 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D Mot
Papers and Code
Stable at Any Speed: Speed-Driven Multi-Object Tracking with Learnable Kalman Filtering
Aug 01, 2025Multi-object tracking (MOT) enables autonomous vehicles to continuously perceive dynamic objects, supplying essential temporal cues for prediction, behavior understanding, and safe planning. However, conventional tracking-by-detection methods typically rely on static coordinate transformations based on ego-vehicle poses, disregarding ego-vehicle speed-induced variations in observation noise and reference frame changes, which degrades tracking stability and accuracy in dynamic, high-speed scenarios. In this paper, we investigate the critical role of ego-vehicle speed in MOT and propose a Speed-Guided Learnable Kalman Filter (SG-LKF) that dynamically adapts uncertainty modeling to ego-vehicle speed, significantly improving stability and accuracy in highly dynamic scenarios. Central to SG-LKF is MotionScaleNet (MSNet), a decoupled token-mixing and channel-mixing MLP that adaptively predicts key parameters of SG-LKF. To enhance inter-frame association and trajectory continuity, we introduce a self-supervised trajectory consistency loss jointly optimized with semantic and positional constraints. Extensive experiments show that SG-LKF ranks first among all vision-based methods on KITTI 2D MOT with 79.59% HOTA, delivers strong results on KITTI 3D MOT with 82.03% HOTA, and outperforms SimpleTrack by 2.2% AMOTA on nuScenes 3D MOT.
GRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
S3MOT: Monocular 3D Object Tracking with Selective State Space Model
Apr 25, 2025Accurate and reliable multi-object tracking (MOT) in 3D space is essential for advancing robotics and computer vision applications. However, it remains a significant challenge in monocular setups due to the difficulty of mining 3D spatiotemporal associations from 2D video streams. In this work, we present three innovative techniques to enhance the fusion and exploitation of heterogeneous cues for monocular 3D MOT: (1) we introduce the Hungarian State Space Model (HSSM), a novel data association mechanism that compresses contextual tracking cues across multiple paths, enabling efficient and comprehensive assignment decisions with linear complexity. HSSM features a global receptive field and dynamic weights, in contrast to traditional linear assignment algorithms that rely on hand-crafted association costs. (2) We propose Fully Convolutional One-stage Embedding (FCOE), which eliminates ROI pooling by directly using dense feature maps for contrastive learning, thus improving object re-identification accuracy under challenging conditions such as varying viewpoints and lighting. (3) We enhance 6-DoF pose estimation through VeloSSM, an encoder-decoder architecture that models temporal dependencies in velocity to capture motion dynamics, overcoming the limitations of frame-based 3D inference. Experiments on the KITTI public test benchmark demonstrate the effectiveness of our method, achieving a new state-of-the-art performance of 76.86~HOTA at 31~FPS. Our approach outperforms the previous best by significant margins of +2.63~HOTA and +3.62~AssA, showcasing its robustness and efficiency for monocular 3D MOT tasks. The code and models are available at https://github.com/bytepioneerX/s3mot.
How good are deep learning methods for automated road safety analysis using video data? An experimental study
Mar 12, 2025Image-based multi-object detection (MOD) and multi-object tracking (MOT) are advancing at a fast pace. A variety of 2D and 3D MOD and MOT methods have been developed for monocular and stereo cameras. Road safety analysis can benefit from those advancements. As crashes are rare events, surrogate measures of safety (SMoS) have been developed for safety analyses. (Semi-)Automated safety analysis methods extract road user trajectories to compute safety indicators, for example, Time-to-Collision (TTC) and Post-encroachment Time (PET). Inspired by the success of deep learning in MOD and MOT, we investigate three MOT methods, including one based on a stereo-camera, using the annotated KITTI traffic video dataset. Two post-processing steps, IDsplit and SS, are developed to improve the tracking results and investigate the factors influencing the TTC. The experimental results show that, despite some advantages in terms of the numbers of interactions or similarity to the TTC distributions, all the tested methods systematically over-estimate the number of interactions and under-estimate the TTC: they report more interactions and more severe interactions, making the road user interactions appear less safe than they are. Further efforts will be directed towards testing more methods and more data, in particular from roadside sensors, to verify the results and improve the performance.
CAMOT: Camera Angle-aware Multi-Object Tracking
Sep 26, 2024
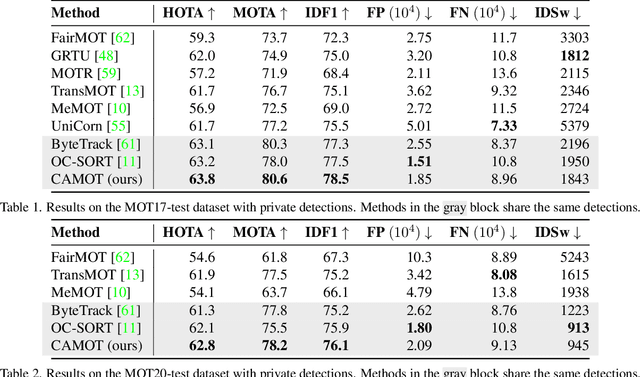


