 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Texture Recognition
Papers and Code
Minimum distance classification for nonlinear dynamical systems
Jan 07, 2026We address the problem of classifying trajectory data generated by some nonlinear dynamics, where each class corresponds to a distinct dynamical system. We propose Dynafit, a kernel-based method for learning a distance metric between training trajectories and the underlying dynamics. New observations are assigned to the class with the most similar dynamics according to the learned metric. The learning algorithm approximates the Koopman operator which globally linearizes the dynamics in a (potentially infinite) feature space associated with a kernel function. The distance metric is computed in feature space independently of its dimensionality by using the kernel trick common in machine learning. We also show that the kernel function can be tailored to incorporate partial knowledge of the dynamics when available. Dynafit is applicable to various classification tasks involving nonlinear dynamical systems and sensors. We illustrate its effectiveness on three examples: chaos detection with the logistic map, recognition of handwritten dynamics and of visual dynamic textures.
Better, But Not Sufficient: Testing Video ANNs Against Macaque IT Dynamics
Jan 06, 2026Feedforward artificial neural networks (ANNs) trained on static images remain the dominant models of the the primate ventral visual stream, yet they are intrinsically limited to static computations. The primate world is dynamic, and the macaque ventral visual pathways, specifically the inferior temporal (IT) cortex not only supports object recognition but also encodes object motion velocity during naturalistic video viewing. Does IT's temporal responses reflect nothing more than time-unfolded feedforward transformations, framewise features with shallow temporal pooling, or do they embody richer dynamic computations? We tested this by comparing macaque IT responses during naturalistic videos against static, recurrent, and video-based ANN models. Video models provided modest improvements in neural predictivity, particularly at later response stages, raising the question of what kind of dynamics they capture. To probe this, we applied a stress test: decoders trained on naturalistic videos were evaluated on "appearance-free" variants that preserve motion but remove shape and texture. IT population activity generalized across this manipulation, but all ANN classes failed. Thus, current video models better capture appearance-bound dynamics rather than the appearance-invariant temporal computations expressed in IT, underscoring the need for new objectives that encode biological temporal statistics and invariances.
Is Visual Realism Enough? Evaluating Gait Biometric Fidelity in Generative AI Human Animation
Dec 22, 2025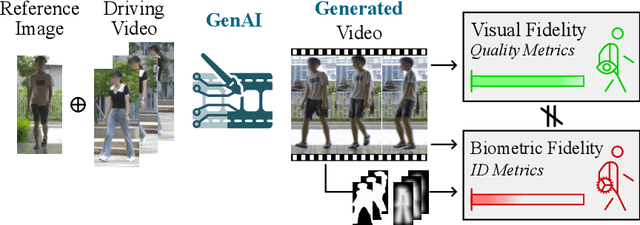

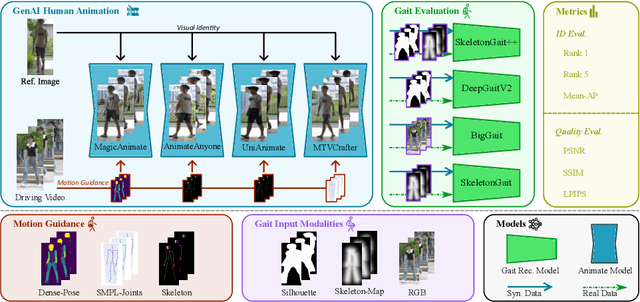
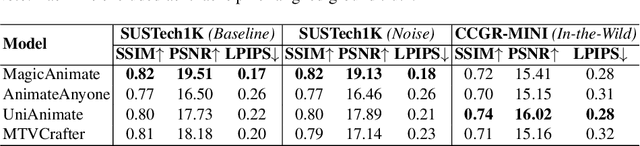
Generative AI (GenAI) models have revolutionized animation, enabling the synthesis of humans and motion patterns with remarkable visual fidelity. However, generating truly realistic human animation remains a formidable challenge, where even minor inconsistencies can make a subject appear unnatural. This limitation is particularly critical when AI-generated videos are evaluated for behavioral biometrics, where subtle motion cues that define identity are easily lost or distorted. The present study investigates whether state-of-the-art GenAI human animation models can preserve the subtle spatio-temporal details needed for person identification through gait biometrics. Specifically, we evaluate four different GenAI models across two primary evaluation tasks to assess their ability to i) restore gait patterns from reference videos under varying conditions of complexity, and ii) transfer these gait patterns to different visual identities. Our results show that while visual quality is mostly high, biometric fidelity remains low in tasks focusing on identification, suggesting that current GenAI models struggle to disentangle identity from motion. Furthermore, through an identity transfer task, we expose a fundamental flaw in appearance-based gait recognition: when texture is disentangled from motion, identification collapses, proving current GenAI models rely on visual attributes rather than temporal dynamics.
