 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating and Detecting Various Types of Fake Image and Audio Content: A Review of Modern Deep Learning Technologies and Tools
Jan 07, 2025



This paper reviews the state-of-the-art in deepfake generation and detection, focusing on modern deep learning technologies and tools based on the latest scientific advancements. The rise of deepfakes, leveraging techniques like Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion models and other generative models, presents significant threats to privacy, security, and democracy. This fake media can deceive individuals, discredit real people and organizations, facilitate blackmail, and even threaten the integrity of legal, political, and social systems. Therefore, finding appropriate solutions to counter the potential threats posed by this technology is essential. We explore various deepfake methods, including face swapping, voice conversion, reenactment and lip synchronization, highlighting their applications in both benign and malicious contexts. The review critically examines the ongoing "arms race" between deepfake generation and detection, analyzing the challenges in identifying manipulated contents. By examining current methods and highlighting future research directions, this paper contributes to a crucial understanding of this rapidly evolving field and the urgent need for robust detection strategies to counter the misuse of this powerful technology. While focusing primarily on audio, image, and video domains, this study allows the reader to easily grasp the latest advancements in deepfake generation and detection.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Sep 06, 2021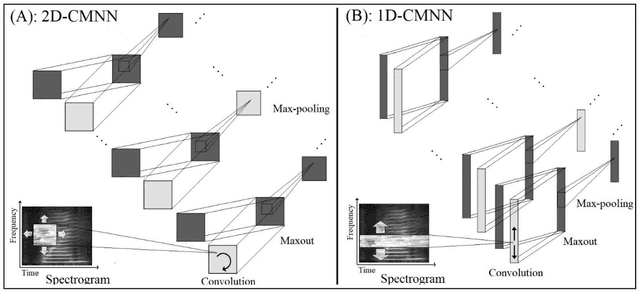
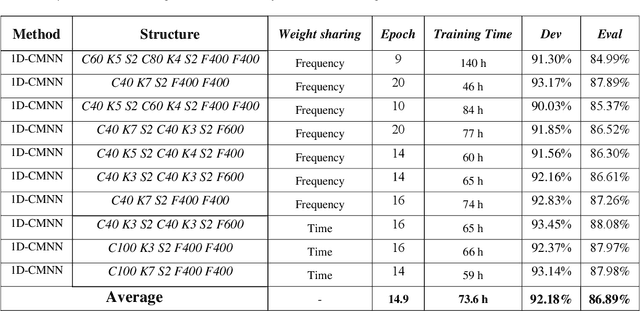
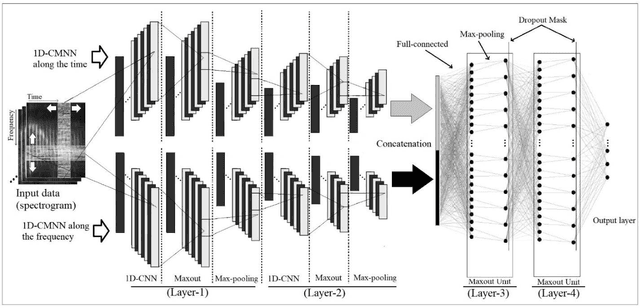
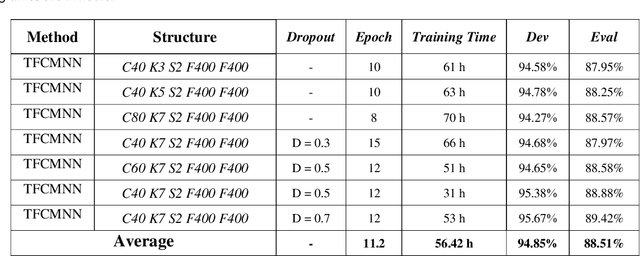
In this paper, a CNN-based structure for time-frequency localization of information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' spectrotemporal plasticity of some neurons in mammals' primary auditory cortex and midbrain makes localization facilities that improve recognition performance. As biosystems have inspired many man-maid systems because of their high efficiency and performance, in the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial or temporal immutability properties of methods such as TDNN, CNN, and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. We have presented a structure called Time-Frequency Convolutional Maxout Neural Network (TFCMNN) in which two parallel time-domain and frequency-domain 1D-CMNN are used. These two blocks are applied simultaneously but independently to the spectrogram, and then their output is concatenated and applied jointly to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as Dropout, maxout, and weight normalization. Two sets of experiments were designed and implemented on the Persian FARSDAT speech dataset to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. Therefore, as proven in other sources, we can say that time-frequency localization in ASR systems increases system accuracy and speeds up the training process.
Performance Evaluation of Deep Convolutional Maxout Neural Network in Speech Recognition
May 04, 2021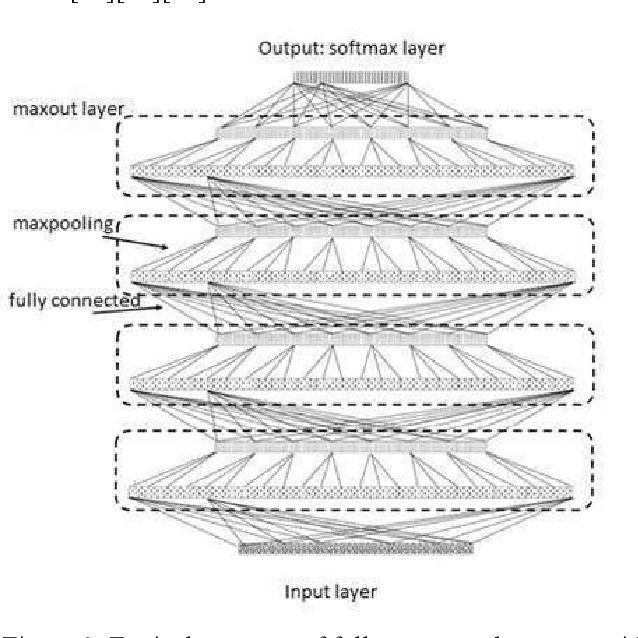
In this paper, various structures and methods of Deep Artificial Neural Networks (DNN) will be evaluated and compared for the purpose of continuous Persian speech recognition. One of the first models of neural networks used in speech recognition applications were fully connected Neural Networks (FCNNs) and, consequently, Deep Neural Networks (DNNs). Although these models have better performance compared to GMM / HMM models, they do not have the proper structure to model local speech information. Convolutional Neural Network (CNN) is a good option for modeling the local structure of biological signals, including speech signals. Another issue that Deep Artificial Neural Networks face, is the convergence of networks on training data. The main inhibitor of convergence is the presence of local minima in the process of training. Deep Neural Network Pre-training methods, despite a large amount of computing, are powerful tools for crossing the local minima. But the use of appropriate neuronal models in the network structure seems to be a better solution to this problem. The Rectified Linear Unit neuronal model and the Maxout model are the most suitable neuronal models presented to this date. Several experiments were carried out to evaluate the performance of the methods and structures mentioned. After verifying the proper functioning of these methods, a combination of all models was implemented on FARSDAT speech database for continuous speech recognition. The results obtained from the experiments show that the combined model (CMDNN) improves the performance of ANNs in speech recognition versus the pre-trained fully connected NNs with sigmoid neurons by about 3%.
* 6 pages, 2 figures, conference paper submitted to 2018 25th National and 3rd International Iranian Conference on Biomedical Engineering (ICBME)