of the optimization task at hand. We provide a thorough finite-time convergence analysis for Fed-LAMB characterizing how fast its gradient decreases. We provide experimental results under iid and non-iid settings to corroborate not only our theory, but also exhibit the faster convergence of our method, compared to the state-of-the-art.