This paper proposes CAMOT, a simple camera angle estimator for multi-object tracking to tackle two problems: 1) occlusion and 2) inaccurate distance estimation in the depth direction. Under the assumption that multiple objects are located on a flat plane in each video frame, CAMOT estimates the camera angle using object detection. In addition, it gives the depth of each object, enabling pseudo-3D MOT. We evaluated its performance by adding it to various 2D MOT methods on the MOT17 and MOT20 datasets and confirmed its effectiveness. Applying CAMOT to ByteTrack, we obtained 63.8% HOTA, 80.6% MOTA, and 78.5% IDF1 in MOT17, which are state-of-the-art results. Its computational cost is significantly lower than the existing deep-learning-based depth estimators for tracking.
BEV-SUSHI: Multi-Target Multi-Camera 3D Detection and Tracking in Bird's-Eye View
Dec 01, 2024



Object perception from multi-view cameras is crucial for intelligent systems, particularly in indoor environments, e.g., warehouses, retail stores, and hospitals. Most traditional multi-target multi-camera (MTMC) detection and tracking methods rely on 2D object detection, single-view multi-object tracking (MOT), and cross-view re-identification (ReID) techniques, without properly handling important 3D information by multi-view image aggregation. In this paper, we propose a 3D object detection and tracking framework, named BEV-SUSHI, which first aggregates multi-view images with necessary camera calibration parameters to obtain 3D object detections in bird's-eye view (BEV). Then, we introduce hierarchical graph neural networks (GNNs) to track these 3D detections in BEV for MTMC tracking results. Unlike existing methods, BEV-SUSHI has impressive generalizability across different scenes and diverse camera settings, with exceptional capability for long-term association handling. As a result, our proposed BEV-SUSHI establishes the new state-of-the-art on the AICity'24 dataset with 81.22 HOTA, and 95.6 IDF1 on the WildTrack dataset.
PD-SORT: Occlusion-Robust Multi-Object Tracking Using Pseudo-Depth Cues
Jan 20, 2025



Multi-object tracking (MOT) is a rising topic in video processing technologies and has important application value in consumer electronics. Currently, tracking-by-detection (TBD) is the dominant paradigm for MOT, which performs target detection and association frame by frame. However, the association performance of TBD methods degrades in complex scenes with heavy occlusions, which hinders the application of such methods in real-world scenarios.To this end, we incorporate pseudo-depth cues to enhance the association performance and propose Pseudo-Depth SORT (PD-SORT). First, we extend the Kalman filter state vector with pseudo-depth states. Second, we introduce a novel depth volume IoU (DVIoU) by combining the conventional 2D IoU with pseudo-depth. Furthermore, we develop a quantized pseudo-depth measurement (QPDM) strategy for more robust data association. Besides, we also integrate camera motion compensation (CMC) to handle dynamic camera situations. With the above designs, PD-SORT significantly alleviates the occlusion-induced ambiguous associations and achieves leading performances on DanceTrack, MOT17, and MOT20. Note that the improvement is especially obvious on DanceTrack, where objects show complex motions, similar appearances, and frequent occlusions. The code is available at https://github.com/Wangyc2000/PD_SORT.
Track Initialization and Re-Identification for~3D Multi-View Multi-Object Tracking
May 28, 2024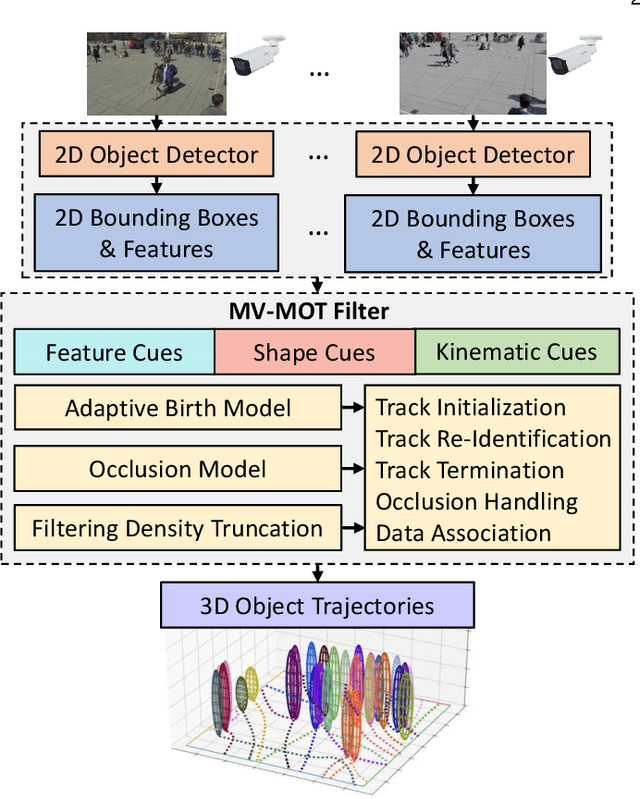

