 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariation of Camera Parameters due to Common Physical Changes in Focal Length and Camera Pose
Sep 02, 2024Accurate calibration of camera intrinsic parameters is crucial to various computer vision-based applications in the fields of intelligent systems, autonomous vehicles, etc. However, existing calibration schemes are incompetent for finding general trend of the variation of camera parameters due to common physical changes. In this paper, it is demonstrated that major and minor variations due to changes in focal length and camera pose, respectively, can be identified with a recently proposed calibration method. It is readily observable from the experimental results that the former variations have different trends (directions) of principal point deviation for different types of camera, possibly due to different internal lens configurations, while the latter have very similar trends in the deviation which is most likely due to direction of gravity. Finally, to confirm the validity of such unprecedented findings, 3D to 2D reprojection errors are compared for different methods of camera calibration.
Single-image driven 3d viewpoint training data augmentation for effective wine label recognition
Apr 12, 2024



Confronting the critical challenge of insufficient training data in the field of complex image recognition, this paper introduces a novel 3D viewpoint augmentation technique specifically tailored for wine label recognition. This method enhances deep learning model performance by generating visually realistic training samples from a single real-world wine label image, overcoming the challenges posed by the intricate combinations of text and logos. Classical Generative Adversarial Network (GAN) methods fall short in synthesizing such intricate content combination. Our proposed solution leverages time-tested computer vision and image processing strategies to expand our training dataset, thereby broadening the range of training samples for deep learning applications. This innovative approach to data augmentation circumvents the constraints of limited training resources. Using the augmented training images through batch-all triplet metric learning on a Vision Transformer (ViT) architecture, we can get the most discriminative embedding features for every wine label, enabling us to perform one-shot recognition of existing wine labels in the training classes or future newly collected wine labels unavailable in the training. Experimental results show a significant increase in recognition accuracy over conventional 2D data augmentation techniques.
PartDistill: 3D Shape Part Segmentation by Vision-Language Model Distillation
Dec 07, 2023This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models (VLMs) to facilitate 3D shape part segmentation. PartDistill addresses three major challenges in this task: the lack of 3D segmentation in invisible or undetected regions in the 2D projections, inaccurate and inconsistent 2D predictions by VLMs, and the lack of knowledge accumulation across different 3D shapes. PartDistill consists of a teacher network that uses a VLM to make 2D predictions and a student network that learns from the 2D predictions while extracting geometrical features from multiple 3D shapes to carry out 3D part segmentation. A bi-directional distillation, including forward and backward distillations, is carried out within the framework, where the former forward distills the 2D predictions to the student network, and the latter improves the quality of the 2D predictions, which subsequently enhances the final 3D part segmentation. Moreover, PartDistill can exploit generative models that facilitate effortless 3D shape creation for generating knowledge sources to be distilled. Through extensive experiments, PartDistill boosts the existing methods with substantial margins on widely used ShapeNetPart and PartE datasets, by more than 15% and 12% higher mIoU scores, respectively.
Pentagon-Match (PMatch): Identification of View-Invariant Planar Feature for Local Feature Matching-Based Homography Estimation
May 27, 2023In computer vision, finding correct point correspondence among images plays an important role in many applications, such as image stitching, image retrieval, visual localization, etc. Most of the research works focus on the matching of local feature before a sampling method is employed, such as RANSAC, to verify initial matching results via repeated fitting of certain global transformation among the images. However, incorrect matches may still exist. Thus, a novel sampling scheme, Pentagon-Match (PMatch), is proposed in this work to verify the correctness of initially matched keypoints using pentagons randomly sampled from them. By ensuring shape and location of these pentagons are view-invariant with various evaluations of cross-ratio (CR), incorrect matches of keypoint can be identified easily with homography estimated from correctly matched pentagons. Experimental results show that highly accurate estimation of homography can be obtained efficiently for planar scenes of the HPatches dataset, based on keypoint matching results provided by LoFTR. Besides, accurate outlier identification for the above matching results and possible extension of the approach for multi-plane situation are also demonstrated.
Equivalence of Two Expressions of Principal Line
Jan 08, 2023


Geometry-based camera calibration using principal line is more precise and robust than calibration using optimization approaches; therefore, several researches try to re-derive the principal line from different views of 2D projective geometry to increase alternatives of the calibration process. In this report, algebraical equivalence of two expressions of principal line, one derived w.r.t homography and the other using for two sets of orthogonal vanishing points, is proved. Moreover, the extension of the second expression to incorporate infinite vanishing point is carried out with simple mathematics.
A Geometrically Constrained Point Matching based on View-invariant Cross-ratios, and Homography
Nov 06, 2022In computer vision, finding point correspondence among images plays an important role in many applications, such as image stitching, image retrieval, visual localization, etc. Most of the research worksfocus on the matching of local feature before a sampling method is employed, such as RANSAC, to verify initial matching results via repeated fitting of certain global transformation among the images. However, incorrect matches may still exist, while careful examination of such problems is often skipped. Accordingly, a geometrically constrained algorithm is proposed in this work to verify the correctness of initially matched SIFT keypoints based on view-invariant cross-ratios (CRs). By randomly forming pentagons from these keypoints and matching their shape and location among images with CRs, robust planar region estimation can be achieved efficiently for the above verification, while correct and incorrect matches of keypoints can be examined easily with respect to those shape and location matched pentagons. Experimental results show that satisfactory results can be obtained for various scenes with single as well as multiple planar regions.
Visualizing and Alleviating the Effect of Radial Distortion on Camera Calibration Using Principal Lines
Jun 28, 2022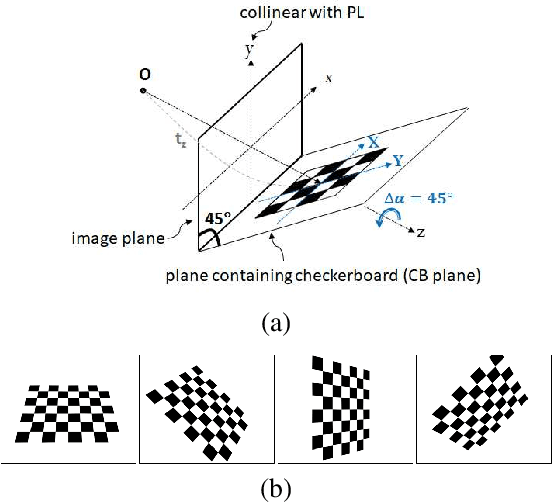


