 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue State Tracking
Dialogue state tracking consists of determining at each turn of a dialogue the full representation of what the user wants at that point in the dialogue, which contains a goal constraint, a set of requested slots, and the user's dialogue act.
Papers and Code
From Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents
Jan 30, 2026Interactive tool-using agents must solve real-world tasks via multi-turn interaction with both humans and external environments, requiring dialogue state tracking, multi-step tool execution, while following complex instructions. Post-training such agents is challenging because synthesis for high-quality multi-turn tool-use data is difficult to scale, and reinforcement learning (RL) could face noisy signals caused by user simulation, leading to degraded training efficiency. We propose a unified framework that combines a self-evolving data agent with verifier-based RL. Our system, EigenData, is a hierarchical multi-agent engine that synthesizes tool-grounded dialogues together with executable per-instance checkers, and improves generation reliability via closed-loop self-evolving process that updates prompts and workflow. Building on the synthetic data, we develop an RL recipe that first fine-tunes the user model and then applies GRPO-style training with trajectory-level group-relative advantages and dynamic filtering, yielding consistent improvements beyond SFT. Evaluated on tau^2-bench, our best model reaches 73.0% pass^1 on Airline and 98.3% pass^1 on Telecom, matching or exceeding frontier models. Overall, our results suggest a scalable pathway for bootstrapping complex tool-using behaviors without expensive human annotation.
PsyProbe: Proactive and Interpretable Dialogue through User State Modeling for Exploratory Counseling
Jan 27, 2026Recent advances in large language models have enabled mental health dialogue systems, yet existing approaches remain predominantly reactive, lacking systematic user state modeling for proactive therapeutic exploration. We introduce PsyProbe, a dialogue system designed for the exploration phase of counseling that systematically tracks user psychological states through the PPPPPI framework (Presenting, Predisposing, Precipitating, Perpetuating, Protective, Impact) augmented with cognitive error detection. PsyProbe combines State Builder for extracting structured psychological profiles, Memory Construction for tracking information gaps, Strategy Planner for Motivational Interviewing behavioral codes, and Response Generator with Question Ideation and Critic/Revision modules to generate contextually appropriate, proactive questions. We evaluate PsyProbe with 27 participants in real-world Korean counseling scenarios, including automatic evaluation across ablation modes, user evaluation, and expert evaluation by a certified counselor. The full PsyProbe model consistently outperforms baseline and ablation modes in automatic evaluation. User evaluation demonstrates significantly increased engagement intention and improved naturalness compared to baseline. Expert evaluation shows that PsyProbe substantially improves core issue understanding and achieves question rates comparable to professional counselors, validating the effectiveness of systematic state modeling and proactive questioning for therapeutic exploration.
Understanding Mental States to Guide Social Influence in Multi-Person Group Dialogue
Jan 20, 2026Existing dynamic Theory of Mind (ToM) benchmarks mostly place language models in a passive role: the model reads a sequence of connected scenarios and reports what people believe, feel, intend, and do as these states change. In real social interaction, ToM is also used for action: a speaker plans what to say in order to shift another person's mental-state trajectory toward a goal. We introduce SocialMindChange, a benchmark that moves from tracking minds to changing minds in social interaction. Each instance defines a social context with 4 characters and five connected scenes. The model plays one character and generates dialogue across the five scenes to reach the target while remaining consistent with the evolving states of all participants. SocialMindChange also includes selected higher-order states. Using a structured four-step framework, we construct 1,200 social contexts, covering 6000 scenarios and over 90,000 questions, each validated for realism and quality. Evaluations on ten state-of-the-art LLMs show that their average performance is 54.2% below human performance. This gap suggests that current LLMs still struggle to maintain and change mental-state representations across long, linked interactions.
Bridging the Knowledge-Action Gap by Evaluating LLMs in Dynamic Dental Clinical Scenarios
Jan 19, 2026The transition of Large Language Models (LLMs) from passive knowledge retrievers to autonomous clinical agents demands a shift in evaluation-from static accuracy to dynamic behavioral reliability. To explore this boundary in dentistry, a domain where high-quality AI advice uniquely empowers patient-participatory decision-making, we present the Standardized Clinical Management & Performance Evaluation (SCMPE) benchmark, which comprehensively assesses performance from knowledge-oriented evaluations (static objective tasks) to workflow-based simulations (multi-turn simulated patient interactions). Our analysis reveals that while models demonstrate high proficiency in static objective tasks, their performance precipitates in dynamic clinical dialogues, identifying that the primary bottleneck lies not in knowledge retention, but in the critical challenges of active information gathering and dynamic state tracking. Mapping "Guideline Adherence" versus "Decision Quality" reveals a prevalent "High Efficacy, Low Safety" risk in general models. Furthermore, we quantify the impact of Retrieval-Augmented Generation (RAG). While RAG mitigates hallucinations in static tasks, its efficacy in dynamic workflows is limited and heterogeneous, sometimes causing degradation. This underscores that external knowledge alone cannot bridge the reasoning gap without domain-adaptive pre-training. This study empirically charts the capability boundaries of dental LLMs, providing a roadmap for bridging the gap between standardized knowledge and safe, autonomous clinical practice.