MCAQ-YOLO: Morphological Complexity-Aware Quantization for Efficient Object Detection with Curriculum Learning
Nov 17, 2025



Most neural network quantization methods apply uniform bit precision across spatial regions, ignoring the heterogeneous structural and textural complexity of visual data. This paper introduces MCAQ-YOLO, a morphological complexity-aware quantization framework for object detection. The framework employs five morphological metrics - fractal dimension, texture entropy, gradient variance, edge density, and contour complexity - to characterize local visual morphology and guide spatially adaptive bit allocation. By correlating these metrics with quantization sensitivity, MCAQ-YOLO dynamically adjusts bit precision according to spatial complexity. In addition, a curriculum-based quantization-aware training scheme progressively increases quantization difficulty to stabilize optimization and accelerate convergence. Experimental results demonstrate a strong correlation between morphological complexity and quantization sensitivity and show that MCAQ-YOLO achieves superior detection accuracy and convergence efficiency compared with uniform quantization. On a safety equipment dataset, MCAQ-YOLO attains 85.6 percent mAP@0.5 with an average of 4.2 bits and a 7.6x compression ratio, yielding 3.5 percentage points higher mAP than uniform 4-bit quantization while introducing only 1.8 ms of additional runtime overhead per image. Cross-dataset validation on COCO and Pascal VOC further confirms consistent performance gains, indicating that morphology-driven spatial quantization can enhance efficiency and robustness for computationally constrained, safety-critical visual recognition tasks.
DEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
Nov 14, 2025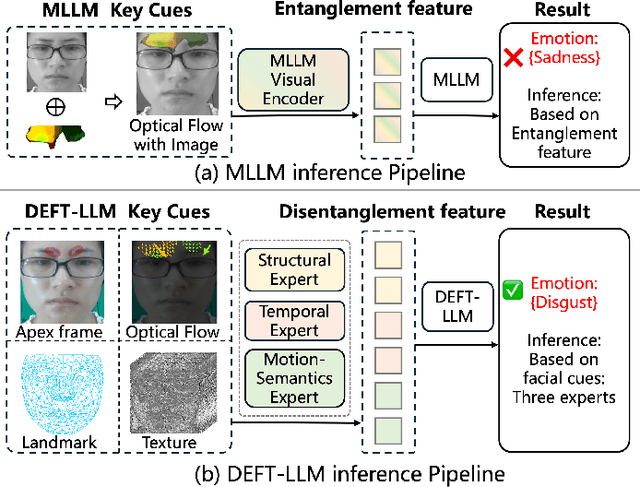
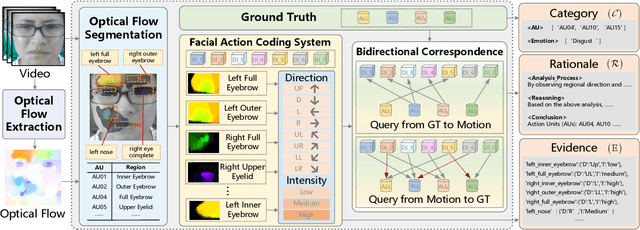
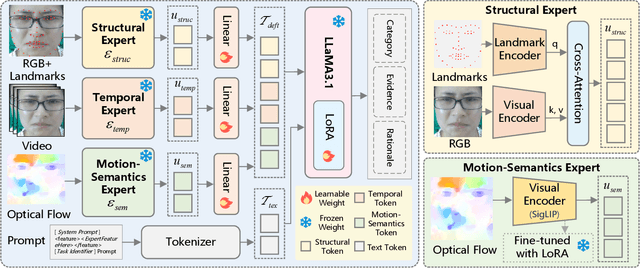
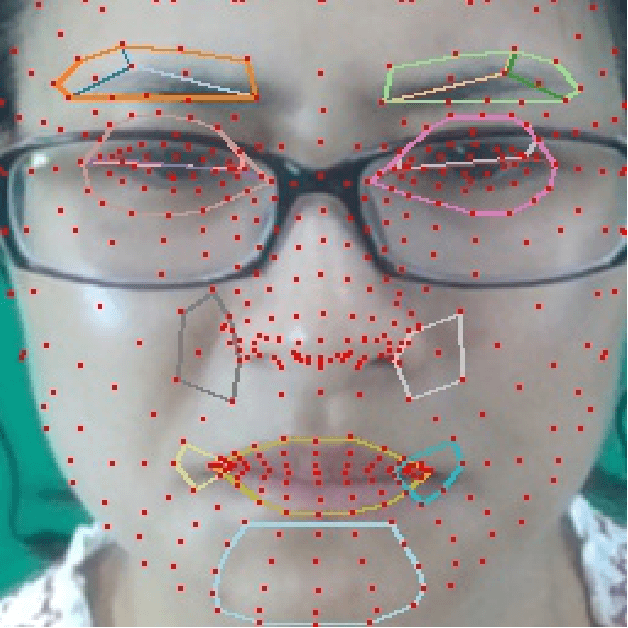
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.
