 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogo Recognition
Logo recognition is the process of identifying and categorizing different types of logos in images or videos.
Papers and Code
From Unlearning to UNBRANDING: A Benchmark for Trademark-Safe Text-to-Image Generation
Dec 15, 2025The rapid progress of text-to-image diffusion models raises significant concerns regarding the unauthorized reproduction of trademarked content. While prior work targets general concepts (e.g., styles, celebrities), it fails to address specific brand identifiers. Crucially, we note that brand recognition is multi-dimensional, extending beyond explicit logos to encompass distinctive structural features (e.g., a car's front grille). To tackle this, we introduce unbranding, a novel task for the fine-grained removal of both trademarks and subtle structural brand features, while preserving semantic coherence. To facilitate research, we construct a comprehensive benchmark dataset. Recognizing that existing brand detectors are limited to logos and fail to capture abstract trade dress (e.g., the shape of a Coca-Cola bottle), we introduce a novel evaluation metric based on Vision Language Models (VLMs). This VLM-based metric uses a question-answering framework to probe images for both explicit logos and implicit, holistic brand characteristics. Furthermore, we observe that as model fidelity increases, with newer systems (SDXL, FLUX) synthesizing brand identifiers more readily than older models (Stable Diffusion), the urgency of the unbranding challenge is starkly highlighted. Our results, validated by our VLM metric, confirm unbranding is a distinct, practically relevant problem requiring specialized techniques. Project Page: https://gmum.github.io/UNBRANDING/.
Logos as a Well-Tempered Pre-train for Sign Language Recognition
May 15, 2025



This paper examines two aspects of the isolated sign language recognition (ISLR) task. First, despite the availability of a number of datasets, the amount of data for most individual sign languages is limited. It poses the challenge of cross-language ISLR model training, including transfer learning. Second, similar signs can have different semantic meanings. It leads to ambiguity in dataset labeling and raises the question of the best policy for annotating such signs. To address these issues, this study presents Logos, a novel Russian Sign Language (RSL) dataset, the most extensive ISLR dataset by the number of signers and one of the largest available datasets while also the largest RSL dataset in size and vocabulary. It is shown that a model, pre-trained on the Logos dataset can be used as a universal encoder for other language SLR tasks, including few-shot learning. We explore cross-language transfer learning approaches and find that joint training using multiple classification heads benefits accuracy for the target lowresource datasets the most. The key feature of the Logos dataset is explicitly annotated visually similar sign groups. We show that explicitly labeling visually similar signs improves trained model quality as a visual encoder for downstream tasks. Based on the proposed contributions, we outperform current state-of-the-art results for the WLASL dataset and get competitive results for the AUTSL dataset, with a single stream model processing solely RGB video. The source code, dataset, and pre-trained models are publicly available.
AI-Driven Multi-Stage Computer Vision System for Defect Detection in Laser-Engraved Industrial Nameplates
Mar 05, 2025Automated defect detection in industrial manufacturing is essential for maintaining product quality and minimizing production errors. In air disc brake manufacturing, ensuring the precision of laser-engraved nameplates is crucial for accurate product identification and quality control. Engraving errors, such as misprints or missing characters, can compromise both aesthetics and functionality, leading to material waste and production delays. This paper presents a proof of concept for an AI-driven computer vision system that inspects and verifies laser-engraved nameplates, detecting defects in logos and alphanumeric strings. The system integrates object detection using YOLOv7, optical character recognition (OCR) with Tesseract, and anomaly detection through a residual variational autoencoder (ResVAE) along with other computer vision methods to enable comprehensive inspections at multiple stages. Experimental results demonstrate the system's effectiveness, achieving 91.33% accuracy and 100% recall, ensuring that defective nameplates are consistently detected and addressed. This solution highlights the potential of AI-driven visual inspection to enhance quality control, reduce manual inspection efforts, and improve overall manufacturing efficiency.
