 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURE:Circuit-Aware Unlearning for LLM-based Recommendation
Apr 04, 2026Recent advances in large language models (LLMs) have opened new opportunities for recommender systems by enabling rich semantic understanding and reasoning about user interests and item attributes. However, as privacy regulations tighten, incorporating user data into LLM-based recommendation (LLMRec) introduces significant privacy risks, making unlearning algorithms increasingly crucial for practical deployment. Despite growing interest in LLMRec unlearning, most existing approaches formulate unlearning as a weighted combination of forgetting and retaining objectives while updating model parameters in a uniform manner. Such formulations inevitably induce gradient conflicts between the two objectives, leading to unstable optimization and resulting in either ineffective unlearning or severe degradation of model utility. Moreover, the unlearning procedure remains largely black-box, undermining its transparency and trustworthiness. To tackle these challenges, we propose CURE, a circuit-aware unlearning framework that disentangles model components into functionally distinct subsets and selectively updates them. Here, a circuit refers to a computational subgraph that is causally responsible for task-specific behaviors. Specifically, we extract the core circuits underlying item recommendation and analyze how individual modules within these circuits contribute to the forget and retain objectives. Based on this analysis, these modules are categorized into forget-specific, retain-specific, and task-shared groups, each subject to function-specific update rules to mitigate gradient conflicts during unlearning. Experiments on real-world datasets show that our approach achieves more effective unlearning than existing baselines.
Linguistic Blind Spots in Clinical Decision Extraction
Feb 03, 2026Extracting medical decisions from clinical notes is a key step for clinical decision support and patient-facing care summaries. We study how the linguistic characteristics of clinical decisions vary across decision categories and whether these differences explain extraction failures. Using MedDec discharge summaries annotated with decision categories from the Decision Identification and Classification Taxonomy for Use in Medicine (DICTUM), we compute seven linguistic indices for each decision span and analyze span-level extraction recall of a standard transformer model. We find clear category-specific signatures: drug-related and problem-defining decisions are entity-dense and telegraphic, whereas advice and precaution decisions contain more narrative, with higher stopword and pronoun proportions and more frequent hedging and negation cues. On the validation split, exact-match recall is 48%, with large gaps across linguistic strata: recall drops from 58% to 24% from the lowest to highest stopword-proportion bins, and spans containing hedging or negation cues are less likely to be recovered. Under a relaxed overlap-based match criterion, recall increases to 71%, indicating that many errors are span boundary disagreements rather than complete misses. Overall, narrative-style spans--common in advice and precaution decisions--are a consistent blind spot under exact matching, suggesting that downstream systems should incorporate boundary-tolerant evaluation and extraction strategies for clinical decisions.
Curriculum Learning for LLM Pretraining: An Analysis of Learning Dynamics
Jan 29, 2026Curriculum learning changes the order of pre-training data, but it remains unclear whether it changes the learning trajectory or mainly reorders exposure over a fixed trajectory. We train Pythia models (14M-410M parameters) for 300B tokens under three linguistically motivated curricula-Age-of-Acquisition, word frequency, and Verb Variation (VV)-and compare each against Random ordering; at 1B parameters we compare Random and VV. Across orderings, training follows a shared sequence of latent phases, while curricula mainly change within-phase data exposure. In smaller models (up to 160M parameters), Random ordering exhibits higher gradient noise and stronger late-training output-head spectral saturation, alongside lower final accuracy; curricula reduce both effects at matched compute. At larger scales, saturation differences are smaller and curriculum gains shrink. We formalize the link between difficulty pacing and optimization stability in an idealized analysis based on gradient-variance control, and our results point to a practical takeaway: curricula help by stabilizing within-phase optimization rather than by creating new phases.
Toward Understanding Unlearning Difficulty: A Mechanistic Perspective and Circuit-Guided Difficulty Metric
Jan 14, 2026Machine unlearning is becoming essential for building trustworthy and compliant language models. Yet unlearning success varies considerably across individual samples: some are reliably erased, while others persist despite the same procedure. We argue that this disparity is not only a data-side phenomenon, but also reflects model-internal mechanisms that encode and protect memorized information. We study this problem from a mechanistic perspective based on model circuits--structured interaction pathways that govern how predictions are formed. We propose Circuit-guided Unlearning Difficulty (CUD), a {\em pre-unlearning} metric that assigns each sample a continuous difficulty score using circuit-level signals. Extensive experiments demonstrate that CUD reliably separates intrinsically easy and hard samples, and remains stable across unlearning methods. We identify key circuit-level patterns that reveal a mechanistic signature of difficulty: easy-to-unlearn samples are associated with shorter, shallower interactions concentrated in earlier-to-intermediate parts of the original model, whereas hard samples rely on longer and deeper pathways closer to late-stage computation. Compared to existing qualitative studies, CUD takes a first step toward a principled, fine-grained, and interpretable analysis of unlearning difficulty; and motivates the development of unlearning methods grounded in model mechanisms.