AFM-Net: Advanced Fusing Hierarchical CNN Visual Priors with Global Sequence Modeling for Remote Sensing Image Scene Classification
Oct 31, 2025



Remote sensing image scene classification remains a challenging task, primarily due to the complex spatial structures and multi-scale characteristics of ground objects. Existing approaches see CNNs excel at modeling local textures, while Transformers excel at capturing global context. However, efficiently integrating them remains a bottleneck due to the high computational cost of Transformers. To tackle this, we propose AFM-Net, a novel Advanced Hierarchical Fusing framework that achieves effective local and global co-representation through two pathways: a CNN branch for extracting hierarchical visual priors, and a Mamba branch for efficient global sequence modeling. The core innovation of AFM-Net lies in its Hierarchical Fusion Mechanism, which progressively aggregates multi-scale features from both pathways, enabling dynamic cross-level feature interaction and contextual reconstruction to produce highly discriminative representations. These fused features are then adaptively routed through a Mixture-of-Experts classifier module, which dispatches them to the most suitable experts for fine-grained scene recognition. Experiments on AID, NWPU-RESISC45, and UC Merced show that AFM-Net obtains 93.72, 95.54, and 96.92 percent accuracy, surpassing state-of-the-art methods with balanced performance and efficiency. Code is available at https://github.com/tangyuanhao-qhu/AFM-Net.
UltraTac: Integrated Ultrasound-Augmented Visuotactile Sensor for Enhanced Robotic Perception
Aug 29, 2025



Visuotactile sensors provide high-resolution tactile information but are incapable of perceiving the material features of objects. We present UltraTac, an integrated sensor that combines visuotactile imaging with ultrasound sensing through a coaxial optoacoustic architecture. The design shares structural components and achieves consistent sensing regions for both modalities. Additionally, we incorporate acoustic matching into the traditional visuotactile sensor structure, enabling integration of the ultrasound sensing modality without compromising visuotactile performance. Through tactile feedback, we dynamically adjust the operating state of the ultrasound module to achieve flexible functional coordination. Systematic experiments demonstrate three key capabilities: proximity sensing in the 3-8 cm range ($R^2=0.90$), material classification (average accuracy: 99.20%), and texture-material dual-mode object recognition achieving 92.11% accuracy on a 15-class task. Finally, we integrate the sensor into a robotic manipulation system to concurrently detect container surface patterns and internal content, which verifies its potential for advanced human-machine interaction and precise robotic manipulation.
Landmark Guided Visual Feature Extractor for Visual Speech Recognition with Limited Resource
Aug 10, 2025Visual speech recognition is a technique to identify spoken content in silent speech videos, which has raised significant attention in recent years. Advancements in data-driven deep learning methods have significantly improved both the speed and accuracy of recognition. However, these deep learning methods can be effected by visual disturbances, such as lightning conditions, skin texture and other user-specific features. Data-driven approaches could reduce the performance degradation caused by these visual disturbances using models pretrained on large-scale datasets. But these methods often require large amounts of training data and computational resources, making them costly. To reduce the influence of user-specific features and enhance performance with limited data, this paper proposed a landmark guided visual feature extractor. Facial landmarks are used as auxiliary information to aid in training the visual feature extractor. A spatio-temporal multi-graph convolutional network is designed to fully exploit the spatial locations and spatio-temporal features of facial landmarks. Additionally, a multi-level lip dynamic fusion framework is introduced to combine the spatio-temporal features of the landmarks with the visual features extracted from the raw video frames. Experimental results show that this approach performs well with limited data and also improves the model's accuracy on unseen speakers.