GLDesigner: Leveraging Multi-Modal LLMs as Designer for Enhanced Aesthetic Text Glyph Layouts
Nov 18, 2024

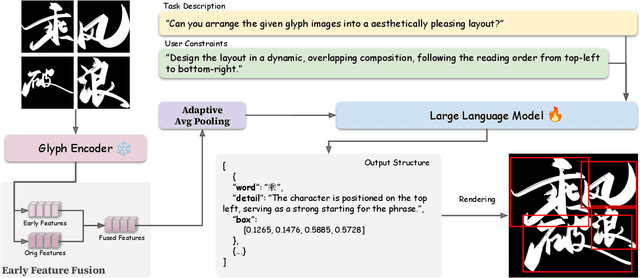
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this specific task which needs to take precise textural details and user constraints into consideration, but only on the broader tasks such as document/poster layout generation. In this paper, we propose a VLM-based framework that generates content-aware text logo layouts by integrating multi-modal inputs with user constraints, supporting a more flexible and stable layout design in real-world applications. We introduce two model techniques to reduce the computation for processing multiple glyph images simultaneously, while does not face performance degradation. To support instruction-tuning of out model, we construct two extensive text logo datasets, which are 5x more larger than the existing public dataset. Except for the geometric annotations (e.g. text masks and character recognition), we also compliment with comprehensive layout descriptions in natural language format, for more effective training to have reasoning ability when dealing with complex layouts and custom user constraints. Experimental studies demonstrate the effectiveness of our proposed model and datasets, when comparing with previous methods in various benchmarks to evaluate geometric aesthetics and human preferences. The code and datasets will be publicly available.
RL-LOGO: Deep Reinforcement Learning Localization for Logo Recognition
Dec 28, 2023
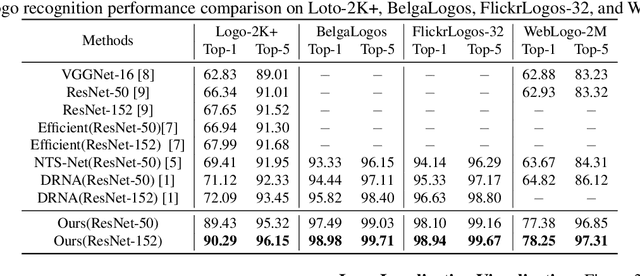
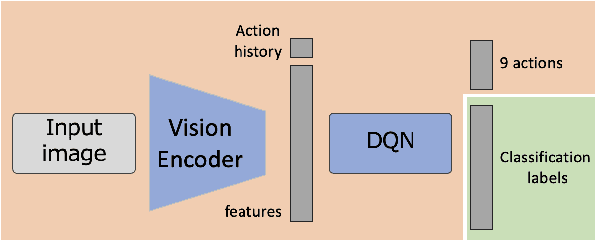

This paper proposes a novel logo image recognition approach incorporating a localization technique based on reinforcement learning. Logo recognition is an image classification task identifying a brand in an image. As the size and position of a logo vary widely from image to image, it is necessary to determine its position for accurate recognition. However, because there is no annotation for the position coordinates, it is impossible to train and infer the location of the logo in the image. Therefore, we propose a deep reinforcement learning localization method for logo recognition (RL-LOGO). It utilizes deep reinforcement learning to identify a logo region in images without annotations of the positions, thereby improving classification accuracy. We demonstrated a significant improvement in accuracy compared with existing methods in several published benchmarks. Specifically, we achieved an 18-point accuracy improvement over competitive methods on the complex dataset Logo-2K+. This demonstrates that the proposed method is a promising approach to logo recognition in real-world applications.
