 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Graph Generation through Latent Mixture Scheduling
May 04, 2026Structure aware graph generation aims to generate graphs that satisfy given topological properties. It has applications in domains such as drug discovery, social network modeling, and knowledge graph construction. Unlike existing methods that only provide coarse control over graph properties, we introduce a novel conditional variational autoencoder for fine-grained structural control in graph generation. The approach refines the decoder's latent space by dynamically aligning graph- and property-driven representations to improve both graph fidelity and control satisfaction. Specifically, the approach implements a mixture scheduler that progressively integrates graph and control priors. Experiments on five real-world datasets show the efficacy of the proposed model compared to recent baselines, achieving high generation quality while maintaining high controllability.
MedDec: A Dataset for Extracting Medical Decisions from Discharge Summaries
Aug 23, 2024
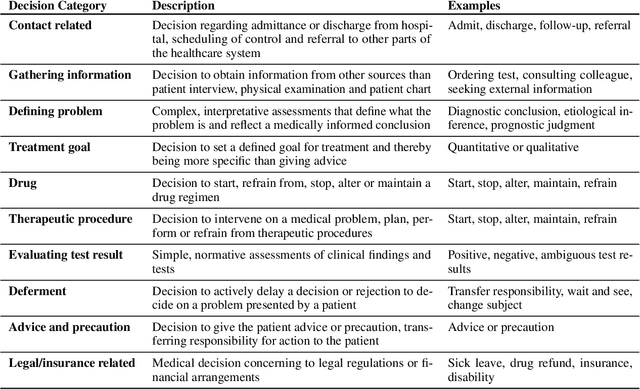
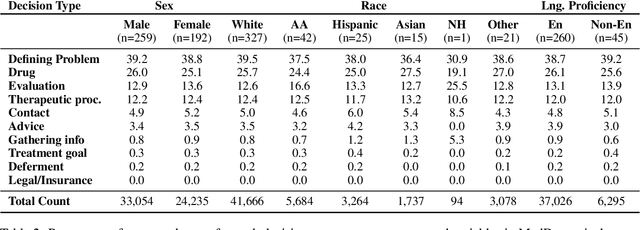
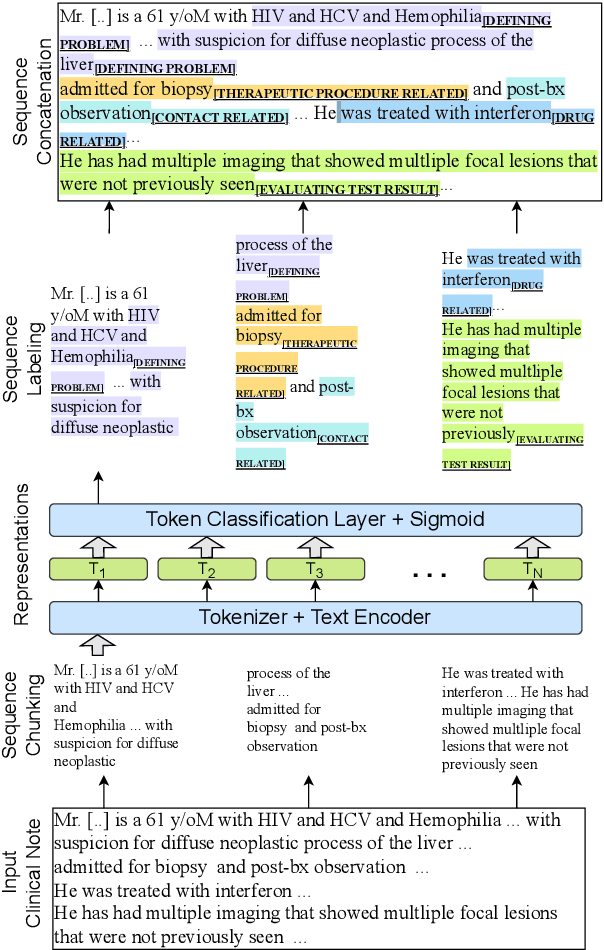
Medical decisions directly impact individuals' health and well-being. Extracting decision spans from clinical notes plays a crucial role in understanding medical decision-making processes. In this paper, we develop a new dataset called "MedDec", which contains clinical notes of eleven different phenotypes (diseases) annotated by ten types of medical decisions. We introduce the task of medical decision extraction, aiming to jointly extract and classify different types of medical decisions within clinical notes. We provide a comprehensive analysis of the dataset, develop a span detection model as a baseline for this task, evaluate recent span detection approaches, and employ a few metrics to measure the complexity of data samples. Our findings shed light on the complexities inherent in clinical decision extraction and enable future work in this area of research. The dataset and code are available through https://github.com/CLU-UML/MedDec.