Investigating Tool-Memory Conflicts in Tool-Augmented LLMs
Jan 14, 2026Tool-augmented large language models (LLMs) have powered many applications. However, they are likely to suffer from knowledge conflict. In this paper, we propose a new type of knowledge conflict -- Tool-Memory Conflict (TMC), where the internal parametric knowledge contradicts with the external tool knowledge for tool-augmented LLMs. We find that existing LLMs, though powerful, suffer from TMC, especially on STEM-related tasks. We also uncover that under different conditions, tool knowledge and parametric knowledge may be prioritized differently. We then evaluate existing conflict resolving techniques, including prompting-based and RAG-based methods. Results show that none of these approaches can effectively resolve tool-memory conflicts.
Do Students Debias Like Teachers? On the Distillability of Bias Mitigation Methods
Oct 30, 2025Knowledge distillation (KD) is an effective method for model compression and transferring knowledge between models. However, its effect on model's robustness against spurious correlations that degrade performance on out-of-distribution data remains underexplored. This study investigates the effect of knowledge distillation on the transferability of ``debiasing'' capabilities from teacher models to student models on natural language inference (NLI) and image classification tasks. Through extensive experiments, we illustrate several key findings: (i) overall the debiasing capability of a model is undermined post-KD; (ii) training a debiased model does not benefit from injecting teacher knowledge; (iii) although the overall robustness of a model may remain stable post-distillation, significant variations can occur across different types of biases; and (iv) we pin-point the internal attention pattern and circuit that causes the distinct behavior post-KD. Given the above findings, we propose three effective solutions to improve the distillability of debiasing methods: developing high quality data for augmentation, implementing iterative knowledge distillation, and initializing student models with weights obtained from teacher models. To the best of our knowledge, this is the first study on the effect of KD on debiasing and its interenal mechanism at scale. Our findings provide understandings on how KD works and how to design better debiasing methods.
ATLAS: Actor-Critic Task-Completion with Look-ahead Action Simulation
Oct 26, 2025We observe that current state-of-the-art web-agents are unable to effectively adapt to new environments without neural network fine-tuning, without which they produce inefficient execution plans due to a lack of awareness of the structure and dynamics of the new environment. To address this limitation, we introduce ATLAS (Actor-Critic Task-completion with Look-ahead Action Simulation), a memory-augmented agent that is able to make plans grounded in a model of the environment by simulating the consequences of those actions in cognitive space. Our agent starts by building a "cognitive map" by performing a lightweight curiosity driven exploration of the environment. The planner proposes candidate actions; the simulator predicts their