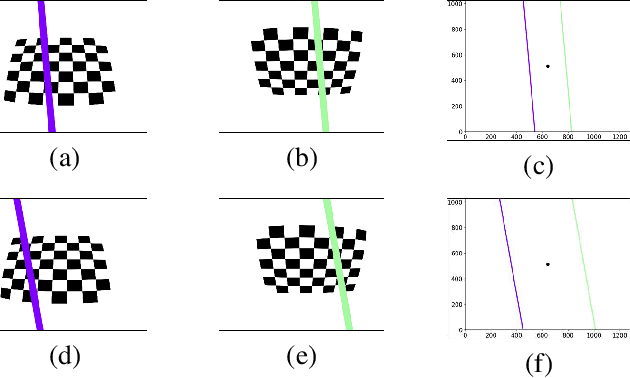
Preparing appropriate images for camera calibration is crucial to obtain accurate results. In this paper, new suggestions for preparing such data to alleviate the adverse effect of radial distortion for a calibration procedure using principal lines are developed through the investigations of: (i) identifying directions of checkerboard movements in an image which will result in maximum (and minimum) influence on the calibration results, and (ii) inspecting symmetry and monotonicity of such effect in (i) using the above principal lines. Accordingly, it is suggested that the estimation of principal point should based on linearly independent pairs of nearly parallel principal lines, with a member in each pair corresponds to a near 180-degree rotation (in the image plane) of the other. Experimental results show that more robust and consistent calibration results for the foregoing estimation can actually be obtained, compared with the renowned algebraic methods which estimate distortion parameters explicitly.
A New Technique of Camera Calibration: A Geometric Approach Based on Principal Lines
Aug 18, 2019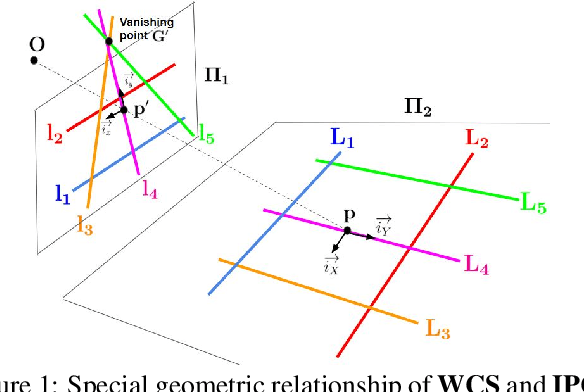

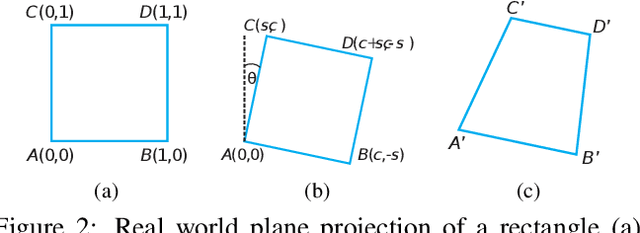
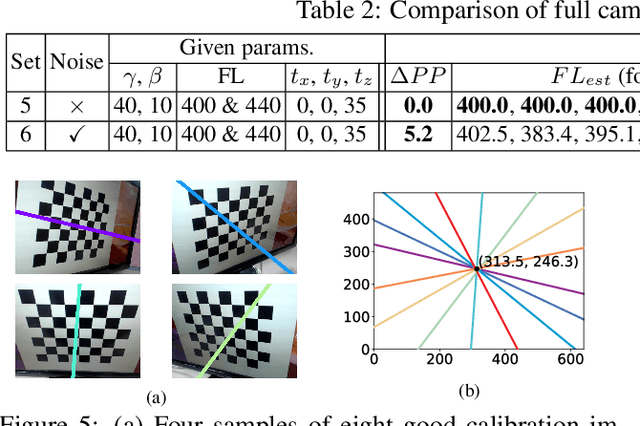
Camera calibration is a crucial prerequisite in many applications of computer vision. In this paper, a new, geometry-based camera calibration technique is proposed, which resolves two main issues associated with the widely used Zhang's method: (i) the lack of guidelines to avoid outliers in the computation and (ii) the assumption of fixed camera focal length. The proposed approach is based on the closed-form solution of principal lines (PLs), with their intersection being the principal point while each PL can concisely represent relative orientation/position (up to one degree of freedom for both) between a special pair of coordinate systems of image plane and calibration pattern. With such analytically tractable image features, computations associated with the calibration are greatly simplified, while the guidelines in (i) can be established intuitively. Experimental results for synthetic and real data show that the proposed approach does compare favorably with Zhang's method, in terms of correctness, robustness, and flexibility, and addresses issues (i) and (ii) satisfactorily.