CogniVoice: Multimodal and Multilingual Fusion Networks for Mild Cognitive Impairment Assessment from Spontaneous Speech
Jul 18, 2024Mild Cognitive Impairment (MCI) is a medical condition characterized by noticeable declines in memory and cognitive abilities, potentially affecting individual's daily activities. In this paper, we introduce CogniVoice, a novel multilingual and multimodal framework to detect MCI and estimate Mini-Mental State Examination (MMSE) scores by analyzing speech data and its textual transcriptions. The key component of CogniVoice is an ensemble multimodal and multilingual network based on ``Product of Experts'' that mitigates reliance on shortcut solutions. Using a comprehensive dataset containing both English and Chinese languages from TAUKADIAL challenge, CogniVoice outperforms the best performing baseline model on MCI classification and MMSE regression tasks by 2.8 and 4.1 points in F1 and RMSE respectively, and can effectively reduce the performance gap across different language groups by 0.7 points in F1.
Complexity-Guided Curriculum Learning for Text Graphs
Nov 22, 2023Curriculum learning provides a systematic approach to training. It refines training progressively, tailors training to task requirements, and improves generalization through exposure to diverse examples. We present a curriculum learning approach that builds on existing knowledge about text and graph complexity formalisms for training with text graph data. The core part of our approach is a novel data scheduler, which employs "spaced repetition" and complexity formalisms to guide the training process. We demonstrate the effectiveness of the proposed approach on several text graph tasks and graph neural network architectures. The proposed model gains more and uses less data; consistently prefers text over graph complexity indices throughout training, while the best curricula derived from text and graph complexity indices are equally effective; and it learns transferable curricula across GNN models and datasets. In addition, we find that both node-level (local) and graph-level (global) graph complexity indices, as well as shallow and traditional text complexity indices play a crucial role in effective curriculum learning.
Curriculum Learning for Graph Neural Networks: A Multiview Competence-based Approach
Jul 17, 2023A curriculum is a planned sequence of learning materials and an effective one can make learning efficient and effective for both humans and machines. Recent studies developed effective data-driven curriculum learning approaches for training graph neural networks in language applications. However, existing curriculum learning approaches often employ a single criterion of difficulty in their training paradigms. In this paper, we propose a new perspective on curriculum learning by introducing a novel approach that builds on graph complexity formalisms (as difficulty criteria) and model competence during training. The model consists of a scheduling scheme which derives effective curricula by accounting for different views of sample difficulty and model competence during training. The proposed solution advances existing research in curriculum learning for graph neural networks with the ability to incorporate a fine-grained spectrum of graph difficulty criteria in their training paradigms. Experimental results on real-world link prediction and node classification tasks illustrate the effectiveness of the proposed approach.
* ACL 2023
Generic and Trend-aware Curriculum Learning for Relation Extraction in Graph Neural Networks
May 17, 2022
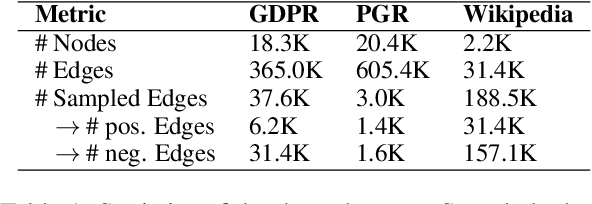
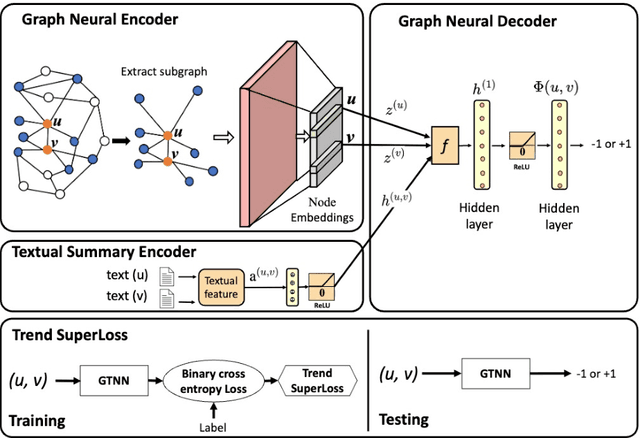
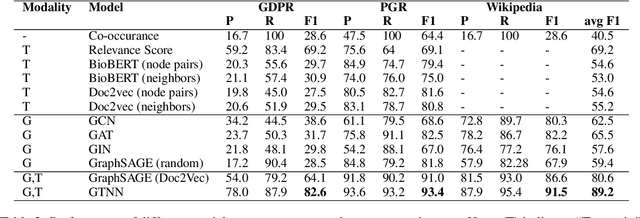
We present a generic and trend-aware curriculum learning approach for graph neural networks. It extends existing approaches by incorporating sample-level loss trends to better discriminate easier from harder samples and schedule them for training. The model effectively integrates textual and structural information for relation extraction in text graphs. Experimental results show that the model provides robust estimations of sample difficulty and shows sizable improvement over the state-of-the-art approaches across several datasets.