consequences in cognitive space; a critic analyzes the options to select the best roll-out and update the original plan; and a browser executor performs the chosen action. On the WebArena-Lite Benchmark, we achieve a 63% success rate compared to 53.9% success rate for the previously published state-of-the-art. Unlike previous systems, our modular architecture requires no website-specific LLM fine-tuning. Ablations show sizable drops without the world-model, hierarchical planner, and look-ahead-based replanner confirming their complementary roles within the design of our system
FUTURE: Flexible Unlearning for Tree Ensemble
Aug 28, 2025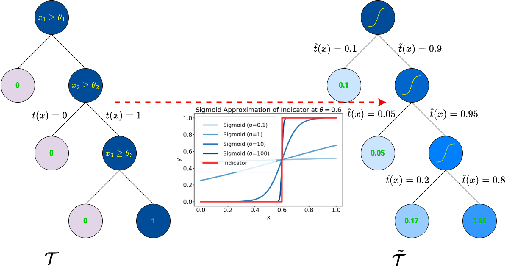
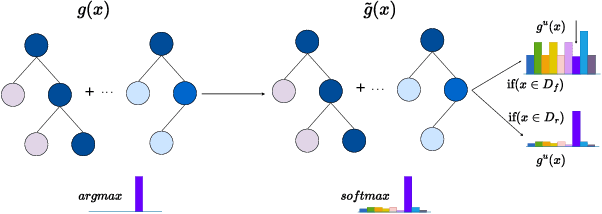
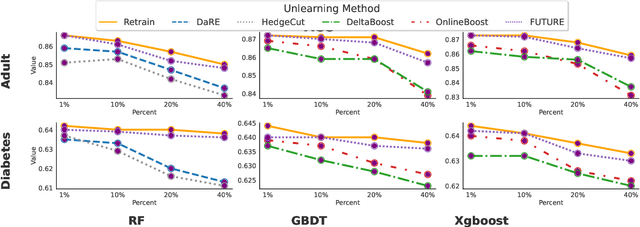
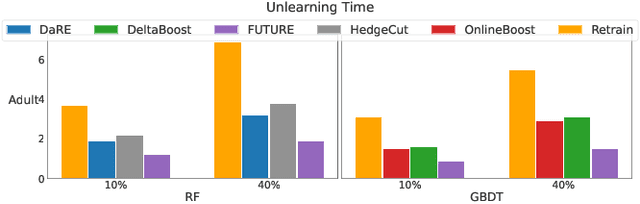
Tree ensembles are widely recognized for their effectiveness in classification tasks, achieving state-of-the-art performance across diverse domains, including bioinformatics, finance, and medical diagnosis. With increasing emphasis on data privacy and the \textit{right to be forgotten}, several unlearning algorithms have been proposed to enable tree ensembles to forget sensitive information. However, existing methods are often tailored to a particular model or rely on the discrete tree structure, making them difficult to generalize to complex ensembles and inefficient for large-scale datasets. To address these limitations, we propose FUTURE, a novel unlearning algorithm for tree ensembles. Specifically, we formulate the problem of forgetting samples as a gradient-based optimization task. In order to accommodate non-differentiability of tree ensembles, we adopt the probabilistic model approximations within the optimization framework. This enables end-to-end unlearning in an effective and efficient manner. Extensive experiments on real-world datasets show that FUTURE yields significant and successful unlearning performance.
Understanding Machine Unlearning Through the Lens of Mode Connectivity
Apr 08, 2025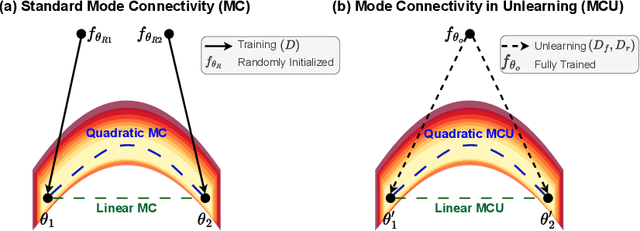
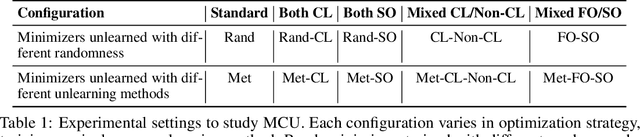
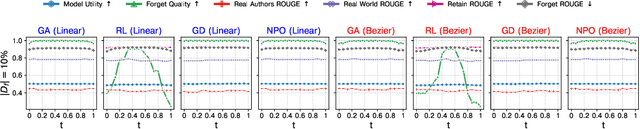
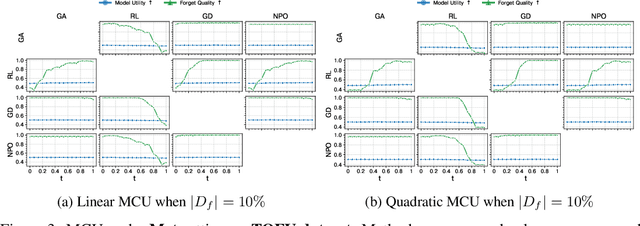
Machine Unlearning aims to remove undesired information from trained models without requiring full retraining from scratch. Despite recent advancements, their underlying loss landscapes and optimization dynamics received less attention. In this paper, we investigate and analyze machine unlearning through the lens of mode connectivity - the phenomenon where independently trained models can be connected by smooth low-loss paths in the parameter space. We define and study mode connectivity in unlearning across a range of overlooked conditions, including connections between different unlearning methods, models trained with and without curriculum learning, and models optimized with first-order and secondorder techniques. Our findings show distinct patterns of fluctuation of different evaluation metrics along the curve, as well as the mechanistic (dis)similarity between unlearning methods. To the best of our knowledge, this is the first study on mode connectivity in the context of machine unlearning.
