 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Spotting
Text spotting is the combination of Scene Text Detection and Scene Text Recognition in an end-to-end manner. It is the ability to read natural text in the wild.
Papers and Code
TiCLS : Tightly Coupled Language Text Spotter
Feb 03, 2026Scene text spotting aims to detect and recognize text in real-world images, where instances are often short, fragmented, or visually ambiguous. Existing methods primarily rely on visual cues and implicitly capture local character dependencies, but they overlook the benefits of external linguistic knowledge. Prior attempts to integrate language models either adapt language modeling objectives without external knowledge or apply pretrained models that are misaligned with the word-level granularity of scene text. We propose TiCLS, an end-to-end text spotter that explicitly incorporates external linguistic knowledge from a character-level pretrained language model. TiCLS introduces a linguistic decoder that fuses visual and linguistic features, yet can be initialized by a pretrained language model, enabling robust recognition of ambiguous or fragmented text. Experiments on ICDAR 2015 and Total-Text demonstrate that TiCLS achieves state-of-the-art performance, validating the effectiveness of PLM-guided linguistic integration for scene text spotting.
ReCALL: Recalibrating Capability Degradation for MLLM-based Composed Image Retrieval
Feb 02, 2026Composed Image Retrieval (CIR) aims to retrieve target images based on a hybrid query comprising a reference image and a modification text. Early dual-tower Vision-Language Models (VLMs) struggle with cross-modality compositional reasoning required for this task. Recently, adapting generative Multimodal Large Language Models (MLLMs) for retrieval offers a promising direction. However, we identify that this adaptation strategy overlooks a fundamental issue: adapting a generative MLLM into a single-embedding discriminative retriever triggers a paradigm conflict, which leads to Capability Degradation - the deterioration of native fine-grained reasoning after retrieval adaptation. To address this challenge, we propose ReCALL (Recalibrating Capability Degradation), a model-agnostic framework that follows a diagnose-generate-refine pipeline: Firstly, we diagnose cognitive blind spots of the retriever via self-guided informative instance mining. Next, we generate corrective instructions and triplets by CoT prompting the foundation MLLM and conduct quality control with VQA-based consistency filtering. Finally, we refine the retriever through continual training on these triplets with a grouped contrastive scheme, thereby internalizing fine-grained visual-semantic distinctions and realigning the discriminative embedding space of retriever with intrinsic compositional reasoning within the MLLM. Extensive experiments on CIRR and FashionIQ show that ReCALL consistently recalibrates degraded capabilities and achieves state-of-the-art performance. Code will be released soon.
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Jan 29, 2026We introduce PaddleOCR-VL-1.5, an upgraded model achieving a new state-of-the-art (SOTA) accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions, including scanning, skew, warping, screen-photography, and illumination, we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model's capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency. Code: https://github.com/PaddlePaddle/PaddleOCR
MATE: Matryoshka Audio-Text Embeddings for Open-Vocabulary Keyword Spotting
Jan 20, 2026Open-vocabulary keyword spotting (KWS) with text-based enrollment has emerged as a flexible alternative to fixed-phrase triggers. Prior utterance-level matching methods, from an embedding-learning standpoint, learn embeddings at a single fixed dimensionality. We depart from this design and propose Matryoshka Audio-Text Embeddings (MATE), a dual-encoder framework that encodes multiple embedding granularities within a single vector via nested sub-embeddings ("prefixes"). Specifically, we introduce a PCA-guided prefix alignment: PCA-compressed versions of the full text embedding for each prefix size serve as teacher targets to align both audio and text prefixes. This alignment concentrates salient keyword cues in lower-dimensional prefixes, while higher dimensions add detail. MATE is trained with standard deep metric learning objectives for audio-text KWS, and is loss-agnostic. To our knowledge, this is the first application of matryoshka-style embeddings to KWS, achieving state-of-the-art results on WSJ and LibriPhrase without any inference overhead.
