 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Reenactment
Face reenactment is the process of transferring facial expressions from one person to another in videos.
Papers and Code
SelfieAvatar: Real-time Head Avatar reenactment from a Selfie Video
Jan 26, 2026Head avatar reenactment focuses on creating animatable personal avatars from monocular videos, serving as a foundational element for applications like social signal understanding, gaming, human-machine interaction, and computer vision. Recent advances in 3D Morphable Model (3DMM)-based facial reconstruction methods have achieved remarkable high-fidelity face estimation. However, on the one hand, they struggle to capture the entire head, including non-facial regions and background details in real time, which is an essential aspect for producing realistic, high-fidelity head avatars. On the other hand, recent approaches leveraging generative adversarial networks (GANs) for head avatar generation from videos can achieve high-quality reenactments but encounter limitations in reproducing fine-grained head details, such as wrinkles and hair textures. In addition, existing methods generally rely on a large amount of training data, and rarely focus on using only a simple selfie video to achieve avatar reenactment. To address these challenges, this study introduces a method for detailed head avatar reenactment using a selfie video. The approach combines 3DMMs with a StyleGAN-based generator. A detailed reconstruction model is proposed, incorporating mixed loss functions for foreground reconstruction and avatar image generation during adversarial training to recover high-frequency details. Qualitative and quantitative evaluations on self-reenactment and cross-reenactment tasks demonstrate that the proposed method achieves superior head avatar reconstruction with rich and intricate textures compared to existing approaches.
DeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
Improving Generalization in Deepfake Detection with Face Foundation Models and Metric Learning
Aug 27, 2025

The increasing realism and accessibility of deepfakes have raised critical concerns about media authenticity and information integrity. Despite recent advances, deepfake detection models often struggle to generalize beyond their training distributions, particularly when applied to media content found in the wild. In this work, we present a robust video deepfake detection framework with strong generalization that takes advantage of the rich facial representations learned by face foundation models. Our method is built on top of FSFM, a self-supervised model trained on real face data, and is further fine-tuned using an ensemble of deepfake datasets spanning both face-swapping and face-reenactment manipulations. To enhance discriminative power, we incorporate triplet loss variants during training, guiding the model to produce more separable embeddings between real and fake samples. Additionally, we explore attribution-based supervision schemes, where deepfakes are categorized by manipulation type or source dataset, to assess their impact on generalization. Extensive experiments across diverse evaluation benchmarks demonstrate the effectiveness of our approach, especially in challenging real-world scenarios.
Robust Deepfake Detection for Electronic Know Your Customer Systems Using Registered Images
Jul 30, 2025In this paper, we present a deepfake detection algorithm specifically designed for electronic Know Your Customer (eKYC) systems. To ensure the reliability of eKYC systems against deepfake attacks, it is essential to develop a robust deepfake detector capable of identifying both face swapping and face reenactment, while also being robust to image degradation. We address these challenges through three key contributions: (1)~Our approach evaluates the video's authenticity by detecting temporal inconsistencies in identity vectors extracted by face recognition models, leading to comprehensive detection of both face swapping and face reenactment. (2)~In addition to processing video input, the algorithm utilizes a registered image (assumed to be genuine) to calculate identity discrepancies between the input video and the registered image, significantly improving detection accuracy. (3)~We find that employing a face feature extractor trained on a larger dataset enhances both detection performance and robustness against image degradation. Our experimental results show that our proposed method accurately detects both face swapping and face reenactment comprehensively and is robust against various forms of unseen image degradation. Our source code is publicly available https://github.com/TaikiMiyagawa/DeepfakeDetection4eKYC.
Celeb-DF++: A Large-scale Challenging Video DeepFake Benchmark for Generalizable Forensics
Jul 24, 2025The rapid advancement of AI technologies has significantly increased the diversity of DeepFake videos circulating online, posing a pressing challenge for \textit{generalizable forensics}, \ie, detecting a wide range of unseen DeepFake types using a single model. Addressing this challenge requires datasets that are not only large-scale but also rich in forgery diversity. However, most existing datasets, despite their scale, include only a limited variety of forgery types, making them insufficient for developing generalizable detection methods. Therefore, we build upon our earlier Celeb-DF dataset and introduce {Celeb-DF++}, a new large-scale and challenging video DeepFake benchmark dedicated to the generalizable forensics challenge. Celeb-DF++ covers three commonly encountered forgery scenarios: Face-swap (FS), Face-reenactment (FR), and Talking-face (TF). Each scenario contains a substantial number of high-quality forged videos, generated using a total of 22 various recent DeepFake methods. These methods differ in terms of architectures, generation pipelines, and targeted facial regions, covering the most prevalent DeepFake cases witnessed in the wild. We also introduce evaluation protocols for measuring the generalizability of 24 recent detection methods, highlighting the limitations of existing detection methods and the difficulty of our new dataset.