Linguistic Blind Spots of Large Language Models
Mar 25, 2025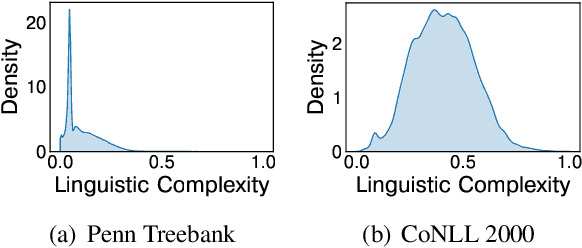
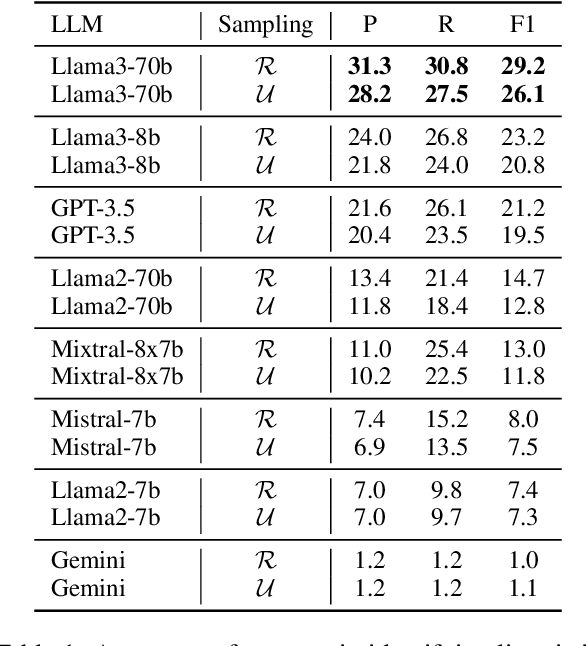
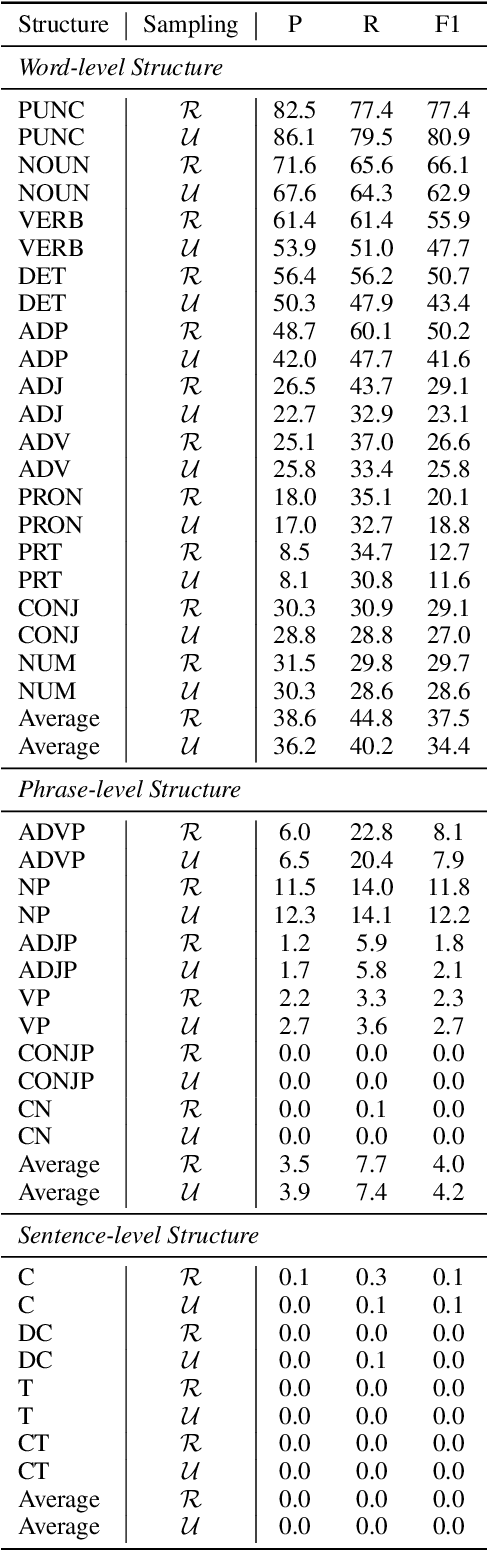
Large language models (LLMs) are the foundation of many AI applications today. However, despite their remarkable proficiency in generating coherent text, questions linger regarding their ability to perform fine-grained linguistic annotation tasks, such as detecting nouns or verbs, or identifying more complex syntactic structures like clauses in input texts. These tasks require precise syntactic and semantic understanding of input text, and when LLMs underperform on specific linguistic structures, it raises concerns about their reliability for detailed linguistic analysis and whether their (even correct) outputs truly reflect an understanding of the inputs. In this paper, we empirically study the performance of recent LLMs on fine-grained linguistic annotation tasks. Through a series of experiments, we find that recent LLMs show limited efficacy in addressing linguistic queries and often struggle with linguistically complex inputs. We show that the most capable LLM (Llama3-70b) makes notable errors in detecting linguistic structures, such as misidentifying embedded clauses, failing to recognize verb phrases, and confusing complex nominals with clauses. Our results provide insights to inform future advancements in LLM design and development.
* NAACL 2025 Cognitive Modeling and Computational Linguistics Workshop