CALM-IT: Generating Realistic Long-Form Motivational Interviewing Dialogues with Dual-Actor Conversational Dynamics Tracking
Jan 15, 2026Large Language Models (LLMs) are increasingly used in mental health-related settings, yet they struggle to sustain realistic, goal-directed dialogue over extended interactions. While LLMs generate fluent responses, they optimize locally for the next turn rather than maintaining a coherent model of therapeutic progress, leading to brittleness and long-horizon drift. We introduce CALM-IT, a framework for generating and evaluating long-form Motivational Interviewing (MI) dialogues that explicitly models dual-actor conversational dynamics. CALM-IT represents therapist-client interaction as a bidirectional state-space process, in which both agents continuously update inferred alignment, mental states, and short-term goals to guide strategy selection and utterance generation. Across large-scale evaluations, CALM-IT consistently outperforms strong baselines in Effectiveness and Goal Alignment and remains substantially more stable as conversation length increases. Although CALM-IT initiates fewer therapist redirections, it achieves the highest client acceptance rate (64.3%), indicating more precise and therapeutically aligned intervention timing. Overall, CALM-IT provides evidence for modeling evolving conversational state being essential for generating high-quality long-form synthetic conversations.
RealMem: Benchmarking LLMs in Real-World Memory-Driven Interaction
Jan 11, 2026As Large Language Models (LLMs) evolve from static dialogue interfaces to autonomous general agents, effective memory is paramount to ensuring long-term consistency. However, existing benchmarks primarily focus on casual conversation or task-oriented dialogue, failing to capture **"long-term project-oriented"** interactions where agents must track evolving goals. To bridge this gap, we introduce **RealMem**, the first benchmark grounded in realistic project scenarios. RealMem comprises over 2,000 cross-session dialogues across eleven scenarios, utilizing natural user queries for evaluation. We propose a synthesis pipeline that integrates Project Foundation Construction, Multi-Agent Dialogue Generation, and Memory and Schedule Management to simulate the dynamic evolution of memory. Experiments reveal that current memory systems face significant challenges in managing the long-term project states and dynamic context dependencies inherent in real-world projects. Our code and datasets are available at [https://github.com/AvatarMemory/RealMemBench](https://github.com/AvatarMemory/RealMemBench).
MedKGI: Iterative Differential Diagnosis with Medical Knowledge Graphs and Information-Guided Inquiring
Dec 30, 2025Recent advancements in Large Language Models (LLMs) have demonstrated significant promise in clinical diagnosis. However, current models struggle to emulate the iterative, diagnostic hypothesis-driven reasoning of real clinical scenarios. Specifically, current LLMs suffer from three critical limitations: (1) generating hallucinated medical content due to weak grounding in verified knowledge, (2) asking redundant or inefficient questions rather than discriminative ones that hinder diagnostic progress, and (3) losing coherence over multi-turn dialogues, leading to contradictory or inconsistent conclusions. To address these challenges, we propose MedKGI, a diagnostic framework grounded in clinical practices. MedKGI integrates a medical knowledge graph (KG) to constrain reasoning to validated medical ontologies, selects questions based on information gain to maximize diagnostic efficiency, and adopts an OSCE-format structured state to maintain consistent evidence tracking across turns. Experiments on clinical benchmarks show that MedKGI outperforms strong LLM baselines in both diagnostic accuracy and inquiry efficiency, improving dialogue efficiency by 30% on average while maintaining state-of-the-art accuracy.