Unified Diffusion Transformer for High-fidelity Text-Aware Image Restoration
Dec 09, 2025Text-Aware Image Restoration (TAIR) aims to recover high-quality images from low-quality inputs containing degraded textual content. While diffusion models provide strong generative priors for general image restoration, they often produce text hallucinations in text-centric tasks due to the absence of explicit linguistic knowledge. To address this, we propose UniT, a unified text restoration framework that integrates a Diffusion Transformer (DiT), a Vision-Language Model (VLM), and a Text Spotting Module (TSM) in an iterative fashion for high-fidelity text restoration. In UniT, the VLM extracts textual content from degraded images to provide explicit textual guidance. Simultaneously, the TSM, trained on diffusion features, generates intermediate OCR predictions at each denoising step, enabling the VLM to iteratively refine its guidance during the denoising process. Finally, the DiT backbone, leveraging its strong representational power, exploit these cues to recover fine-grained textual content while effectively suppressing text hallucinations. Experiments on the SA-Text and Real-Text benchmarks demonstrate that UniT faithfully reconstructs degraded text, substantially reduces hallucinations, and achieves state-of-the-art end-to-end F1-score performance in TAIR task.
Joint Multimodal Contrastive Learning for Robust Spoken Term Detection and Keyword Spotting
Dec 16, 2025



Acoustic Word Embeddings (AWEs) improve the efficiency of speech retrieval tasks such as Spoken Term Detection (STD) and Keyword Spotting (KWS). However, existing approaches suffer from limitations, including unimodal supervision, disjoint optimization of audio-audio and audio-text alignment, and the need for task-specific models. To address these shortcomings, we propose a joint multimodal contrastive learning framework that unifies both acoustic and cross-modal supervision in a shared embedding space. Our approach simultaneously optimizes: (i) audio-text contrastive learning, inspired by the CLAP loss, to align audio and text representations and (ii) audio-audio contrastive learning, via Deep Word Discrimination (DWD) loss, to enhance intra-class compactness and inter-class separation. The proposed method outperforms existing AWE baselines on word discrimination task while flexibly supporting both STD and KWS. To our knowledge, this is the first comprehensive approach of its kind.
Prime and Reach: Synthesising Body Motion for Gaze-Primed Object Reach
Dec 18, 2025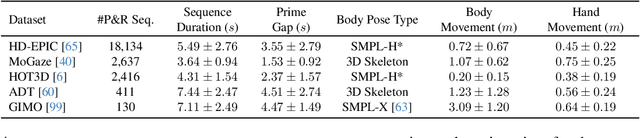



Human motion generation is a challenging task that aims to create realistic motion imitating natural human behaviour. We focus on the well-studied behaviour of priming an object/location for pick up or put down -- that is, the spotting of an object/location from a distance, known as gaze priming, followed by the motion of approaching and reaching the target location. To that end, we curate, for the first time, 23.7K gaze-primed human motion sequences for reaching target object locations from five publicly available datasets, i.e., HD-EPIC, MoGaze, HOT3D, ADT, and GIMO. We pre-train a text-conditioned diffusion-based motion generation model, then fine-tune it conditioned on goal pose or location, on our curated sequences. Importantly, we evaluate the ability of the generated motion to imitate natural human movement through several metrics, including the 'Reach Success' and a newly introduced 'Prime Success' metric. On the largest dataset, HD-EPIC, our model achieves 60% prime success and 89% reach success when conditioned on the goal object location.
Pose-Based Sign Language Spotting via an End-to-End Encoder Architecture
