 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaPOC: Japanese Post-OCR Correction Benchmark using Vouchers
Sep 30, 2024In this paper, we create benchmarks and assess the effectiveness of error correction methods for Japanese vouchers in OCR (Optical Character Recognition) systems. It is essential for automation processing to correctly recognize scanned voucher text, such as the company name on invoices. However, perfect recognition is complex due to the noise, such as stamps. Therefore, it is crucial to correctly rectify erroneous OCR results. However, no publicly available OCR error correction benchmarks for Japanese exist, and methods have not been adequately researched. In this study, we measured text recognition accuracy by existing services on Japanese vouchers and developed a post-OCR correction benchmark. Then, we proposed simple baselines for error correction using language models and verified whether the proposed method could effectively correct these errors. In the experiments, the proposed error correction algorithm significantly improved overall recognition accuracy.
JSTR: Judgment Improves Scene Text Recognition
Apr 09, 2024



In this paper, we present a method for enhancing the accuracy of scene text recognition tasks by judging whether the image and text match each other. While previous studies focused on generating the recognition results from input images, our approach also considers the model's misrecognition results to understand its error tendencies, thus improving the text recognition pipeline. This method boosts text recognition accuracy by providing explicit feedback on the data that the model is likely to misrecognize by predicting correct or incorrect between the image and text. The experimental results on publicly available datasets demonstrate that our proposed method outperforms the baseline and state-of-the-art methods in scene text recognition.
LayoutLLM: Large Language Model Instruction Tuning for Visually Rich Document Understanding
Mar 21, 2024


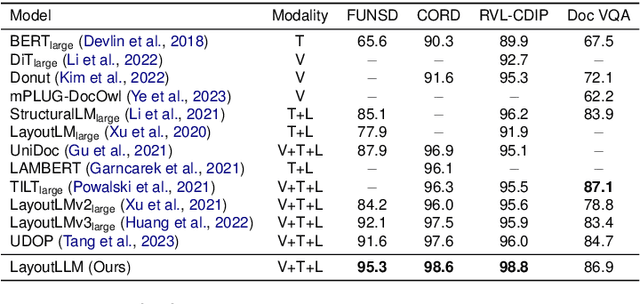
This paper proposes LayoutLLM, a more flexible document analysis method for understanding imaged documents. Visually Rich Document Understanding tasks, such as document image classification and information extraction, have gained significant attention due to their importance. Existing methods have been developed to enhance document comprehension by incorporating pre-training awareness of images, text, and layout structure. However, these methods require fine-tuning for each task and dataset, and the models are expensive to train and operate. To overcome this limitation, we propose a new LayoutLLM that integrates these with large-scale language models (LLMs). By leveraging the strengths of existing research in document image understanding and LLMs' superior language understanding capabilities, the proposed model, fine-tuned with multimodal instruction datasets, performs an understanding of document images in a single model. Our experiments demonstrate improvement over the baseline model in various document analysis tasks.
RL-LOGO: Deep Reinforcement Learning Localization for Logo Recognition
Dec 28, 2023
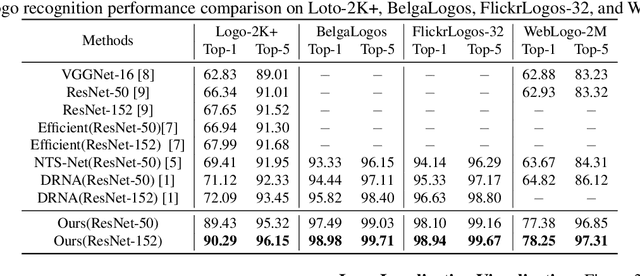
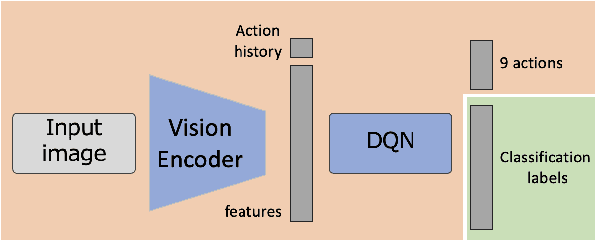

This paper proposes a novel logo image recognition approach incorporating a localization technique based on reinforcement learning. Logo recognition is an image classification task identifying a brand in an image. As the size and position of a logo vary widely from image to image, it is necessary to determine its position for accurate recognition. However, because there is no annotation for the position coordinates, it is impossible to train and infer the location of the logo in the image. Therefore, we propose a deep reinforcement learning localization method for logo recognition (RL-LOGO). It utilizes deep reinforcement learning to identify a logo region in images without annotations of the positions, thereby improving classification accuracy. We demonstrated a significant improvement in accuracy compared with existing methods in several published benchmarks. Specifically, we achieved an 18-point accuracy improvement over competitive methods on the complex dataset Logo-2K+. This demonstrates that the proposed method is a promising approach to logo recognition in real-world applications.
FA Team at the NTCIR-17 UFO Task
Oct 31, 2023The FA team participated in the Table Data Extraction (TDE) and Text-to-Table Relationship Extraction (TTRE) tasks of the NTCIR-17 Understanding of Non-Financial Objects in Financial Reports (UFO). This paper reports our approach to solving the problems and discusses the official results. We successfully utilized various enhancement techniques based on the ELECTRA language model to extract valuable data from tables. Our efforts resulted in an impressive TDE accuracy rate of 93.43 %, positioning us in second place on the Leaderboard rankings. This outstanding achievement is a testament to our proposed approach's effectiveness. In the TTRE task, we proposed the rule-based method to extract meaningful relationships between the text and tables task and confirmed the performance.
DTrOCR: Decoder-only Transformer for Optical Character Recognition
Aug 30, 2023



Typical text recognition methods rely on an encoder-decoder structure, in which the encoder extracts features from an image, and the decoder produces recognized text from these features. In this study, we propose a simpler and more effective method for text recognition, known as the Decoder-only Transformer for Optical Character Recognition (DTrOCR). This method uses a decoder-only Transformer to take advantage of a generative language model that is pre-trained on a large corpus. We examined whether a generative language model that has been successful in natural language processing can also be effective for text recognition in computer vision. Our experiments demonstrated that DTrOCR outperforms current state-of-the-art methods by a large margin in the recognition of printed, handwritten, and scene text in both English and Chinese.
DiffusionSTR: Diffusion Model for Scene Text Recognition
Jun 29, 2023This paper presents Diffusion Model for Scene Text Recognition (DiffusionSTR), an end-to-end text recognition framework using diffusion models for recognizing text in the wild. While existing studies have viewed the scene text recognition task as an image-to-text transformation, we rethought it as a text-text one under images in a diffusion model. We show for the first time that the diffusion model can be applied to text recognition. Furthermore, experimental results on publicly available datasets show that the proposed method achieves competitive accuracy compared to state-of-the-art methods.
A3S: Adversarial learning of semantic representations for Scene-Text Spotting
Feb 21, 2023Scene-text spotting is a task that predicts a text area on natural scene images and recognizes its text characters simultaneously. It has attracted much attention in recent years due to its wide applications. Existing research has mainly focused on improving text region detection, not text recognition. Thus, while detection accuracy is improved, the end-to-end accuracy is insufficient. Texts in natural scene images tend to not be a random string of characters but a meaningful string of characters, a word. Therefore, we propose adversarial learning of semantic representations for scene text spotting (A3S) to improve end-to-end accuracy, including text recognition. A3S simultaneously predicts semantic features in the detected text area instead of only performing text recognition based on existing visual features. Experimental results on publicly available datasets show that the proposed method achieves better accuracy than other methods.