The Speech-LLM Takes It All: A Truly Fully End-to-End Spoken Dialogue State Tracking Approach
Oct 10, 2025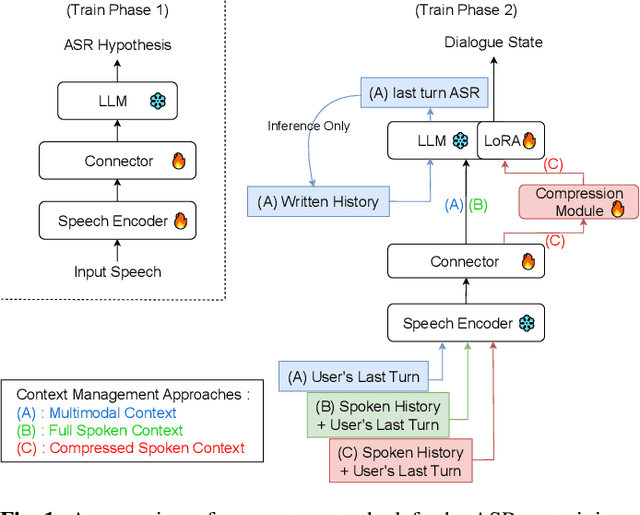

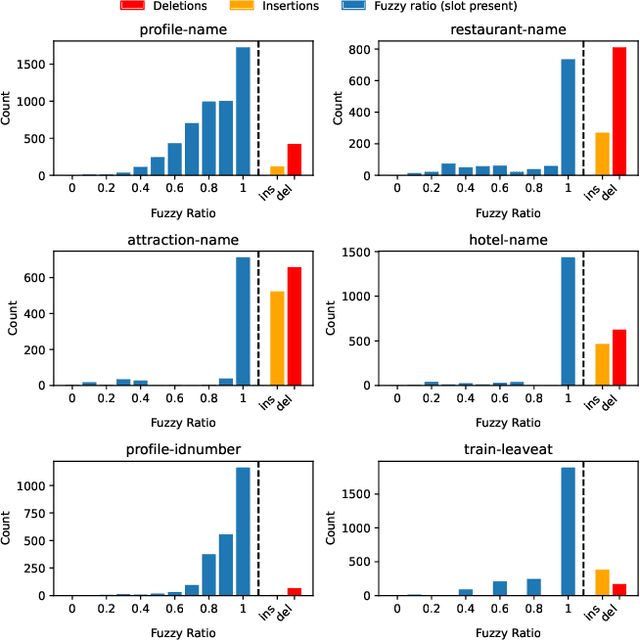
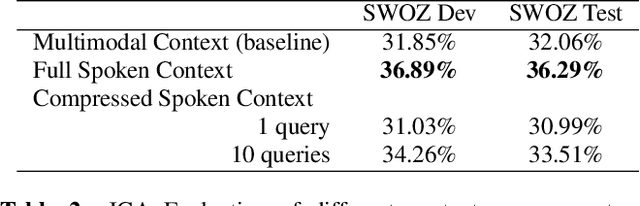
This paper presents a comparative study of context management strategies for end-to-end Spoken Dialog State Tracking using Speech-LLMs. We systematically evaluate traditional multimodal context (combining text history and spoken current turn), full spoken history, and compressed spoken history approaches. Our experiments on the SpokenWOZ corpus demonstrate that providing the full spoken conversation as input yields the highest performance among models of similar size, significantly surpassing prior methods. Furthermore, we show that attention-pooling-based compression of the spoken history offers a strong trade-off, maintaining competitive accuracy with reduced context size. Detailed analysis confirms that improvements stem from more effective context utilization.
Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models
Nov 12, 2025



Emotional support is a core capability in human-AI interaction, with applications including psychological counseling, role play, and companionship. However, existing evaluations of large language models (LLMs) often rely on short, static dialogues and fail to capture the dynamic and long-term nature of emotional support. To overcome this limitation, we shift from snapshot-based evaluation to trajectory-based assessment, adopting a user-centered perspective that evaluates models based on their ability to improve and stabilize user emotional states over time. Our framework constructs a large-scale benchmark consisting of 328 emotional contexts and 1,152 disturbance events, simulating realistic emotional shifts under evolving dialogue scenarios. To encourage psychologically grounded responses, we constrain model outputs using validated emotion regulation strategies such as situation selection and cognitive reappraisal. User emotional trajectories are modeled as a first-order Markov process, and we apply causally-adjusted emotion estimation to obtain unbiased emotional state tracking. Based on this framework, we introduce three trajectory-level metrics: Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP). These metrics collectively capture user emotional dynamics over time and support comprehensive evaluation of long-term emotional support performance of LLMs. Extensive evaluations across a diverse set of LLMs reveal significant disparities in emotional support capabilities and provide actionable insights for model development.
One Battle After Another: Probing LLMs' Limits on Multi-Turn Instruction Following with a Benchmark Evolving Framework
Nov 05, 2025Understanding how well large language models can follow users' instructions throughout a dialogue spanning multiple topics is of great importance for data-intensive conversational applications. Existing benchmarks are often limited to a fixed number of turns, making them susceptible to saturation and failing to account for the user's interactive experience. In this work, we propose an extensible framework for assessing multi-turn instruction-following ability. At its core, our framework decouples linguistic surface forms from user intent simulation through a three-layer mechanism that tracks constraints, instructions, and topics. This framework mimics User-LLM interaction by enabling the dynamic construction of benchmarks with state changes and tracebacks, terminating a conversation only when the model exhausts a simulated user's patience. We define a suite of metrics capturing the quality of the interaction process. Using this framework, we construct EvolIF, an evolving instruction-following benchmark incorporating nine distinct constraint types. Our results indicate that GPT-5 exhibits superior instruction-following performance. It sustains an average of 18.54 conversational turns and demonstrates 70.31% robustness, outperforming Gemini-2.5-Pro by a significant margin of 11.41%, while other models lag far behind. All of the data and code will be made publicly available online.