Dec 09, 2025Automatic Sign Language Recognition (ASLR) has emerged as a vital field for bridging the gap between deaf and hearing communities. However, the problem of sign-to-sign retrieval or detecting a specific sign within a sequence of continuous signs remains largely unexplored. We define this novel task as Sign Language Spotting. In this paper, we present a first step toward sign language retrieval by addressing the challenge of detecting the presence or absence of a query sign video within a sentence-level gloss or sign video. Unlike conventional approaches that rely on intermediate gloss recognition or text-based matching, we propose an end-to-end model that directly operates on pose keypoints extracted from sign videos. Our architecture employs an encoder-only backbone with a binary classification head to determine whether the query sign appears within the target sequence. By focusing on pose representations instead of raw RGB frames, our method significantly reduces computational cost and mitigates visual noise. We evaluate our approach on the Word Presence Prediction dataset from the WSLP 2025 shared task, achieving 61.88\% accuracy and 60.00\% F1-score. These results demonstrate the effectiveness of our pose-based framework for Sign Language Spotting, establishing a strong foundation for future research in automatic sign language retrieval and verification. Code is available at https://github.com/EbimoJohnny/Pose-Based-Sign-Language-Spotting
Script Gap: Evaluating LLM Triage on Indian Languages in Native vs Roman Scripts in a Real World Setting
Dec 11, 2025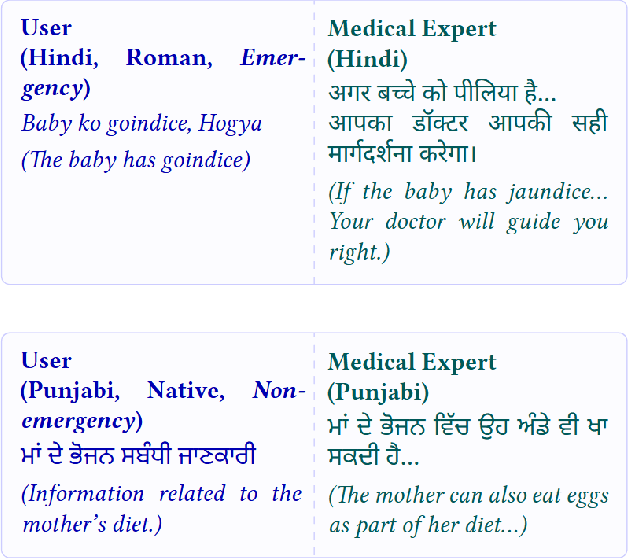
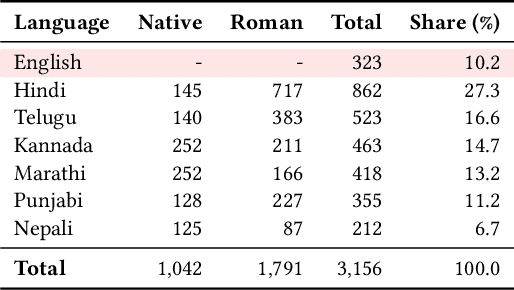


Large Language Models (LLMs) are increasingly deployed in high-stakes clinical applications in India. In many such settings, speakers of Indian languages frequently communicate using romanized text rather than native scripts, yet existing research rarely evaluates this orthographic variation using real-world data. We investigate how romanization impacts the reliability of LLMs in a critical domain: maternal and newborn healthcare triage. We benchmark leading LLMs on a real-world dataset of user-generated queries spanning five Indian languages and Nepali. Our results reveal consistent degradation in performance for romanized messages, with F1 scores trailing those of native scripts by 5-12 points. At our partner maternal health organization in India, this gap could cause nearly 2 million excess errors in triage. Crucially, this performance gap by scripts is not due to a failure in clinical reasoning. We demonstrate that LLMs often correctly infer the semantic intent of romanized queries. Nevertheless, their final classification outputs remain brittle in the presence of orthographic noise in romanized inputs. Our findings highlight a critical safety blind spot in LLM-based health systems: models that appear to understand romanized input may still fail to act on it reliably.
LRANet++: Low-Rank Approximation Network for Accurate and Efficient Text Spotting
Nov 08, 2025End-to-end text spotting aims to jointly optimize text detection and recognition within a unified framework. Despite significant progress, designing an accurate and efficient end-to-end text spotter for arbitrary-shaped text remains largely unsolved. We identify the primary bottleneck as the lack of a reliable and efficient text detection method. To address this, we propose a novel parameterized text shape method based on low-rank approximation for precise detection and a triple assignment detection head to enable fast inference. Specifically, unlike other shape representation methods that employ data-irrelevant parameterization, our data-driven approach derives a low-rank subspace directly from labeled text boundaries. To ensure this process is robust against the inherent annotation noise in this data, we utilize a specialized recovery method based on an $\ell_1$-norm formulation, which accurately reconstructs the text shape with only a few key orthogonal vectors. By exploiting the inherent shape correlation among different text contours, our method achieves consistency and compactness in shape representation. Next, the triple assignment scheme introduces a novel architecture where a deep sparse branch (for stabilized training) is used to guide the learning of an ultra-lightweight sparse branch (for accelerated inference), while a dense branch provides rich parallel supervision. Building upon these advancements, we integrate the enhanced detection module with a lightweight recognition branch to form an end-to-end text spotting framework, termed LRANet++, capable of accurately and efficiently spotting arbitrary-shaped text. Extensive experiments on several challenging benchmarks demonstrate the superiority of LRANet++ compared to state-of-the-art methods. Code will be available at: https://github.com/ychensu/LRANet-PP.git