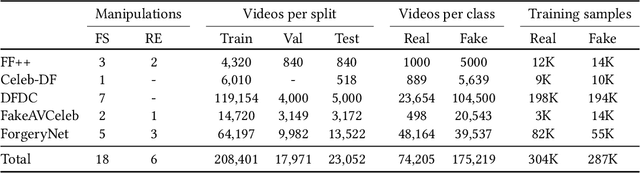
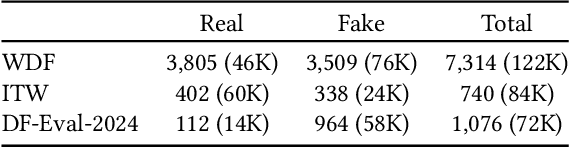
AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Jul 28, 2025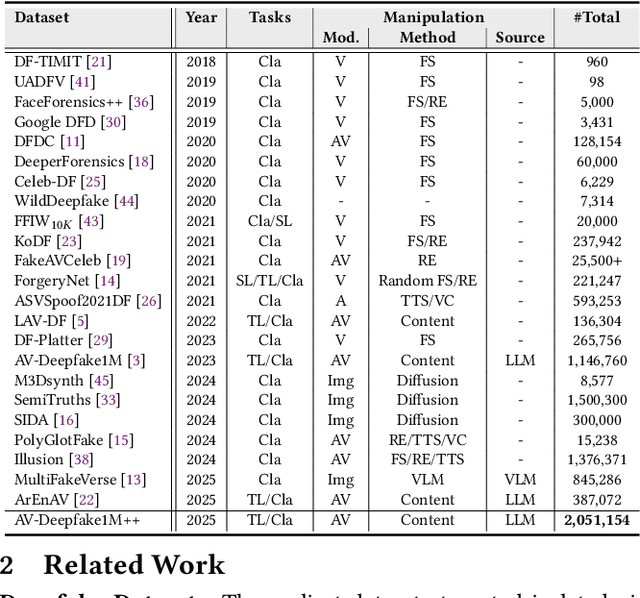
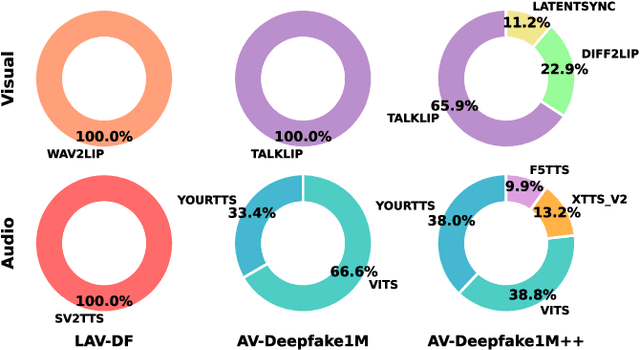
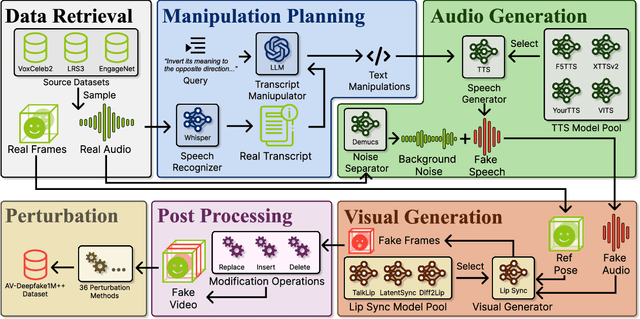
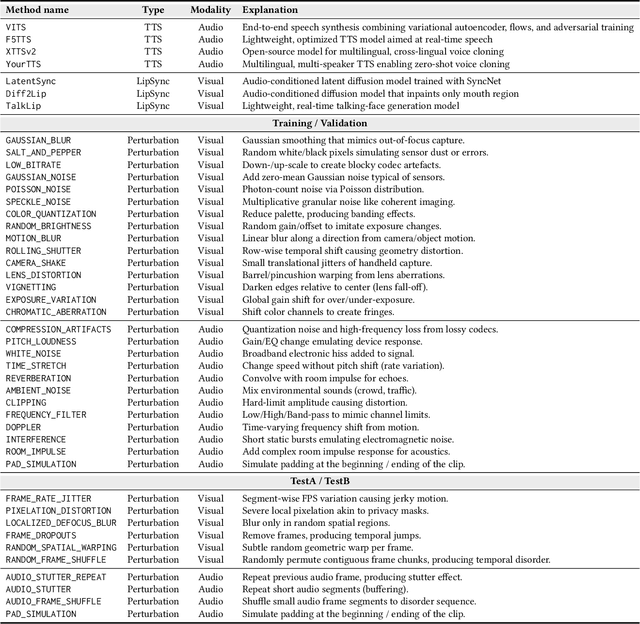
The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
Total-Editing: Head Avatar with Editable Appearance, Motion, and Lighting
May 26, 2025Face reenactment and portrait relighting are essential tasks in portrait editing, yet they are typically addressed independently, without much synergy. Most face reenactment methods prioritize motion control and multiview consistency, while portrait relighting focuses on adjusting shading effects. To take advantage of both geometric consistency and illumination awareness, we introduce Total-Editing, a unified portrait editing framework that enables precise control over appearance, motion, and lighting. Specifically, we design a neural radiance field decoder with intrinsic decomposition capabilities. This allows seamless integration of lighting information from portrait images or HDR environment maps into synthesized portraits. We also incorporate a moving least squares based deformation field to enhance the spatiotemporal coherence of avatar motion and shading effects. With these innovations, our unified framework significantly improves the quality and realism of portrait editing results. Further, the multi-source nature of Total-Editing supports more flexible applications, such as illumination transfer from one portrait to another, or portrait animation with customized backgrounds.
MagicPortrait: Temporally Consistent Face Reenactment with 3D Geometric Guidance
Apr 30, 2025In this paper, we propose a method for video face reenactment that integrates a 3D face parametric model into a latent diffusion framework, aiming to improve shape consistency and motion control in existing video-based face generation approaches. Our approach employs the FLAME (Faces Learned with an Articulated Model and Expressions) model as the 3D face parametric representation, providing a unified framework for modeling face expressions and head pose. This enables precise extraction of detailed face geometry and motion features from driving videos. Specifically, we enhance the latent diffusion model with rich 3D expression and detailed pose information by incorporating depth maps, normal maps, and rendering maps derived from FLAME sequences. A multi-layer face movements fusion module with integrated self-attention mechanisms is used to combine identity and motion latent features within the spatial domain. By utilizing the 3D face parametric