SLANT: Spurious Logo ANalysis Toolkit
Jun 03, 2024


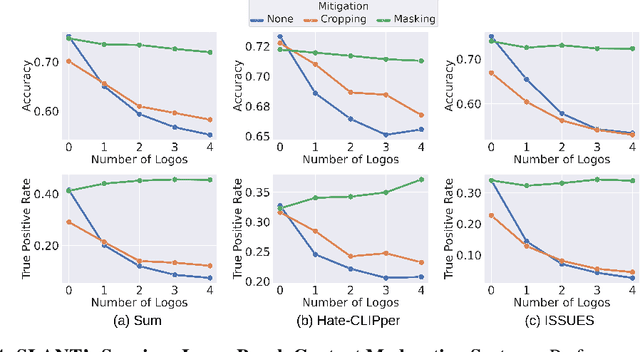
Online content is filled with logos, from ads and social media posts to website branding and product placements. Consequently, these logos are prevalent in the extensive web-scraped datasets used to pretrain Vision-Language Models, which are used for a wide array of tasks (content moderation, object classification). While these models have been shown to learn harmful correlations in various tasks, whether these correlations include logos remains understudied. Understanding this is especially important due to logos often being used by public-facing entities like brands and government agencies. To that end, we develop SLANT: A Spurious Logo ANalysis Toolkit. Our key finding is that some logos indeed lead to spurious incorrect predictions, for example, adding the Adidas logo to a photo of a person causes a model classify the person as greedy. SLANT contains a semi-automatic mechanism for mining such "spurious" logos. The mechanism consists of a comprehensive logo bank, CC12M-LogoBank, and an algorithm that searches the bank for logos that VLMs spuriously correlate with a user-provided downstream recognition target. We uncover various seemingly harmless logos that VL models correlate 1) with negative human adjectives 2) with the concept of `harmlessness'; causing models to misclassify harmful online content as harmless, and 3) with user-provided object concepts; causing lower recognition accuracy on ImageNet zero-shot classification. Furthermore, SLANT's logos can be seen as effective attacks against foundational models; an attacker could place a spurious logo on harmful content, causing the model to misclassify it as harmless. This threat is alarming considering the simplicity of logo attacks, increasing the attack surface of VL models. As a defense, we include in our Toolkit two effective mitigation strategies that seamlessly integrate with zero-shot inference of foundation models.
A New Method for Vehicle Logo Recognition Based on Swin Transformer
Jan 27, 2024Intelligent Transportation Systems (ITS) utilize sensors, cameras, and big data analysis to monitor real-time traffic conditions, aiming to improve traffic efficiency and safety. Accurate vehicle recognition is crucial in this process, and Vehicle Logo Recognition (VLR) stands as a key method. VLR enables effective management and monitoring by distinguishing vehicles on the road. Convolutional Neural Networks (CNNs) have made impressive strides in VLR research. However, achieving higher performance demands significant time and computational resources for training. Recently, the rise of Transformer models has brought new opportunities to VLR. Swin Transformer, with its efficient computation and global feature modeling capabilities, outperforms CNNs under challenging conditions. In this paper, we implement real-time VLR using Swin Transformer and fine-tune it for optimal performance. Extensive experiments conducted on three public vehicle logo datasets (HFUT-VL1, XMU, CTGU-VLD) demonstrate impressive top accuracy results of 99.28%, 100%, and 99.17%, respectively. Additionally, the use of a transfer learning strategy enables our method to be on par with state-of-the-art VLR methods. These findings affirm the superiority of our approach over existing methods. Future research can explore and optimize the application of the Swin Transformer in other vehicle vision recognition tasks to drive advancements in ITS.
LOGO: Video Text Spotting with Language Collaboration and Glyph Perception Model
May 29, 2024Video text spotting aims to simultaneously localize, recognize and track text instances in videos. To address the limited recognition capability of end-to-end methods, tracking the zero-shot results of state-of-the-art image text spotters directly can achieve impressive performance. However, owing to the domain gap between different datasets, these methods usually obtain limited tracking trajectories on extreme dataset. Fine-tuning transformer-based text spotters on specific datasets could yield performance enhancements, albeit at the expense of considerable training resources. In this paper, we propose a Language Collaboration and Glyph Perception Model, termed LOGO to enhance the performance of conventional text spotters through the integration of a synergy module. To achieve this goal, a language synergy classifier (LSC) is designed to explicitly discern text instances from background noise in the recognition stage. Specially, the language synergy classifier can output text content or background code based on the legibility of text regions, thus computing language scores. Subsequently, fusion scores are computed by taking the average of detection scores and language scores, and are utilized to re-score the detection results before tracking. By the re-scoring mechanism, the proposed LSC facilitates the detection of low-resolution text instances while filtering out text-like regions. Besides, the glyph supervision and visual position mixture module are proposed to enhance the recognition accuracy of noisy text regions, and acquire more discriminative tracking features, respectively. Extensive experiments on public benchmarks validate the effectiveness of the proposed method.
