 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartDistill: 3D Shape Part Segmentation by Vision-Language Model Distillation
Dec 07, 2023This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models (VLMs) to facilitate 3D shape part segmentation. PartDistill addresses three major challenges in this task: the lack of 3D segmentation in invisible or undetected regions in the 2D projections, inaccurate and inconsistent 2D predictions by VLMs, and the lack of knowledge accumulation across different 3D shapes. PartDistill consists of a teacher network that uses a VLM to make 2D predictions and a student network that learns from the 2D predictions while extracting geometrical features from multiple 3D shapes to carry out 3D part segmentation. A bi-directional distillation, including forward and backward distillations, is carried out within the framework, where the former forward distills the 2D predictions to the student network, and the latter improves the quality of the 2D predictions, which subsequently enhances the final 3D part segmentation. Moreover, PartDistill can exploit generative models that facilitate effortless 3D shape creation for generating knowledge sources to be distilled. Through extensive experiments, PartDistill boosts the existing methods with substantial margins on widely used ShapeNetPart and PartE datasets, by more than 15% and 12% higher mIoU scores, respectively.
A New Technique of Camera Calibration: A Geometric Approach Based on Principal Lines
Aug 18, 2019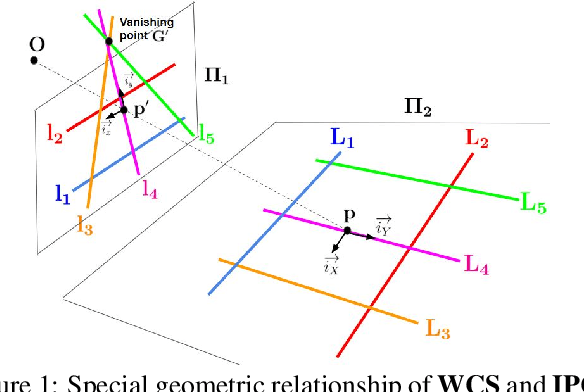

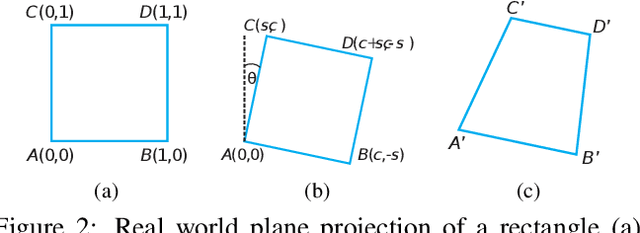
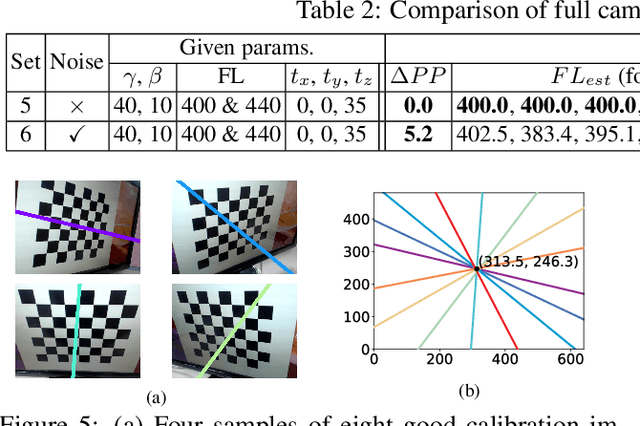
Camera calibration is a crucial prerequisite in many applications of computer vision. In this paper, a new, geometry-based camera calibration technique is proposed, which resolves two main issues associated with the widely used Zhang's method: (i) the lack of guidelines to avoid outliers in the computation and (ii) the assumption of fixed camera focal length. The proposed approach is based on the closed-form solution of principal lines (PLs), with their intersection being the principal point while each PL can concisely represent relative orientation/position (up to one degree of freedom for both) between a special pair of coordinate systems of image plane and calibration pattern. With such analytically tractable image features, computations associated with the calibration are greatly simplified, while the guidelines in (i) can be established intuitively. Experimental results for synthetic and real data show that the proposed approach does compare favorably with Zhang's method, in terms of correctness, robustness, and flexibility, and addresses issues (i) and (ii) satisfactorily.