Revealing Latent Information: A Physics-inspired Self-supervised Pre-training Framework for Noisy and Sparse Events
Aug 07, 2025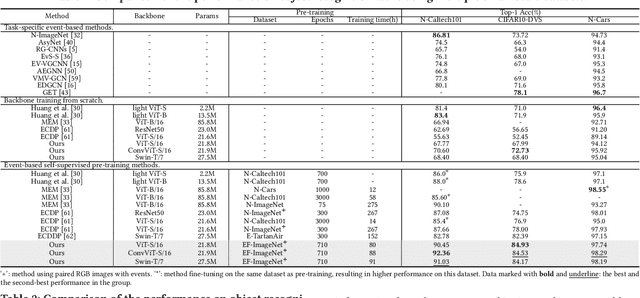

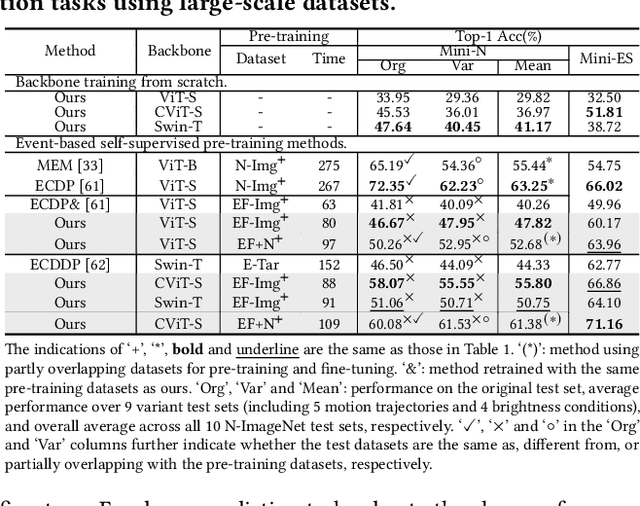
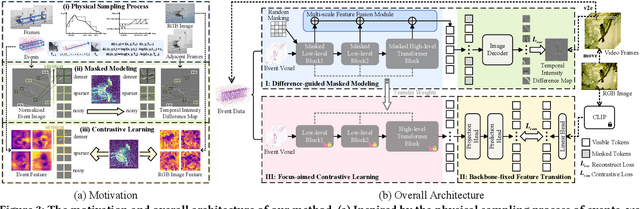
Event camera, a novel neuromorphic vision sensor, records data with high temporal resolution and wide dynamic range, offering new possibilities for accurate visual representation in challenging scenarios. However, event data is inherently sparse and noisy, mainly reflecting brightness changes, which complicates effective feature extraction. To address this, we propose a self-supervised pre-training framework to fully reveal latent information in event data, including edge information and texture cues. Our framework consists of three stages: Difference-guided Masked Modeling, inspired by the event physical sampling process, reconstructs temporal intensity difference maps to extract enhanced information from raw event data. Backbone-fixed Feature Transition contrasts event and image features without updating the backbone to preserve representations learned from masked modeling and stabilizing their effect on contrastive learning. Focus-aimed Contrastive Learning updates the entire model to improve semantic discrimination by focusing on high-value regions. Extensive experiments show our framework is robust and consistently outperforms state-of-the-art methods on various downstream tasks, including object recognition, semantic segmentation, and optical flow estimation. The code and dataset are available at https://github.com/BIT-Vision/EventPretrain.
ADD-SLAM: Adaptive Dynamic Dense SLAM with Gaussian Splatting
May 26, 2025Recent advancements in Neural Radiance Fields (NeRF) and 3D Gaussian-based Simultaneous Localization and Mapping (SLAM) methods have demonstrated exceptional localization precision and remarkable dense mapping performance. However, dynamic objects introduce critical challenges by disrupting scene consistency, leading to tracking drift and mapping artifacts. Existing methods that employ semantic segmentation or object detection for dynamic identification and filtering typically rely on predefined categorical priors, while discarding dynamic scene information crucial for robotic applications such as dynamic obstacle avoidance and environmental interaction. To overcome these challenges, we propose ADD-SLAM: an Adaptive Dynamic Dense SLAM framework based on Gaussian splitting. We design an adaptive dynamic identification mechanism grounded in scene consistency analysis, comparing geometric and textural discrepancies between real-time observations and historical maps. Ours requires no predefined semantic category priors and adaptively discovers scene dynamics. Precise dynamic object recognition effectively mitigates interference from moving targets during localization. Furthermore, we propose a dynamic-static separation mapping strategy that constructs a temporal Gaussian model to achieve online incremental dynamic modeling. Experiments conducted on multiple dynamic datasets demonstrate our method's flexible and accurate dynamic segmentation capabilities, along with state-of-the-art performance in both localization and mapping.