model as motion guidance, our method enables parametric alignment of face identity between the reference image and the motion captured from the driving video. Experimental results on benchmark datasets show that our method excels at generating high-quality face animations with precise expression and head pose variation modeling. In addition, it demonstrates strong generalization performance on out-of-domain images. Code is publicly available at https://github.com/weimengting/MagicPortrait.
WaveGuard: Robust Deepfake Detection and Source Tracing via Dual-Tree Complex Wavelet and Graph Neural Networks
May 14, 2025Deepfake technology poses increasing risks such as privacy invasion and identity theft. To address these threats, we propose WaveGuard, a proactive watermarking framework that enhances robustness and imperceptibility via frequency-domain embedding and graph-based structural consistency. Specifically, we embed watermarks into high-frequency sub-bands using Dual-Tree Complex Wavelet Transform (DT-CWT) and employ a Structural Consistency Graph Neural Network (SC-GNN) to preserve visual quality. We also design an attention module to refine embedding precision. Experimental results on face swap and reenactment tasks demonstrate that WaveGuard outperforms state-of-the-art methods in both robustness and visual quality. Code is available at https://github.com/vpsg-research/WaveGuard.
BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading
Jun 06, 2025We introduce BecomingLit, a novel method for reconstructing relightable, high-resolution head avatars that can be rendered from novel viewpoints at interactive rates. Therefore, we propose a new low-cost light stage capture setup, tailored specifically towards capturing faces. Using this setup, we collect a novel dataset consisting of diverse multi-view sequences of numerous subjects under varying illumination conditions and facial expressions. By leveraging our new dataset, we introduce a new relightable avatar representation based on 3D Gaussian primitives that we animate with a parametric head model and an expression-dependent dynamics module. We propose a new hybrid neural shading approach, combining a neural diffuse BRDF with an analytical specular term. Our method reconstructs disentangled materials from our dynamic light stage recordings and enables all-frequency relighting of our avatars with both point lights and environment maps. In addition, our avatars can easily be animated and controlled from monocular videos. We validate our approach in extensive experiments on our dataset, where we consistently outperform existing state-of-the-art methods in relighting and reenactment by a significant margin.