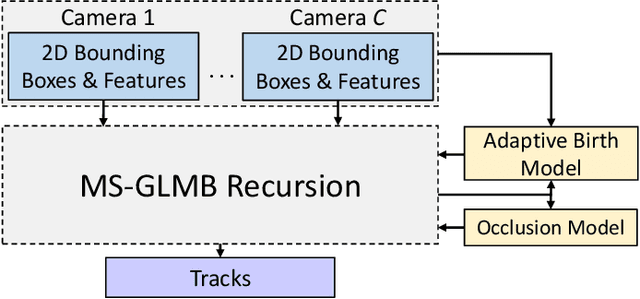

We propose a 3D multi-object tracking (MOT) solution using only 2D detections from monocular cameras, which automatically initiates/terminates tracks as well as resolves track appearance-reappearance and occlusions. Moreover, this approach does not require detector retraining when cameras are reconfigured but only the camera matrices of reconfigured cameras need to be updated. Our approach is based on a Bayesian multi-object formulation that integrates track initiation/termination, re-identification, occlusion handling, and data association into a single Bayes filtering recursion. However, the exact filter that utilizes all these functionalities is numerically intractable due to the exponentially growing number of terms in the (multi-object) filtering density, while existing approximations trade-off some of these functionalities for speed. To this end, we develop a more efficient approximation suitable for online MOT by incorporating object features and kinematics into the measurement model, which improves data association and subsequently reduces the number of terms. Specifically, we exploit the 2D detections and extracted features from multiple cameras to provide a better approximation of the multi-object filtering density to realize the track initiation/termination and re-identification functionalities. Further, incorporating a tractable geometric occlusion model based on 2D projections of 3D objects on the camera planes realizes the occlusion handling functionality of the filter. Evaluation of the proposed solution on challenging datasets demonstrates significant improvements and robustness when camera configurations change on-the-fly, compared to existing multi-view MOT solutions. The source code is publicly available at https://github.com/linh-gist/mv-glmb-ab.
BiTrack: Bidirectional Offline 3D Multi-Object Tracking Using Camera-LiDAR Data
Jun 26, 2024



Compared with real-time multi-object tracking (MOT), offline multi-object tracking (OMOT) has the advantages to perform 2D-3D detection fusion, erroneous link correction, and full track optimization but has to deal with the challenges from bounding box misalignment and track evaluation, editing, and refinement. This paper proposes "BiTrack", a 3D OMOT framework that includes modules of 2D-3D detection fusion, initial trajectory generation, and bidirectional trajectory re-optimization to achieve optimal tracking results from camera-LiDAR data. The novelty of this paper includes threefold: (1) development of a point-level object registration technique that employs a density-based similarity metric to achieve accurate fusion of 2D-3D detection results; (2) development of a set of data association and track management skills that utilizes a vertex-based similarity metric as well as false alarm rejection and track recovery mechanisms to generate reliable bidirectional object trajectories; (3) development of a trajectory re-optimization scheme that re-organizes track fragments of different fidelities in a greedy fashion, as well as refines each trajectory with completion and smoothing techniques. The experiment results on the KITTI dataset demonstrate that BiTrack achieves the state-of-the-art performance for 3D OMOT tasks in terms of accuracy and efficiency.
UncertaintyTrack: Exploiting Detection and Localization Uncertainty in Multi-Object Tracking
Feb 19, 2024Multi-object tracking (MOT) methods have seen a significant boost in performance recently, due to strong interest from the research community and steadily improving object detection methods. The majority of tracking methods follow the tracking-by-detection (TBD) paradigm, blindly trust the incoming detections with no sense of their associated localization uncertainty. This lack of uncertainty awareness poses a problem in safety-critical tasks such as autonomous driving where passengers could be put at risk due to erroneous detections that have propagated to downstream tasks, including MOT. While there are existing works in probabilistic object detection that predict the localization uncertainty around the boxes, no work in 2D MOT for autonomous driving has studied whether these estimates are meaningful enough to be leveraged effectively in object tracking. We introduce UncertaintyTrack, a collection of extensions that can be applied to multiple TBD trackers to account for localization uncertainty estimates from probabilistic object detectors. Experiments on the Berkeley Deep Drive MOT dataset show that the combination of our method and informative uncertainty estimates reduces the number of ID switches by around 19\% and improves mMOTA by 2-3%. The source code is available at https://github.com/TRAILab/UncertaintyTrack