Enhancement of Bengali OCR by Specialized Models and Advanced Techniques for Diverse Document Types
Feb 07, 2024
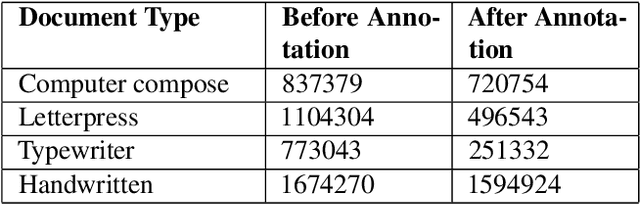
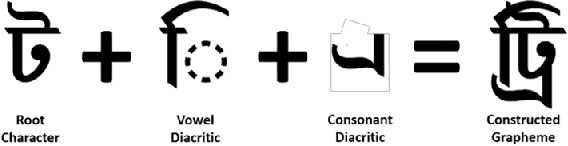
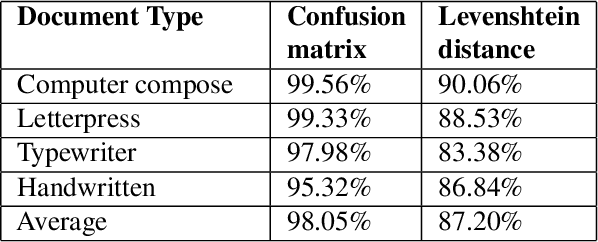
This research paper presents a unique Bengali OCR system with some capabilities. The system excels in reconstructing document layouts while preserving structure, alignment, and images. It incorporates advanced image and signature detection for accurate extraction. Specialized models for word segmentation cater to diverse document types, including computer-composed, letterpress, typewriter, and handwritten documents. The system handles static and dynamic handwritten inputs, recognizing various writing styles. Furthermore, it has the ability to recognize compound characters in Bengali. Extensive data collection efforts provide a diverse corpus, while advanced technical components optimize character and word recognition. Additional contributions include image, logo, signature and table recognition, perspective correction, layout reconstruction, and a queuing module for efficient and scalable processing. The system demonstrates outstanding performance in efficient and accurate text extraction and analysis.
* 8 pages, 7 figures, 4 table Link of the paper https://openaccess.thecvf.com/content/WACV2024W/WVLL/html/Rabby_Enhancement_of_Bengali_OCR_by_Specialized_Models_and_Advanced_Techniques_WACVW_2024_paper.html
LogoStyleFool: Vitiating Video Recognition Systems via Logo Style Transfer
Dec 15, 2023


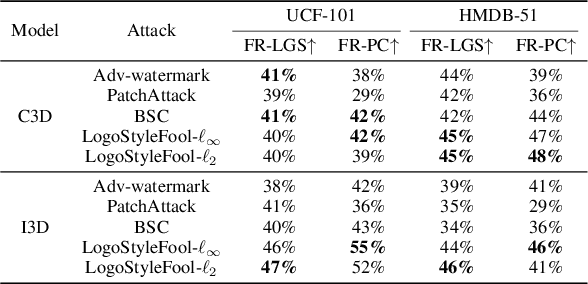
Video recognition systems are vulnerable to adversarial examples. Recent studies show that style transfer-based and patch-based unrestricted perturbations can effectively improve attack efficiency. These attacks, however, face two main challenges: 1) Adding large stylized perturbations to all pixels reduces the naturalness of the video and such perturbations can be easily detected. 2) Patch-based video attacks are not extensible to targeted attacks due to the limited search space of reinforcement learning that has been widely used in video attacks recently. In this paper, we focus on the video black-box setting and propose a novel attack framework named LogoStyleFool by adding a stylized logo to the clean video. We separate the attack into three stages: style reference selection, reinforcement-learning-based logo style transfer, and perturbation optimization. We solve the first challenge by scaling down the perturbation range to a regional logo, while the second challenge is addressed by complementing an optimization stage after reinforcement learning. Experimental results substantiate the overall superiority of LogoStyleFool over three state-of-the-art patch-based attacks in terms of attack performance and semantic preservation. Meanwhile, LogoStyleFool still maintains its performance against two existing patch-based defense methods. We believe that our research is beneficial in increasing the attention of the security community to such subregional style transfer attacks.